 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObjSplat: Geometry-Aware Gaussian Surfels for Active Object Reconstruction
Jan 11, 2026Autonomous high-fidelity object reconstruction is fundamental for creating digital assets and bridging the simulation-to-reality gap in robotics. We present ObjSplat, an active reconstruction framework that leverages Gaussian surfels as a unified representation to progressively reconstruct unknown objects with both photorealistic appearance and accurate geometry. Addressing the limitations of conventional opacity or depth-based cues, we introduce a geometry-aware viewpoint evaluation pipeline that explicitly models back-face visibility and occlusion-aware multi-view covisibility, reliably identifying under-reconstructed regions even on geometrically complex objects. Furthermore, to overcome the limitations of greedy planning strategies, ObjSplat employs a next-best-path (NBP) planner that performs multi-step lookahead on a dynamically constructed spatial graph. By jointly optimizing information gain and movement cost, this planner generates globally efficient trajectories. Extensive experiments in simulation and on real-world cultural artifacts demonstrate that ObjSplat produces physically consistent models within minutes, achieving superior reconstruction fidelity and surface completeness while significantly reducing scan time and path length compared to state-of-the-art approaches. Project page: https://li-yuetao.github.io/ObjSplat-page/ .
CAR-LOAM: Color-Assisted Robust LiDAR Odometry and Mapping
Feb 24, 2025



In this letter, we propose a color-assisted robust framework for accurate LiDAR odometry and mapping (LOAM). Simultaneously receiving data from both the LiDAR and the camera, the framework utilizes the color information from the camera images to colorize the LiDAR point clouds and then performs iterative pose optimization. For each LiDAR scan, the edge and planar features are extracted and colored using the corresponding image and then matched to a global map. Specifically, we adopt a perceptually uniform color difference weighting strategy to exclude color correspondence outliers and a robust error metric based on the Welsch's function to mitigate the impact of positional correspondence outliers during the pose optimization process. As a result, the system achieves accurate localization and reconstructs dense, accurate, colored and three-dimensional (3D) maps of the environment. Thorough experiments with challenging scenarios, including complex forests and a campus, show that our method provides higher robustness and accuracy compared with current state-of-the-art methods.
PB-NBV: Efficient Projection-Based Next-Best-View Planning Framework for Reconstruction of Unknown Objects
Jan 18, 2025



Completely capturing the three-dimensional (3D) data of an object is essential in industrial and robotic applications. The task of next-best-view (NBV) planning is to calculate the next optimal viewpoint based on the current data, gradually achieving a complete 3D reconstruction of the object. However, many existing NBV planning algorithms incur heavy computational costs due to the extensive use of ray-casting. Specifically, this framework refits different types of voxel clusters into ellipsoids based on the voxel structure. Then, the next optimal viewpoint is selected from the candidate views using a projection-based viewpoint quality evaluation function in conjunction with a global partitioning strategy. This process replaces extensive ray-casting, significantly improving the computational efficiency. Comparison experiments in the simulation environment show that our framework achieves the highest point cloud coverage with low computational time compared to other frameworks. The real-world experiments also confirm the efficiency and feasibility of the framework. Our method will be made open source to benefit the community.
An Efficient Projection-Based Next-best-view Planning Framework for Reconstruction of Unknown Objects
Sep 18, 2024



Efficiently and completely capturing the three-dimensional data of an object is a fundamental problem in industrial and robotic applications. The task of next-best-view (NBV) planning is to infer the pose of the next viewpoint based on the current data, and gradually realize the complete three-dimensional reconstruction. Many existing algorithms, however, suffer a large computational burden due to the use of ray-casting. To address this, this paper proposes a projection-based NBV planning framework. It can select the next best view at an extremely fast speed while ensuring the complete scanning of the object. Specifically, this framework refits different types of voxel clusters into ellipsoids based on the voxel structure.Then, the next best view is selected from the candidate views using a projection-based viewpoint quality evaluation function in conjunction with a global partitioning strategy. This process replaces the ray-casting in voxel structures, significantly improving the computational efficiency. Comparative experiments with other algorithms in a simulation environment show that the framework proposed in this paper can achieve 10 times efficiency improvement on the basis of capturing roughly the same coverage. The real-world experimental results also prove the efficiency and feasibility of the framework.
Batch-FPM: Random batch-update multi-parameter physical Fourier ptychography neural network
Aug 25, 2024
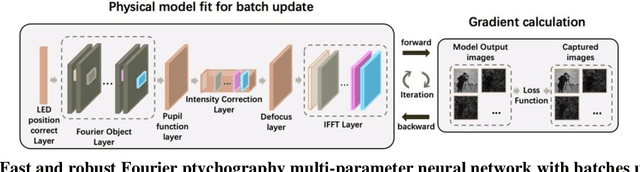


