 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEDCO: Dynamic Curriculum Orchestration for Domain-specific Large Language Model Fine-tuning
Jan 07, 2026Domain-specific large language models (LLMs), typically developed by fine-tuning a pre-trained general-purpose LLM on specialized datasets, represent a significant advancement in applied AI. A common strategy in LLM fine-tuning is curriculum learning, which pre-orders training samples based on metrics like difficulty to improve learning efficiency compared to a random sampling strategy. However, most existing methods for LLM fine-tuning rely on a static curriculum, designed prior to training, which lacks adaptability to the model's evolving needs during fine-tuning. To address this, we propose EDCO, a novel framework based on two key concepts: inference entropy and dynamic curriculum orchestration. Inspired by recent findings that maintaining high answer entropy benefits long-term reasoning gains, EDCO prioritizes samples with high inference entropy in a continuously adapted curriculum. EDCO integrates three core components: an efficient entropy estimator that uses prefix tokens to approximate full-sequence entropy, an entropy-based curriculum generator that selects data points with the highest inference entropy, and an LLM trainer that optimizes the model on the selected curriculum. Comprehensive experiments in communication, medicine and law domains, EDCO outperforms traditional curriculum strategies for fine-tuning Qwen3-4B and Llama3.2-3B models under supervised and reinforcement learning settings. Furthermore, the proposed efficient entropy estimation reduces computational time by 83.5% while maintaining high accuracy.
Video Detective: Seek Critical Clues Recurrently to Answer Question from Long Videos
Dec 19, 2025Long Video Question-Answering (LVQA) presents a significant challenge for Multi-modal Large Language Models (MLLMs) due to immense context and overloaded information, which could also lead to prohibitive memory consumption. While existing methods attempt to address these issues by reducing visual tokens or extending model's context length, they may miss useful information or take considerable computation. In fact, when answering given questions, only a small amount of crucial information is required. Therefore, we propose an efficient question-aware memory mechanism, enabling MLLMs to recurrently seek these critical clues. Our approach, named VideoDetective, simplifies this task by iteratively processing video sub-segments. For each sub-segment, a question-aware compression strategy is employed by introducing a few special memory tokens to achieve purposefully compression. This allows models to effectively seek critical clues while reducing visual tokens. Then, due to history context could have a significant impact, we recurrently aggregate and store these memory tokens to update history context, which would be reused for subsequent sub-segments. Furthermore, to more effectively measure model's long video understanding ability, we introduce GLVC (Grounding Long Video Clues), a long video question-answering dataset, which features grounding critical and concrete clues scattered throughout entire videos. Experimental results demonstrate our method enables MLLMs with limited context length of 32K to efficiently process 100K tokens (3600 frames, an hour-long video sampled at 1fps), requiring only 2 minutes and 37GB GPU memory usage. Evaluation results across multiple long video benchmarks illustrate our method can more effectively seek critical clues from massive information.
Investigating Data Pruning for Pretraining Biological Foundation Models at Scale
Dec 15, 2025Biological foundation models (BioFMs), pretrained on large-scale biological sequences, have recently shown strong potential in providing meaningful representations for diverse downstream bioinformatics tasks. However, such models often rely on millions to billions of training sequences and billions of parameters, resulting in prohibitive computational costs and significant barriers to reproducibility and accessibility, particularly for academic labs. To address these challenges, we investigate the feasibility of data pruning for BioFM pretraining and propose a post-hoc influence-guided data pruning framework tailored to biological domains. Our approach introduces a subset-based self-influence formulation that enables efficient estimation of sample importance at low computational cost, and builds upon it two simple yet effective selection strategies, namely Top-k Influence (Top I) and Coverage-Centric Influence (CCI). We empirically validate our method on two representative BioFMs, RNA-FM and ESM-C. For RNA, our framework consistently outperforms random selection baselines under an extreme pruning rate of over 99 percent, demonstrating its effectiveness. Furthermore, we show the generalizability of our framework on protein-related tasks using ESM-C. In particular, our coreset even outperforms random subsets that are ten times larger in both RNA and protein settings, revealing substantial redundancy in biological sequence datasets. These findings underscore the potential of influence-guided data pruning to substantially reduce the computational cost of BioFM pretraining, paving the way for more efficient, accessible, and sustainable biological AI research.
