 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge360DVO: Deep Visual Odometry for Monocular 360-Degree Camera
Jan 05, 2026Monocular omnidirectional visual odometry (OVO) systems leverage 360-degree cameras to overcome field-of-view limitations of perspective VO systems. However, existing methods, reliant on handcrafted features or photometric objectives, often lack robustness in challenging scenarios, such as aggressive motion and varying illumination. To address this, we present 360DVO, the first deep learning-based OVO framework. Our approach introduces a distortion-aware spherical feature extractor (DAS-Feat) that adaptively learns distortion-resistant features from 360-degree images. These sparse feature patches are then used to establish constraints for effective pose estimation within a novel omnidirectional differentiable bundle adjustment (ODBA) module. To facilitate evaluation in realistic settings, we also contribute a new real-world OVO benchmark. Extensive experiments on this benchmark and public synthetic datasets (TartanAir V2 and 360VO) demonstrate that 360DVO surpasses state-of-the-art baselines (including 360VO and OpenVSLAM), improving robustness by 50% and accuracy by 37.5%. Homepage: https://chris1004336379.github.io/360DVO-homepage
SC-OmniGS: Self-Calibrating Omnidirectional Gaussian Splatting
Feb 07, 2025



360-degree cameras streamline data collection for radiance field 3D reconstruction by capturing comprehensive scene data. However, traditional radiance field methods do not address the specific challenges inherent to 360-degree images. We present SC-OmniGS, a novel self-calibrating omnidirectional Gaussian splatting system for fast and accurate omnidirectional radiance field reconstruction using 360-degree images. Rather than converting 360-degree images to cube maps and performing perspective image calibration, we treat 360-degree images as a whole sphere and derive a mathematical framework that enables direct omnidirectional camera pose calibration accompanied by 3D Gaussians optimization. Furthermore, we introduce a differentiable omnidirectional camera model in order to rectify the distortion of real-world data for performance enhancement. Overall, the omnidirectional camera intrinsic model, extrinsic poses, and 3D Gaussians are jointly optimized by minimizing weighted spherical photometric loss. Extensive experiments have demonstrated that our proposed SC-OmniGS is able to recover a high-quality radiance field from noisy camera poses or even no pose prior in challenging scenarios characterized by wide baselines and non-object-centric configurations. The noticeable performance gain in the real-world dataset captured by consumer-grade omnidirectional cameras verifies the effectiveness of our general omnidirectional camera model in reducing the distortion of 360-degree images.
Localized Gaussian Splatting Editing with Contextual Awareness
Jul 31, 2024



Recent text-guided generation of individual 3D object has achieved great success using diffusion priors. However, these methods are not suitable for object insertion and replacement tasks as they do not consider the background, leading to illumination mismatches within the environment. To bridge the gap, we introduce an illumination-aware 3D scene editing pipeline for 3D Gaussian Splatting (3DGS) representation. Our key observation is that inpainting by the state-of-the-art conditional 2D diffusion model is consistent with background in lighting. To leverage the prior knowledge from the well-trained diffusion models for 3D object generation, our approach employs a coarse-to-fine objection optimization pipeline with inpainted views. In the first coarse step, we achieve image-to-3D lifting given an ideal inpainted view. The process employs 3D-aware diffusion prior from a view-conditioned diffusion model, which preserves illumination present in the conditioning image. To acquire an ideal inpainted image, we introduce an Anchor View Proposal (AVP) algorithm to find a single view that best represents the scene illumination in target region. In the second Texture Enhancement step, we introduce a novel Depth-guided Inpainting Score Distillation Sampling (DI-SDS), which enhances geometry and texture details with the inpainting diffusion prior, beyond the scope of the 3D-aware diffusion prior knowledge in the first coarse step. DI-SDS not only provides fine-grained texture enhancement, but also urges optimization to respect scene lighting. Our approach efficiently achieves local editing with global illumination consistency without explicitly modeling light transport. We demonstrate robustness of our method by evaluating editing in real scenes containing explicit highlight and shadows, and compare against the state-of-the-art text-to-3D editing methods.