Fourier Ptychographic Microscopy (FPM) is a computational imaging technique that enables high-resolution imaging over a large field of view. However, its application in the biomedical field has been limited due to the long image reconstruction time and poor noise robustness. In this paper, we propose a fast and robust FPM reconstruction method based on physical neural networks with batch update stochastic gradient descent (SGD) optimization strategy, capable of achieving attractive results with low single-to-noise ratio and correcting multiple system parameters simultaneously. Our method leverages a random batch optimization approach, breaks away from the fixed sequential iterative order and gives greater attention to high-frequency information. The proposed method has better convergence performance even for low signal-to-noise ratio data sets, such as low exposure time dark-field images. As a result, it can greatly increase the image recording and result reconstruction speed without any additional hardware modifications. By utilizing advanced deep learning optimizers and perform parallel computational scheme, our method enhances GPU computational efficiency, significantly reducing reconstruction costs. Experimental results demonstrate that our method achieves near real-time digital refocusing of a 1024 x 1024 pixels region of interest on consumer-grade GPUs. This approach significantly improves temporal resolution (by reducing the exposure time of dark-field images), noise resistance, and reconstruction speed, and therefore can efficiently promote the practical application of FPM in clinical diagnostics, digital pathology, and biomedical research, etc. In addition, we believe our algorithm scheme can help researchers quickly validate and implement FPM-related ideas. We invite requests for the full code via email.
Panoramic single-pixel imaging with megapixel resolution based on rotational subdivision
Jul 27, 2024Single-pixel imaging (SPI) using a single-pixel detector is an unconventional imaging method, which has great application prospects in many fields to realize high-performance imaging. In especial, the recent proposed catadioptric panoramic ghost imaging (CPGI) extends the application potential of SPI to high-performance imaging at a wide field of view (FOV) with recent growing demands. However, the resolution of CPGI is limited by hardware parameters of the digital micromirror device (DMD), which may not meet ultrahigh-resolution panoramic imaging needs that require detailed information. Therefore, to overcome the resolution limitation of CPGI, we propose a panoramic SPI based on rotational subdivision (RSPSI). The key of the proposed RSPSI is to obtain the entire panoramic scene by the rotation-scanning with a rotating mirror tilted 45{\deg}, so that one single pattern that only covers one sub-Fov with a small FOV can complete a uninterrupted modulation on the entire panoramic FOV during a once-through pattern projection. Then, based on temporal resolution subdivision, images sequence of sub-Fovs subdivided from the entire panoramic FOV can be reconstructed with pixels-level or even subpixels-level horizontal shifting adjacently. Experimental results using a proof-of-concept setup show that the panoramic image can be obtained with 10428*543 of 5,662,404 pixels, which is more than 9.6 times higher than the resolution limit of the CPGI using the same DMD. To our best knowledge, the RSPSI is the first to achieve a megapixel resolution via SPI, which can provide potential applications in fields requiring the imaging with ultrahigh-resolution and wide FOV.
Improved Dense Nested Attention Network Based on Transformer for Infrared Small Target Detection
Nov 15, 2023



