 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Unsupervised Outlier Detection via Multiple Thresholding
Jul 07, 2024



In the realm of unsupervised image outlier detection, assigning outlier scores holds greater significance than its subsequent task: thresholding for predicting labels. This is because determining the optimal threshold on non-separable outlier score functions is an ill-posed problem. However, the lack of predicted labels not only hiders some real applications of current outlier detectors but also causes these methods not to be enhanced by leveraging the dataset's self-supervision. To advance existing scoring methods, we propose a multiple thresholding (Multi-T) module. It generates two thresholds that isolate inliers and outliers from the unlabelled target dataset, whereas outliers are employed to obtain better feature representation while inliers provide an uncontaminated manifold. Extensive experiments verify that Multi-T can significantly improve proposed outlier scoring methods. Moreover, Multi-T contributes to a naive distance-based method being state-of-the-art.
Distance Based Image Classification: A solution to generative classification's conundrum?
Oct 04, 2022



Most classifiers rely on discriminative boundaries that separate instances of each class from everything else. We argue that discriminative boundaries are counter-intuitive as they define semantics by what-they-are-not; and should be replaced by generative classifiers which define semantics by what-they-are. Unfortunately, generative classifiers are significantly less accurate. This may be caused by the tendency of generative models to focus on easy to model semantic generative factors and ignore non-semantic factors that are important but difficult to model. We propose a new generative model in which semantic factors are accommodated by shell theory's hierarchical generative process and non-semantic factors by an instance specific noise term. We use the model to develop a classification scheme which suppresses the impact of noise while preserving semantic cues. The result is a surprisingly accurate generative classifier, that takes the form of a modified nearest-neighbor algorithm; we term it distance classification. Unlike discriminative classifiers, a distance classifier: defines semantics by what-they-are; is amenable to incremental updates; and scales well with the number of classes.
Relation Preserving Triplet Mining for Stabilizing the Triplet Loss in Vehicle Re-identification
Oct 15, 2021
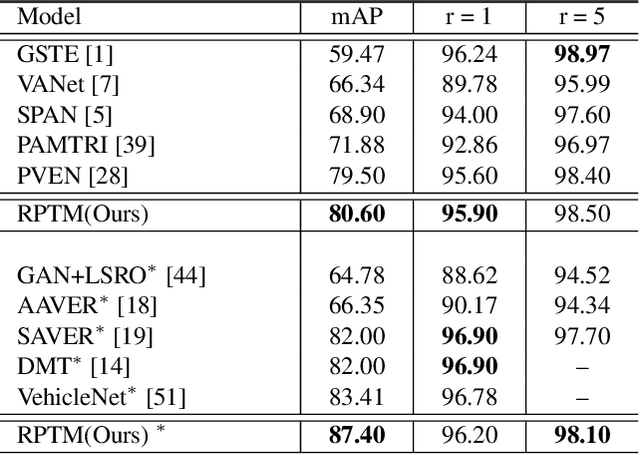
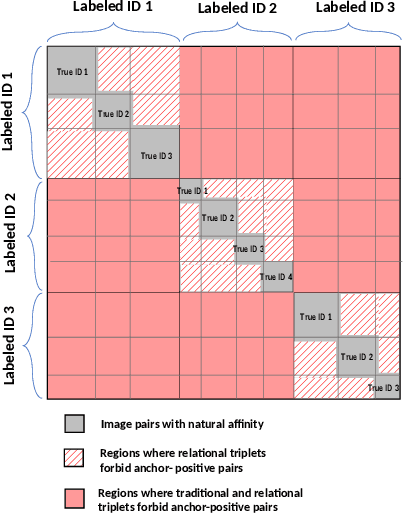