360VOTS: Visual Object Tracking and Segmentation in Omnidirectional Videos
Apr 22, 2024Visual object tracking and segmentation in omnidirectional videos are challenging due to the wide field-of-view and large spherical distortion brought by 360{\deg} images. To alleviate these problems, we introduce a novel representation, extended bounding field-of-view (eBFoV), for target localization and use it as the foundation of a general 360 tracking framework which is applicable for both omnidirectional visual object tracking and segmentation tasks. Building upon our previous work on omnidirectional visual object tracking (360VOT), we propose a comprehensive dataset and benchmark that incorporates a new component called omnidirectional video object segmentation (360VOS). The 360VOS dataset includes 290 sequences accompanied by dense pixel-wise masks and covers a broader range of target categories. To support both the development and evaluation of algorithms in this domain, we divide the dataset into a training subset with 170 sequences and a testing subset with 120 sequences. Furthermore, we tailor evaluation metrics for both omnidirectional tracking and segmentation to ensure rigorous assessment. Through extensive experiments, we benchmark state-of-the-art approaches and demonstrate the effectiveness of our proposed 360 tracking framework and training dataset. Homepage: https://360vots.hkustvgd.com/
StyleCity: Large-Scale 3D Urban Scenes Stylization with Vision-and-Text Reference via Progressive Optimization
Apr 16, 2024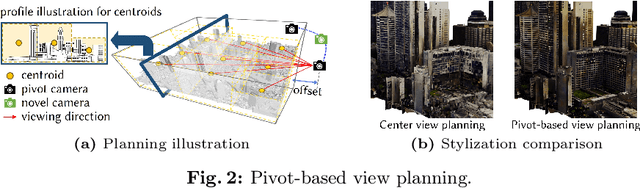



Creating large-scale virtual urban scenes with variant styles is inherently challenging. To facilitate prototypes of virtual production and bypass the need for complex materials and lighting setups, we introduce the first vision-and-text-driven texture stylization system for large-scale urban scenes, StyleCity. Taking an image and text as references, StyleCity stylizes a 3D textured mesh of a large-scale urban scene in a semantics-aware fashion and generates a harmonic omnidirectional sky background. To achieve that, we propose to stylize a neural texture field by transferring 2D vision-and-text priors to 3D globally and locally. During 3D stylization, we progressively scale the planned training views of the input 3D scene at different levels in order to preserve high-quality scene content. We then optimize the scene style globally by adapting the scale of the style image with the scale of the training views. Moreover, we enhance local semantics consistency by the semantics-aware style loss which is crucial for photo-realistic stylization. Besides texture stylization, we further adopt a generative diffusion model to synthesize a style-consistent omnidirectional sky image, which offers a more immersive atmosphere and assists the semantic stylization process. The stylized neural texture field can be baked into an arbitrary-resolution texture, enabling seamless integration into conventional rendering pipelines and significantly easing the virtual production prototyping process. Extensive experiments demonstrate our stylized scenes' superiority in qualitative and quantitative performance and user preferences.
OmniGS: Omnidirectional Gaussian Splatting for Fast Radiance Field Reconstruction using Omnidirectional Images
Apr 08, 2024Photorealistic reconstruction relying on 3D Gaussian Splatting has shown promising potential in robotics. However, the current 3D Gaussian Splatting system only supports radiance field reconstruction using undistorted perspective images. In this paper, we present OmniGS, a novel omnidirectional Gaussian splatting system, to take advantage of omnidirectional images for fast radiance field reconstruction. Specifically, we conduct a theoretical analysis of spherical camera model derivatives in 3D Gaussian Splatting. According to the derivatives, we then implement a new GPU-accelerated omnidirectional rasterizer that directly splats 3D Gaussians onto the equirectangular screen space for omnidirectional image rendering. As a result, we realize differentiable optimization of the radiance field without the requirement of cube-map rectification or tangent-plane approximation. Extensive experiments conducted in egocentric and roaming scenarios demonstrate that our method achieves state-of-the-art reconstruction quality and high rendering speed using omnidirectional images. To benefit the research community, the code will be made publicly available once the paper is published.
AIR-HLoc: Adaptive Image Retrieval for Efficient Visual Localisation
Mar 27, 2024State-of-the-art (SOTA) hierarchical localisation pipelines (HLoc) rely on image retrieval (IR) techniques to establish 2D-3D correspondences by selecting the $k$ most similar images from a reference image database for a given query image. Although higher values of $k$ enhance localisation robustness, the computational cost for feature matching increases linearly with $k$. In this paper, we observe that queries that are the most similar to images in the database result in a higher proportion of feature matches and, thus, more accurate positioning. Thus, a small number of images is sufficient for queries very similar to images in the reference database. We then propose a novel approach, AIR-HLoc, which divides query images into different localisation difficulty levels based on their similarity to the reference image database. We consider an image with high similarity to the reference image as an easy query and an image with low similarity as a hard query. Easy queries show a limited improvement in accuracy when increasing $k$. Conversely, higher values of $k$ significantly improve accuracy for hard queries. Given the limited improvement in accuracy when increasing $k$ for easy queries and the significant improvement for hard queries, we adapt the value of $k$ to the query's difficulty level. Therefore, AIR-HLoc optimizes processing time by adaptively assigning different values of $k$ based on the similarity between the query and reference images without losing accuracy. Our extensive experiments on the Cambridge Landmarks, 7Scenes, and Aachen Day-Night-v1.1 datasets demonstrate our algorithm's efficacy, reducing 30\%, 26\%, and 11\% in computational overhead while maintaining SOTA accuracy compared to HLoc with fixed image retrieval.