Infrared small target detection based on deep learning offers unique advantages in separating small targets from complex and dynamic backgrounds. However, the features of infrared small targets gradually weaken as the depth of convolutional neural network (CNN) increases. To address this issue, we propose a novel method for detecting infrared small targets called improved dense nested attention network (IDNANet), which is based on the transformer architecture. We preserve the dense nested structure of dense nested attention network (DNANet) and introduce the Swin-transformer during feature extraction stage to enhance the continuity of features. Furthermore, we integrate the ACmix attention structure into the dense nested structure to enhance the features of intermediate layers. Additionally, we design a weighted dice binary cross-entropy (WD-BCE) loss function to mitigate the negative impact of foreground-background imbalance in the samples. Moreover, we develop a dataset specifically for infrared small targets, called BIT-SIRST. The dataset comprises a significant amount of real-world targets and manually annotated labels, as well as synthetic data and corresponding labels. We have evaluated the effectiveness of our method through experiments conducted on public datasets. In comparison to other state-of-the-art methods, our approach outperforms in terms of probability of detection (P_d), false-alarm rate (F_a), and mean intersection of union ($mIoU$). The $mIoU$ reaches 90.89 on the NUDT-SIRST dataset and 79.72 on the NUAA-SIRST dataset.
Flexible uniform-sampling foveated Fourier single-pixel imaging
Nov 05, 2023Fourier single-pixel imaging (FSI) is a data-efficient single-pixel imaging (SPI). However, there is still a serious challenge to obtain higher imaging quality using fewer measurements, which limits the development of real-time SPI. In this work, a uniform-sampling foveated FSI (UFFSI) is proposed with three features, uniform sampling, effective sampling and flexible fovea, to achieve under-sampling high-efficiency and high-quality SPI, even in a large-scale scene. First, by flexibly using the three proposed foveated pattern structures, data redundancy is reduced significantly to only require high resolution (HR) on regions of interest (ROIs), which radically reduces the need of total data number. Next, by the non-uniform weight distribution processing, non-uniform spatial sampling is transformed into uniform sampling, then the fast Fourier transform is used accurately and directly to obtain under-sampling high imaging quality with further reduced measurements. At a sampling ratio of 0.0084 referring to HR FSI with 1024*768 pixels, experimentally, by UFFSI with 255*341 cells of 89% reduction in data redundancy, the ROI has a significantly better imaging quality to meet imaging needs. We hope this work can provide a breakthrough for future real-time SPI.
Adaptive coded illumination Fourier ptychography microscopy based on physical neural network
Apr 20, 2023



Fourier Ptychographic Microscopy (FPM) is a computational technique that achieves a large space-bandwidth product imaging. It addresses the challenge of balancing a large field of view and high resolution by fusing information from multiple images taken with varying illumination angles. Nevertheless, conventional FPM framework always suffers from long acquisition time and a heavy computational burden. In this paper, we propose a novel physical neural network that generates an adaptive illumination mode by incorporating temporally-encoded illumination modes as a distinct layer, aiming to improve the acquisition and calculation efficiency. Both simulations and experiments have been conducted to validate the feasibility and effectiveness of the proposed method. It is worth mentioning that, unlike previous works that obtain the intensity of a multiplexed illumination by post-combination of each sequentially illuminated and obtained low-resolution images, our experimental data is captured directly by turning on multiple LEDs with a coded illumination pattern. Our method has exhibited state-of-the-art performance in terms of both detail fidelity and imaging velocity when assessed through a multitude of evaluative aspects.
Anti-scattering medium computational ghost imaging with modified Hadamard patterns
Apr 15, 2023



Illumination patterns of computational ghost imaging (CGI) systems suffer from reduced contrast when passing through a scattering medium, which causes the effective information in the reconstruction result to be drowned out by noise. A two-dimensional (2D) Gaussian filter performs linear smoothing operation on the whole image for image denoising. It can be combined with linear reconstruction algorithms of CGI to obtain the noise-reduced results directly, without post-processing. However, it results in blurred image edges while performing denoising and, in addition, a suitable standard deviation is difficult to choose in advance, especially in an unknown scattering environment. In this work, we subtly exploit the characteristics of CGI to solve these two problems very well. A kind of modified Hadamard pattern based on the 2D Gaussian filter and the differential operation features of Hadamard-based CGI is developed. We analyze and demonstrate that using Hadamard patterns for illumination but using our developed modified Hadamard patterns for reconstruction (MHCGI) can enhance the robustness of CGI against turbid scattering medium. Our method not only helps directly obtain noise-reduced results without blurred edges but also requires only an approximate standard deviation, i.e., it can be set in advance. The experimental results on transmitted and reflected targets demonstrate the feasibility of our method. Our method helps to promote the practical application of CGI in the scattering environment.