Object appearances often change dramatically with pose variations. This creates a challenge for embedding schemes that seek to map instances with the same object ID to locations that are as close as possible. This issue becomes significantly heightened in complex computer vision tasks such as re-identification(re-id). In this paper, we suggest these dramatic appearance changes are indications that an object ID is composed of multiple natural groups and it is counter-productive to forcefully map instances from different groups to a common location. This leads us to introduce Relation Preserving Triplet Mining (RPTM), a feature matching guided triplet mining scheme, that ensures triplets will respect the natural sub-groupings within an object ID. We use this triplet mining mechanism to establish a pose-aware, well-conditioned triplet cost function. This allows a single network to be trained with fixed parameters across three challenging benchmarks, while still providing state-of-the-art re-identification results.
Enhanced Spatio-Temporal Interaction Learning for Video Deraining: A Faster and Better Framework
Mar 23, 2021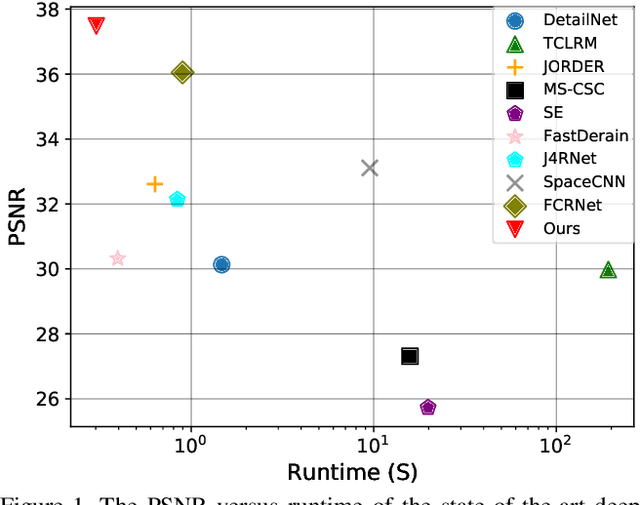


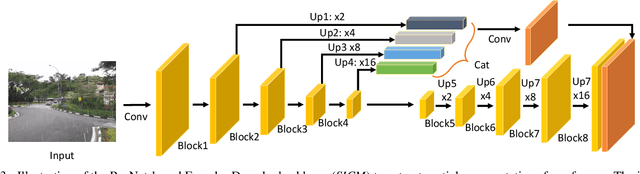
Video deraining is an important task in computer vision as the unwanted rain hampers the visibility of videos and deteriorates the robustness of most outdoor vision systems. Despite the significant success which has been achieved for video deraining recently, two major challenges remain: 1) how to exploit the vast information among continuous frames to extract powerful spatio-temporal features across both the spatial and temporal domains, and 2) how to restore high-quality derained videos with a high-speed approach. In this paper, we present a new end-to-end video deraining framework, named Enhanced Spatio-Temporal Interaction Network (ESTINet), which considerably boosts current state-of-the-art video deraining quality and speed. The ESTINet takes the advantage of deep residual networks and convolutional long short-term memory, which can capture the spatial features and temporal correlations among continuing frames at the cost of very little computational source. Extensive experiments on three public datasets show that the proposed ESTINet can achieve faster speed than the competitors, while maintaining better performance than the state-of-the-art methods.
Dual-SLAM: A framework for robust single camera navigation
Sep 23, 2020



SLAM (Simultaneous Localization And Mapping) seeks to provide a moving agent with real-time self-localization. To achieve real-time speed, SLAM incrementally propagates position estimates. This makes SLAM fast but also makes it vulnerable to local pose estimation failures. As local pose estimation is ill-conditioned, local pose estimation failures happen regularly, making the overall SLAM system brittle. This paper attempts to correct this problem. We note that while local pose estimation is ill-conditioned, pose estimation over longer sequences is well-conditioned. Thus, local pose estimation errors eventually manifest themselves as mapping inconsistencies. When this occurs, we save the current map and activate two new SLAM threads. One processes incoming frames to create a new map and the other, recovery thread, backtracks to link new and old maps together. This creates a Dual-SLAM framework that maintains real-time performance while being robust to local pose estimation failures. Evaluation on benchmark datasets shows Dual-SLAM can reduce failures by a dramatic $88\%$.
Hierarchical Models: Intrinsic Separability in High Dimensions
Mar 15, 2020