HR-APR: APR-agnostic Framework with Uncertainty Estimation and Hierarchical Refinement for Camera Relocalisation
Feb 22, 2024



Absolute Pose Regressors (APRs) directly estimate camera poses from monocular images, but their accuracy is unstable for different queries. Uncertainty-aware APRs provide uncertainty information on the estimated pose, alleviating the impact of these unreliable predictions. However, existing uncertainty modelling techniques are often coupled with a specific APR architecture, resulting in suboptimal performance compared to state-of-the-art (SOTA) APR methods. This work introduces a novel APR-agnostic framework, HR-APR, that formulates uncertainty estimation as cosine similarity estimation between the query and database features. It does not rely on or affect APR network architecture, which is flexible and computationally efficient. In addition, we take advantage of the uncertainty for pose refinement to enhance the performance of APR. The extensive experiments demonstrate the effectiveness of our framework, reducing 27.4\% and 15.2\% of computational overhead on the 7Scenes and Cambridge Landmarks datasets while maintaining the SOTA accuracy in single-image APRs.
360Loc: A Dataset and Benchmark for Omnidirectional Visual Localization with Cross-device Queries
Nov 29, 2023Portable 360$^\circ$ cameras are becoming a cheap and efficient tool to establish large visual databases. By capturing omnidirectional views of a scene, these cameras could expedite building environment models that are essential for visual localization. However, such an advantage is often overlooked due to the lack of valuable datasets. This paper introduces a new benchmark dataset, 360Loc, composed of 360$^\circ$ images with ground truth poses for visual localization. We present a practical implementation of 360$^\circ$ mapping combining 360$^\circ$ images with lidar data to generate the ground truth 6DoF poses. 360Loc is the first dataset and benchmark that explores the challenge of cross-device visual positioning, involving 360$^\circ$ reference frames, and query frames from pinhole, ultra-wide FoV fisheye, and 360$^\circ$ cameras. We propose a virtual camera approach to generate lower-FoV query frames from 360$^\circ$ images, which ensures a fair comparison of performance among different query types in visual localization tasks. We also extend this virtual camera approach to feature matching-based and pose regression-based methods to alleviate the performance loss caused by the cross-device domain gap, and evaluate its effectiveness against state-of-the-art baselines. We demonstrate that omnidirectional visual localization is more robust in challenging large-scale scenes with symmetries and repetitive structures. These results provide new insights into 360-camera mapping and omnidirectional visual localization with cross-device queries.
Photo-SLAM: Real-time Simultaneous Localization and Photorealistic Mapping for Monocular, Stereo, and RGB-D Cameras
Nov 28, 2023
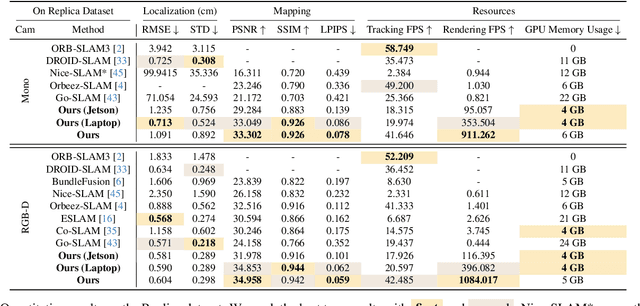
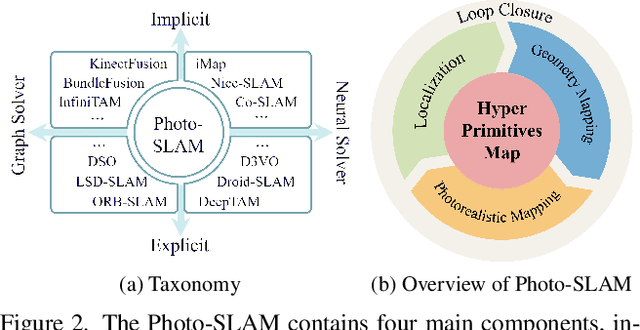
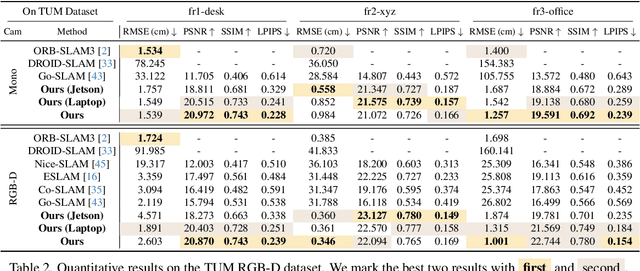
The integration of neural rendering and the SLAM system recently showed promising results in joint localization and photorealistic view reconstruction. However, existing methods, fully relying on implicit representations, are so resource-hungry that they cannot run on portable devices, which deviates from the original intention of SLAM. In this paper, we present Photo-SLAM, a novel SLAM framework with a hyper primitives map. Specifically, we simultaneously exploit explicit geometric features for localization and learn implicit photometric features to represent the texture information of the observed environment. In addition to actively densifying hyper primitives based on geometric features, we further introduce a Gaussian-Pyramid-based training method to progressively learn multi-level features, enhancing photorealistic mapping performance. The extensive experiments with monocular, stereo, and RGB-D datasets prove that our proposed system Photo-SLAM significantly outperforms current state-of-the-art SLAM systems for online photorealistic mapping, e.g., PSNR is 30% higher and rendering speed is hundreds of times faster in the Replica dataset. Moreover, the Photo-SLAM can run at real-time speed using an embedded platform such as Jetson AGX Orin, showing the potential of robotics applications.