MolGA: Molecular Graph Adaptation with Pre-trained 2D Graph Encoder
Oct 08, 2025Molecular graph representation learning is widely used in chemical and biomedical research. While pre-trained 2D graph encoders have demonstrated strong performance, they overlook the rich molecular domain knowledge associated with submolecular instances (atoms and bonds). While molecular pre-training approaches incorporate such knowledge into their pre-training objectives, they typically employ designs tailored to a specific type of knowledge, lacking the flexibility to integrate diverse knowledge present in molecules. Hence, reusing widely available and well-validated pre-trained 2D encoders, while incorporating molecular domain knowledge during downstream adaptation, offers a more practical alternative. In this work, we propose MolGA, which adapts pre-trained 2D graph encoders to downstream molecular applications by flexibly incorporating diverse molecular domain knowledge. First, we propose a molecular alignment strategy that bridge the gap between pre-trained topological representations with domain-knowledge representations. Second, we introduce a conditional adaptation mechanism that generates instance-specific tokens to enable fine-grained integration of molecular domain knowledge for downstream tasks. Finally, we conduct extensive experiments on eleven public datasets, demonstrating the effectiveness of MolGA.
Feeling Machines: Ethics, Culture, and the Rise of Emotional AI
Jun 14, 2025This paper explores the growing presence of emotionally responsive artificial intelligence through a critical and interdisciplinary lens. Bringing together the voices of early-career researchers from multiple fields, it explores how AI systems that simulate or interpret human emotions are reshaping our interactions in areas such as education, healthcare, mental health, caregiving, and digital life. The analysis is structured around four central themes: the ethical implications of emotional AI, the cultural dynamics of human-machine interaction, the risks and opportunities for vulnerable populations, and the emerging regulatory, design, and technical considerations. The authors highlight the potential of affective AI to support mental well-being, enhance learning, and reduce loneliness, as well as the risks of emotional manipulation, over-reliance, misrepresentation, and cultural bias. Key challenges include simulating empathy without genuine understanding, encoding dominant sociocultural norms into AI systems, and insufficient safeguards for individuals in sensitive or high-risk contexts. Special attention is given to children, elderly users, and individuals with mental health challenges, who may interact with AI in emotionally significant ways. However, there remains a lack of cognitive or legal protections which are necessary to navigate such engagements safely. The report concludes with ten recommendations, including the need for transparency, certification frameworks, region-specific fine-tuning, human oversight, and longitudinal research. A curated supplementary section provides practical tools, models, and datasets to support further work in this domain.
Rationales Are Not Silver Bullets: Measuring the Impact of Rationales on Model Performance and Reliability
May 30, 2025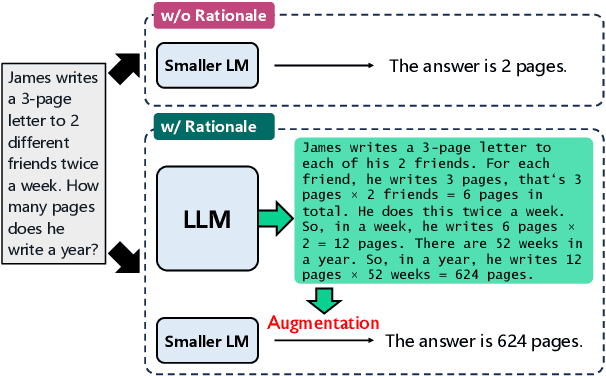
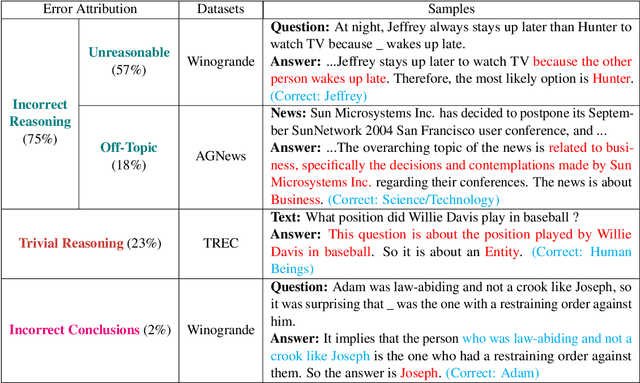
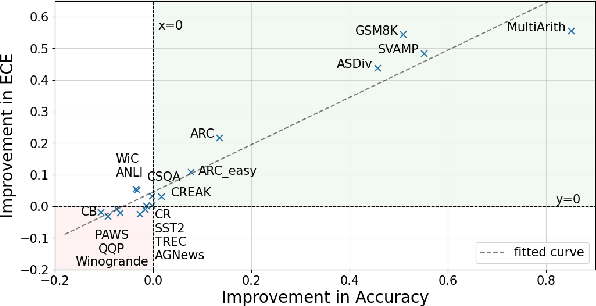

Training language models with rationales augmentation has been shown to be beneficial in many existing works. In this paper, we identify that such a prevailing view does not hold consistently. We conduct comprehensive investigations to thoroughly inspect the impact of rationales on model performance as well as a novel perspective of model reliability. The results lead to several key findings that add new insights upon existing understandings: 1) Rationales can, at times, deteriorate model performance; 2) Rationales can, at times, improve model reliability, even outperforming their untrained counterparts; 3) A linear correspondence exists in between the performance and reliability improvements, while both are driven by the intrinsic difficulty of the task. These findings provide informative regulations on the broad utilization of rationales and raise critical implications on the procedure of explicitly aligning language models with implicit human thoughts. Codes can be found at https://github.com/Ignoramus0817/rationales.