It has long been noticed that high dimension data exhibits strange patterns. This has been variously interpreted as either a "blessing" or a "curse", causing uncomfortable inconsistencies in the literature. We propose that these patterns arise from an intrinsically hierarchical generative process. Modeling the process creates a web of constraints that reconcile many different theories and results. The model also implies high dimensional data posses an innate separability that can be exploited for machine learning. We demonstrate how this permits the open-set learning problem to be defined mathematically, leading to qualitative and quantitative improvements in performance.
Image Matching: An Application-oriented Benchmark
Aug 07, 2018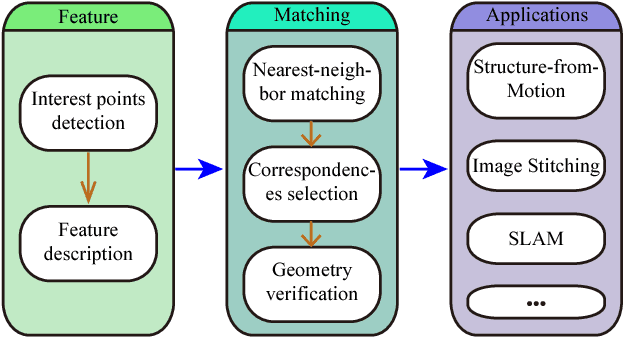
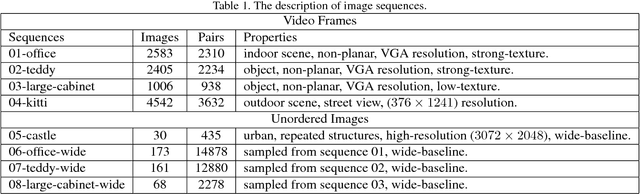

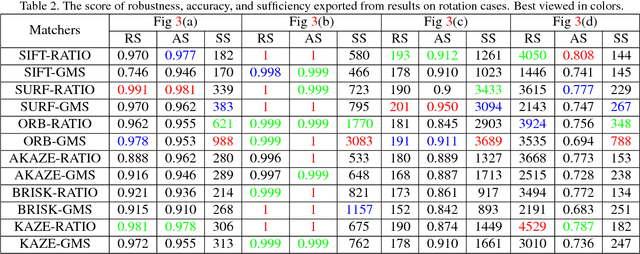
Image matching approaches have been widely used in computer vision applications in which the image-level matching performance of matchers is critical. However, it has not been well investigated by previous works which place more emphases on evaluating local features. To this end, we present a uniform benchmark with novel evaluation metrics and a large-scale dataset for evaluating the overall performance of image matching methods. The proposed metrics are application-oriented as they emphasize application requirements for matchers. The dataset contains two portions for benchmarking video frame matching and unordered image matching separately, where each portion consists of real-world image sequences and each sequence has a specific attribute. Subsequently, we carry out a comprehensive performance evaluation of different state-of-the-art methods and conduct in-depth analyses regarding various aspects such as application requirements, matching types, and data diversity. Moreover, we shed light on how to choose appropriate approaches for different applications based on empirical results and analyses. Conclusions in this benchmark can be used as general guidelines to design practical matching systems and also advocate potential future research directions in this field.
Dimensionality's Blessing: Clustering Images by Underlying Distribution
Apr 08, 2018

