 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Event-Based Video Reconstruction with Motion Compensation
Mar 18, 2024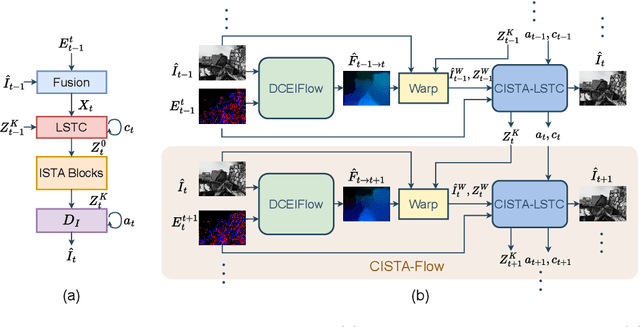
Deep neural networks for event-based video reconstruction often suffer from a lack of interpretability and have high memory demands. A lightweight network called CISTA-LSTC has recently been introduced showing that high-quality reconstruction can be achieved through the systematic design of its architecture. However, its modelling assumption that input signals and output reconstructed frame share the same sparse representation neglects the displacement caused by motion. To address this, we propose warping the input intensity frames and sparse codes to enhance reconstruction quality. A CISTA-Flow network is constructed by integrating a flow network with CISTA-LSTC for motion compensation. The system relies solely on events, in which predicted flow aids in reconstruction and then reconstructed frames are used to facilitate flow estimation. We also introduce an iterative training framework for this combined system. Results demonstrate that our approach achieves state-of-the-art reconstruction accuracy and simultaneously provides reliable dense flow estimation. Furthermore, our model exhibits flexibility in that it can integrate different flow networks, suggesting its potential for further performance enhancement.
Single-shot quantitative differential phase contrast imaging combined with programmable polarization multiplexing illumination
Apr 13, 2023

We propose a single-shot quantitative differential phase contrast (DPC) method with polarization multiplexing illumination. In the illumination module of our system, the programmable LED array is divided into four quadrants and covered with polarizing films of four different polarization angles. We use a polarization camera with polarizers before the pixels in the imaging module. By matching the polarization angle between the polarizing films over the custom LED array and the polarizers in the camera, two sets of asymmetric illumination acquisition images can be calculated from a single-shot acquisition image. Combined with the phase transfer function, we can calculate the quantitative phase of the sample. We present the design, implementation, and experimental image data demonstrating the ability of our method to obtain quantitative phase images of the phase resolution target, as well as Hela cells.
Distance Based Image Classification: A solution to generative classification's conundrum?
Oct 04, 2022



Most classifiers rely on discriminative boundaries that separate instances of each class from everything else. We argue that discriminative boundaries are counter-intuitive as they define semantics by what-they-are-not; and should be replaced by generative classifiers which define semantics by what-they-are. Unfortunately, generative classifiers are significantly less accurate. This may be caused by the tendency of generative models to focus on easy to model semantic generative factors and ignore non-semantic factors that are important but difficult to model. We propose a new generative model in which semantic factors are accommodated by shell theory's hierarchical generative process and non-semantic factors by an instance specific noise term. We use the model to develop a classification scheme which suppresses the impact of noise while preserving semantic cues. The result is a surprisingly accurate generative classifier, that takes the form of a modified nearest-neighbor algorithm; we term it distance classification. Unlike discriminative classifiers, a distance classifier: defines semantics by what-they-are; is amenable to incremental updates; and scales well with the number of classes.
Dual-SLAM: A framework for robust single camera navigation
Sep 23, 2020



SLAM (Simultaneous Localization And Mapping) seeks to provide a moving agent with real-time self-localization. To achieve real-time speed, SLAM incrementally propagates position estimates. This makes SLAM fast but also makes it vulnerable to local pose estimation failures. As local pose estimation is ill-conditioned, local pose estimation failures happen regularly, making the overall SLAM system brittle. This paper attempts to correct this problem. We note that while local pose estimation is ill-conditioned, pose estimation over longer sequences is well-conditioned. Thus, local pose estimation errors eventually manifest themselves as mapping inconsistencies. When this occurs, we save the current map and activate two new SLAM threads. One processes incoming frames to create a new map and the other, recovery thread, backtracks to link new and old maps together. This creates a Dual-SLAM framework that maintains real-time performance while being robust to local pose estimation failures. Evaluation on benchmark datasets shows Dual-SLAM can reduce failures by a dramatic $88\%$.
Dimensionality's Blessing: Clustering Images by Underlying Distribution
Apr 08, 2018

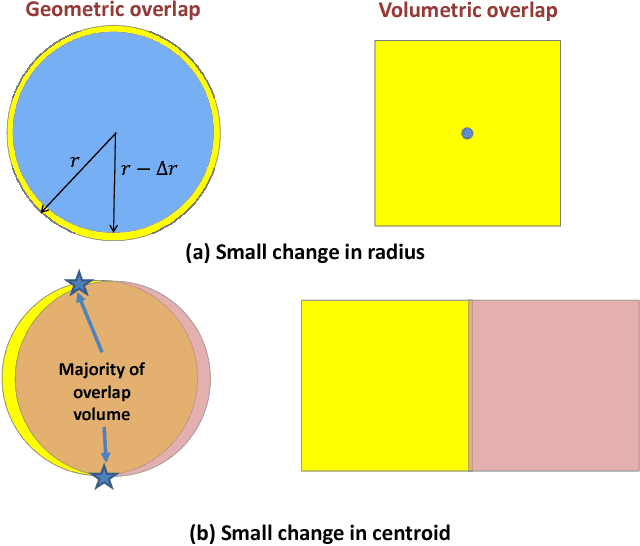
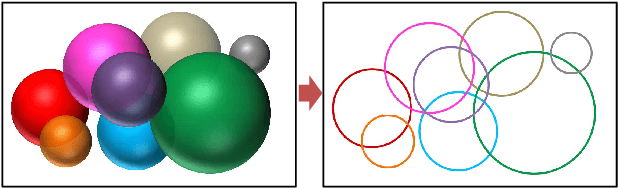
Many high dimensional vector distances tend to a constant. This is typically considered a negative "contrast-loss" phenomenon that hinders clustering and other machine learning techniques. We reinterpret "contrast-loss" as a blessing. Re-deriving "contrast-loss" using the law of large numbers, we show it results in a distribution's instances concentrating on a thin "hyper-shell". The hollow center means apparently chaotically overlapping distributions are actually intrinsically separable. We use this to develop distribution-clustering, an elegant algorithm for grouping of data points by their (unknown) underlying distribution. Distribution-clustering, creates notably clean clusters from raw unlabeled data, estimates the number of clusters for itself and is inherently robust to "outliers" which form their own clusters. This enables trawling for patterns in unorganized data and may be the key to enabling machine intelligence.