Crab: A Unified Audio-Visual Scene Understanding Model with Explicit Cooperation
Mar 17, 2025In recent years, numerous tasks have been proposed to encourage model to develop specified capability in understanding audio-visual scene, primarily categorized into temporal localization, spatial localization, spatio-temporal reasoning, and pixel-level understanding. Instead, human possesses a unified understanding ability for diversified tasks. Therefore, designing an audio-visual model with general capability to unify these tasks is of great value. However, simply joint training for all tasks can lead to interference due to the heterogeneity of audiovisual data and complex relationship among tasks. We argue that this problem can be solved through explicit cooperation among tasks. To achieve this goal, we propose a unified learning method which achieves explicit inter-task cooperation from both the perspectives of data and model thoroughly. Specifically, considering the labels of existing datasets are simple words, we carefully refine these datasets and construct an Audio-Visual Unified Instruction-tuning dataset with Explicit reasoning process (AV-UIE), which clarifies the cooperative relationship among tasks. Subsequently, to facilitate concrete cooperation in learning stage, an interaction-aware LoRA structure with multiple LoRA heads is designed to learn different aspects of audiovisual data interaction. By unifying the explicit cooperation across the data and model aspect, our method not only surpasses existing unified audio-visual model on multiple tasks, but also outperforms most specialized models for certain tasks. Furthermore, we also visualize the process of explicit cooperation and surprisingly find that each LoRA head has certain audio-visual understanding ability. Code and dataset: https://github.com/GeWu-Lab/Crab
GCoT: Chain-of-Thought Prompt Learning for Graphs
Feb 12, 2025Chain-of-thought (CoT) prompting has achieved remarkable success in natural language processing (NLP). However, its vast potential remains largely unexplored for graphs. This raises an interesting question: How can we design CoT prompting for graphs to guide graph models to learn step by step? On one hand, unlike natural languages, graphs are non-linear and characterized by complex topological structures. On the other hand, many graphs lack textual data, making it difficult to formulate language-based CoT prompting. In this work, we propose the first CoT prompt learning framework for text-free graphs, GCoT. Specifically, we decompose the adaptation process for each downstream task into a series of inference steps, with each step consisting of prompt-based inference, ``thought'' generation, and thought-conditioned prompt learning. While the steps mimic CoT prompting in NLP, the exact mechanism differs significantly. Specifically, at each step, an input graph, along with a prompt, is first fed into a pre-trained graph encoder for prompt-based inference. We then aggregate the hidden layers of the encoder to construct a ``thought'', which captures the working state of each node in the current step. Conditioned on this thought, we learn a prompt specific to each node based on the current state. These prompts are fed into the next inference step, repeating the cycle. To evaluate and analyze the effectiveness of GCoT, we conduct comprehensive experiments on eight public datasets, which demonstrate the advantage of our approach.