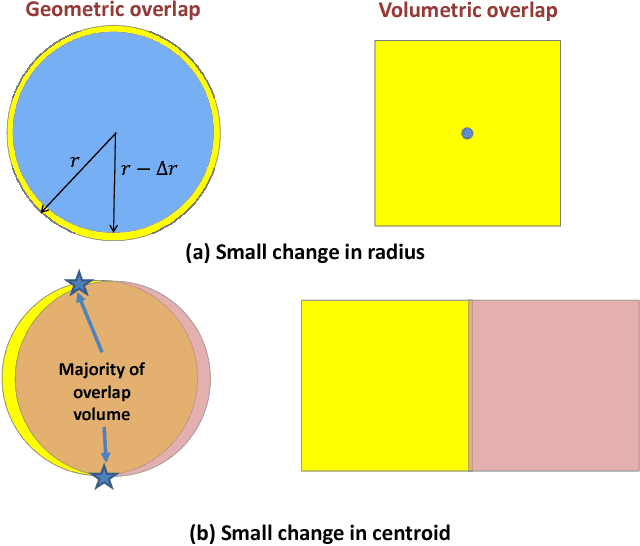
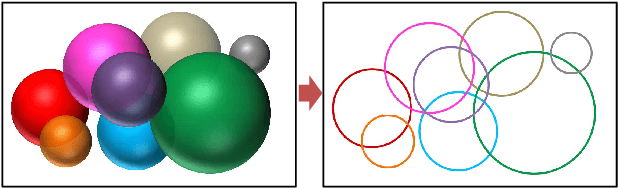
Many high dimensional vector distances tend to a constant. This is typically considered a negative "contrast-loss" phenomenon that hinders clustering and other machine learning techniques. We reinterpret "contrast-loss" as a blessing. Re-deriving "contrast-loss" using the law of large numbers, we show it results in a distribution's instances concentrating on a thin "hyper-shell". The hollow center means apparently chaotically overlapping distributions are actually intrinsically separable. We use this to develop distribution-clustering, an elegant algorithm for grouping of data points by their (unknown) underlying distribution. Distribution-clustering, creates notably clean clusters from raw unlabeled data, estimates the number of clusters for itself and is inherently robust to "outliers" which form their own clusters. This enables trawling for patterns in unorganized data and may be the key to enabling machine intelligence.
ImageSpirit: Verbal Guided Image Parsing
May 21, 2014
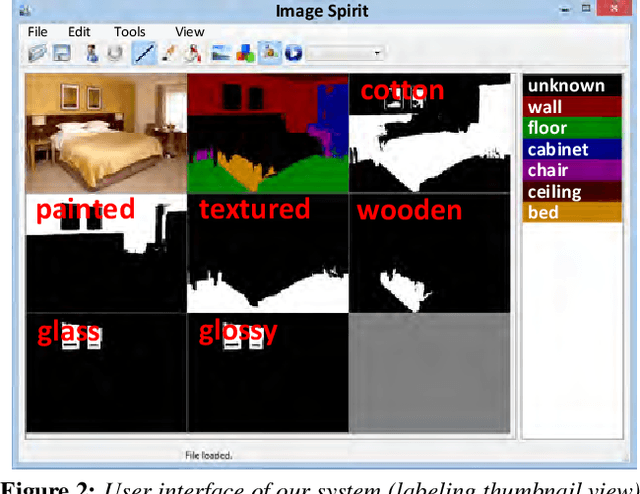
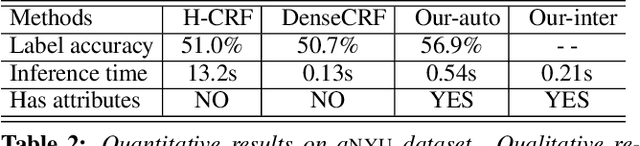
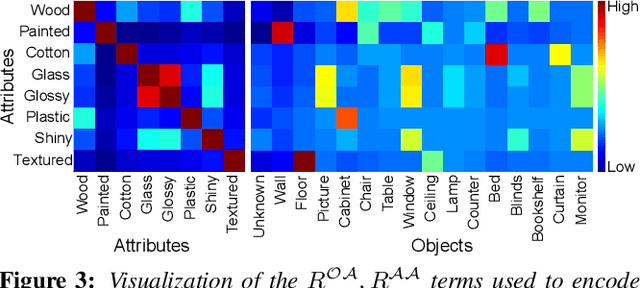
Humans describe images in terms of nouns and adjectives while algorithms operate on images represented as sets of pixels. Bridging this gap between how humans would like to access images versus their typical representation is the goal of image parsing, which involves assigning object and attribute labels to pixel. In this paper we propose treating nouns as object labels and adjectives as visual attribute labels. This allows us to formulate the image parsing problem as one of jointly estimating per-pixel object and attribute labels from a set of training images. We propose an efficient (interactive time) solution. Using the extracted labels as handles, our system empowers a user to verbally refine the results. This enables hands-free parsing of an image into pixel-wise object/attribute labels that correspond to human semantics. Verbally selecting objects of interests enables a novel and natural interaction modality that can possibly be used to interact with new generation devices (e.g. smart phones, Google Glass, living room devices). We demonstrate our system on a large number of real-world images with varying complexity. To help understand the tradeoffs compared to traditional mouse based interactions, results are reported for both a large scale quantitative evaluation and a user study.
* http://mmcheng.net/imagespirit/