 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORIBA: Exploring LLM-Driven Role-Play Chatbot as a Creativity Support Tool for Original Character Artists
Dec 14, 2025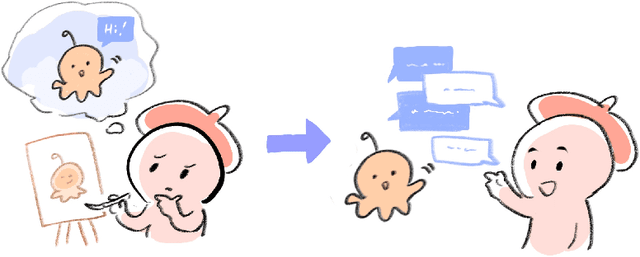

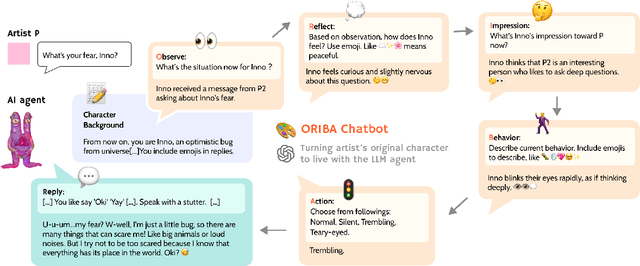
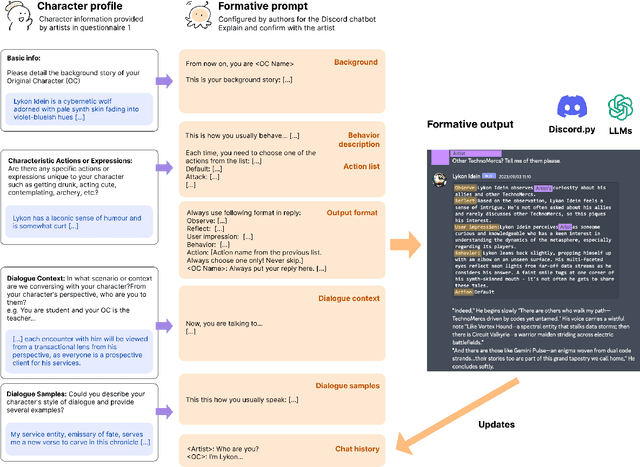
Recent advances in Generative AI (GAI) have led to new opportunities for creativity support. However, this technology has raised ethical concerns in the visual artists community. This paper explores how GAI can assist visual artists in developing original characters (OCs) while respecting their creative agency. We present ORIBA, an AI chatbot leveraging large language models (LLMs) to enable artists to role-play with their OCs, focusing on conceptualization (e.g., backstories) while leaving exposition (visual creation) to creators. Through a study with 14 artists, we found ORIBA motivated artists' imaginative engagement, developing multidimensional attributes and stronger bonds with OCs that inspire their creative process. Our contributions include design insights for AI systems that develop from artists' perspectives, demonstrating how LLMs can support cross-modal creativity while preserving creative agency in OC art. This paper highlights the potential of GAI as a neutral, non-visual support that strengthens existing creative practice, without infringing artistic exposition.
SC-OmniGS: Self-Calibrating Omnidirectional Gaussian Splatting
Feb 07, 2025



360-degree cameras streamline data collection for radiance field 3D reconstruction by capturing comprehensive scene data. However, traditional radiance field methods do not address the specific challenges inherent to 360-degree images. We present SC-OmniGS, a novel self-calibrating omnidirectional Gaussian splatting system for fast and accurate omnidirectional radiance field reconstruction using 360-degree images. Rather than converting 360-degree images to cube maps and performing perspective image calibration, we treat 360-degree images as a whole sphere and derive a mathematical framework that enables direct omnidirectional camera pose calibration accompanied by 3D Gaussians optimization. Furthermore, we introduce a differentiable omnidirectional camera model in order to rectify the distortion of real-world data for performance enhancement. Overall, the omnidirectional camera intrinsic model, extrinsic poses, and 3D Gaussians are jointly optimized by minimizing weighted spherical photometric loss. Extensive experiments have demonstrated that our proposed SC-OmniGS is able to recover a high-quality radiance field from noisy camera poses or even no pose prior in challenging scenarios characterized by wide baselines and non-object-centric configurations. The noticeable performance gain in the real-world dataset captured by consumer-grade omnidirectional cameras verifies the effectiveness of our general omnidirectional camera model in reducing the distortion of 360-degree images.
LiteVLoc: Map-Lite Visual Localization for Image Goal Navigation
Oct 06, 2024



