 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQwen2 Technical Report
Paper and Code
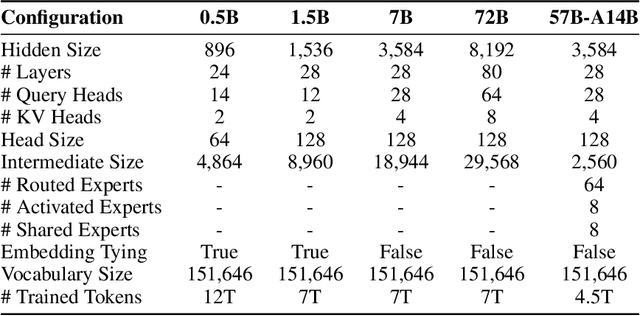
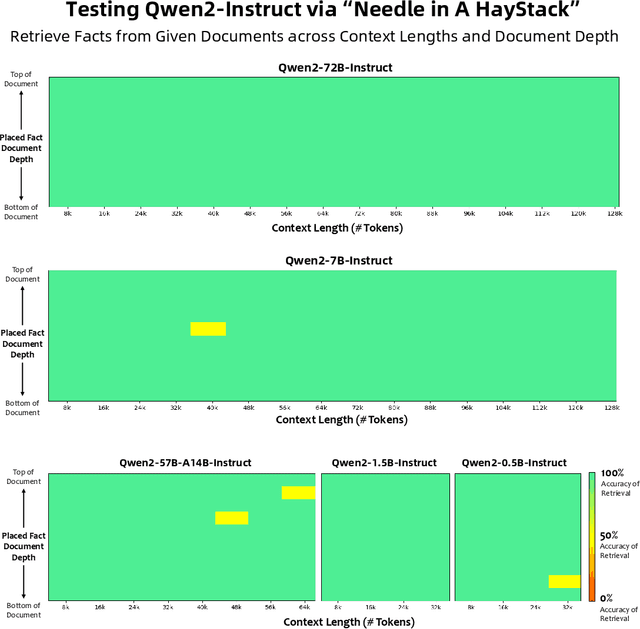
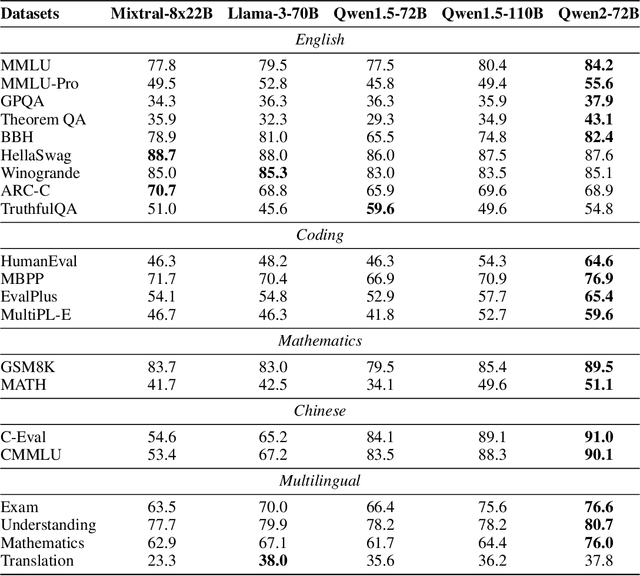
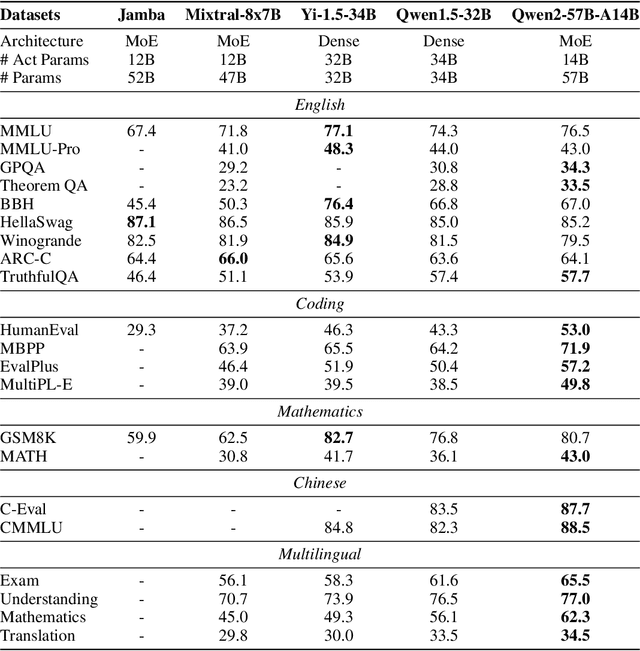
This report introduces the Qwen2 series, the latest addition to our large language models and large multimodal models. We release a comprehensive suite of foundational and instruction-tuned language models, encompassing a parameter range from 0.5 to 72 billion, featuring dense models and a Mixture-of-Experts model. Qwen2 surpasses most prior open-weight models, including its predecessor Qwen1.5, and exhibits competitive performance relative to proprietary models across diverse benchmarks on language understanding, generation, multilingual proficiency, coding, mathematics, and reasoning. The flagship model, Qwen2-72B, showcases remarkable performance: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model. The instruction-tuned variant, Qwen2-72B-Instruct, attains 9.1 on MT-Bench, 48.1 on Arena-Hard, and 35.7 on LiveCodeBench. Moreover, Qwen2 demonstrates robust multilingual capabilities, proficient in approximately 30 languages, spanning English, Chinese, Spanish, French, German, Arabic, Russian, Korean, Japanese, Thai, Vietnamese, and more, underscoring its versatility and global reach. To foster community innovation and accessibility, we have made the Qwen2 model weights openly available on Hugging Face and ModelScope, and the supplementary materials including example code on GitHub. These platforms also include resources for quantization, fine-tuning, and deployment, facilitating a wide range of applications and research endeavors.