SAMGPT: Text-free Graph Foundation Model for Multi-domain Pre-training and Cross-domain Adaptation
Feb 08, 2025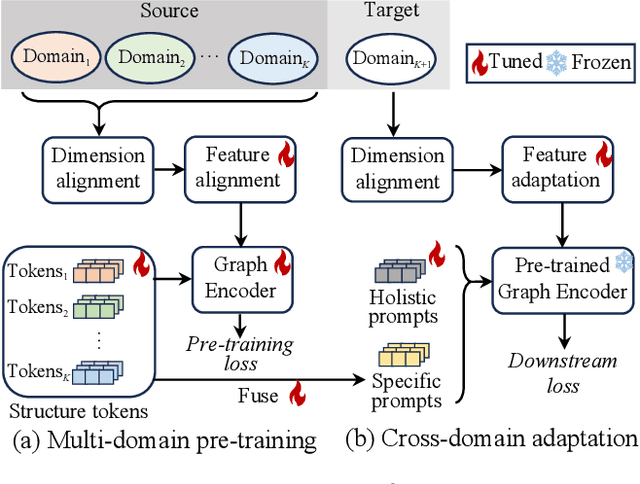
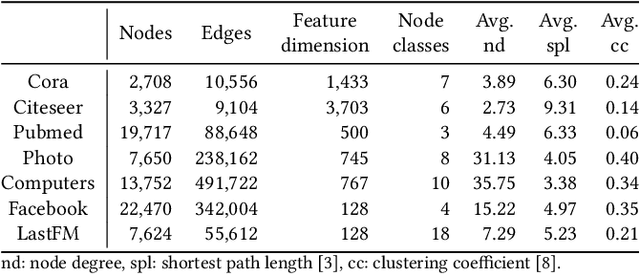
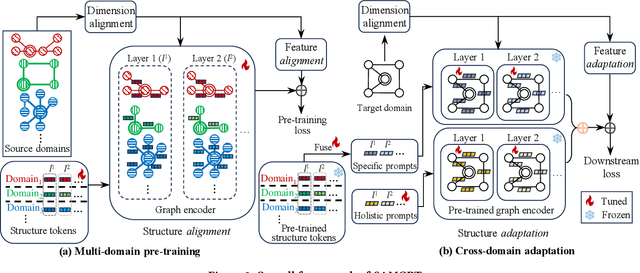
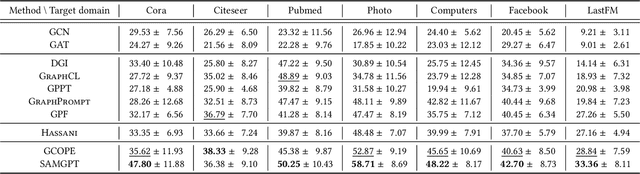
Graphs are able to model interconnected entities in many online services, supporting a wide range of applications on the Web. This raises an important question: How can we train a graph foundational model on multiple source domains and adapt to an unseen target domain? A major obstacle is that graphs from different domains often exhibit divergent characteristics. Some studies leverage large language models to align multiple domains based on textual descriptions associated with the graphs, limiting their applicability to text-attributed graphs. For text-free graphs, a few recent works attempt to align different feature distributions across domains, while generally neglecting structural differences. In this work, we propose a novel Structure Alignment framework for text-free Multi-domain Graph Pre-Training and cross-domain adaptation (SAMGPT). It is designed to learn multi-domain knowledge from graphs originating in multiple source domains, which can then be adapted to address applications in an unseen target domain. Specifically, we introduce a set of structure tokens to harmonize structure-based aggregation across source domains during the pre-training phase. Next, for cross-domain adaptation, we design dual prompts, namely, holistic prompts and specific prompts, which adapt unified multi-domain structural knowledge and fine-grained, domain-specific information, respectively, to a target domain. Finally, we conduct comprehensive experiments on seven public datasets to evaluate and analyze the effectiveness of SAMGPT.
Dynamic Optimization of Storage Systems Using Reinforcement Learning Techniques
Dec 29, 2024



The exponential growth of data-intensive applications has placed unprecedented demands on modern storage systems, necessitating dynamic and efficient optimization strategies. Traditional heuristics employed for storage performance optimization often fail to adapt to the variability and complexity of contemporary workloads, leading to significant performance bottlenecks and resource inefficiencies. To address these challenges, this paper introduces RL-Storage, a novel reinforcement learning (RL)-based framework designed to dynamically optimize storage system configurations. RL-Storage leverages deep Q-learning algorithms to continuously learn from real-time I/O patterns and predict optimal storage parameters, such as cache size, queue depths, and readahead settings[1]. The proposed framework operates within the storage kernel, ensuring minimal latency and low computational overhead. Through an adaptive feedback mechanism, RL-Storage dynamically adjusts critical parameters, achieving efficient resource utilization across a wide range of workloads. Experimental evaluations conducted on a range of benchmarks, including RocksDB and PostgreSQL, demonstrate significant improvements, with throughput gains of up to 2.6x and latency reductions of 43% compared to baseline heuristics. Additionally, RL-Storage achieves these performance enhancements with a negligible CPU overhead of 0.11% and a memory footprint of only 5 KB, making it suitable for seamless deployment in production environments. This work underscores the transformative potential of reinforcement learning techniques in addressing the dynamic nature of modern storage systems. By autonomously adapting to workload variations in real time, RL-Storage provides a robust and scalable solution for optimizing storage performance, paving the way for next-generation intelligent storage infrastructures.