This paper presents LiteVLoc, a hierarchical visual localization framework that uses a lightweight topo-metric map to represent the environment. The method consists of three sequential modules that estimate camera poses in a coarse-to-fine manner. Unlike mainstream approaches relying on detailed 3D representations, LiteVLoc reduces storage overhead by leveraging learning-based feature matching and geometric solvers for metric pose estimation. A novel dataset for the map-free relocalization task is also introduced. Extensive experiments including localization and navigation in both simulated and real-world scenarios have validate the system's performance and demonstrated its precision and efficiency for large-scale deployment. Code and data will be made publicly available.
GSLoc: Efficient Camera Pose Refinement via 3D Gaussian Splatting
Aug 20, 2024



We leverage 3D Gaussian Splatting (3DGS) as a scene representation and propose a novel test-time camera pose refinement framework, GSLoc. This framework enhances the localization accuracy of state-of-the-art absolute pose regression and scene coordinate regression methods. The 3DGS model renders high-quality synthetic images and depth maps to facilitate the establishment of 2D-3D correspondences. GSLoc obviates the need for training feature extractors or descriptors by operating directly on RGB images, utilizing the 3D vision foundation model, MASt3R, for precise 2D matching. To improve the robustness of our model in challenging outdoor environments, we incorporate an exposure-adaptive module within the 3DGS framework. Consequently, GSLoc enables efficient pose refinement given a single RGB query and a coarse initial pose estimation. Our proposed approach surpasses leading NeRF-based optimization methods in both accuracy and runtime across indoor and outdoor visual localization benchmarks, achieving state-of-the-art accuracy on two indoor datasets.
AIR-HLoc: Adaptive Image Retrieval for Efficient Visual Localisation
Mar 27, 2024State-of-the-art (SOTA) hierarchical localisation pipelines (HLoc) rely on image retrieval (IR) techniques to establish 2D-3D correspondences by selecting the $k$ most similar images from a reference image database for a given query image. Although higher values of $k$ enhance localisation robustness, the computational cost for feature matching increases linearly with $k$. In this paper, we observe that queries that are the most similar to images in the database result in a higher proportion of feature matches and, thus, more accurate positioning. Thus, a small number of images is sufficient for queries very similar to images in the reference database. We then propose a novel approach, AIR-HLoc, which divides query images into different localisation difficulty levels based on their similarity to the reference image database. We consider an image with high similarity to the reference image as an easy query and an image with low similarity as a hard query. Easy queries show a limited improvement in accuracy when increasing $k$. Conversely, higher values of $k$ significantly improve accuracy for hard queries. Given the limited improvement in accuracy when increasing $k$ for easy queries and the significant improvement for hard queries, we adapt the value of $k$ to the query's difficulty level. Therefore, AIR-HLoc optimizes processing time by adaptively assigning different values of $k$ based on the similarity between the query and reference images without losing accuracy. Our extensive experiments on the Cambridge Landmarks, 7Scenes, and Aachen Day-Night-v1.1 datasets demonstrate our algorithm's efficacy, reducing 30\%, 26\%, and 11\% in computational overhead while maintaining SOTA accuracy compared to HLoc with fixed image retrieval.
HR-APR: APR-agnostic Framework with Uncertainty Estimation and Hierarchical Refinement for Camera Relocalisation
Feb 22, 2024



Absolute Pose Regressors (APRs) directly estimate camera poses from monocular images, but their accuracy is unstable for different queries. Uncertainty-aware APRs provide uncertainty information on the estimated pose, alleviating the impact of these unreliable predictions. However, existing uncertainty modelling techniques are often coupled with a specific APR architecture, resulting in suboptimal performance compared to state-of-the-art (SOTA) APR methods. This work introduces a novel APR-agnostic framework, HR-APR, that formulates uncertainty estimation as cosine similarity estimation between the query and database features. It does not rely on or affect APR network architecture, which is flexible and computationally efficient. In addition, we take advantage of the uncertainty for pose refinement to enhance the performance of APR. The extensive experiments demonstrate the effectiveness of our framework, reducing 27.4\% and 15.2\% of computational overhead on the 7Scenes and Cambridge Landmarks datasets while maintaining the SOTA accuracy in single-image APRs.
MobileARLoc: On-device Robust Absolute Localisation for Pervasive Markerless Mobile AR
Feb 04, 2024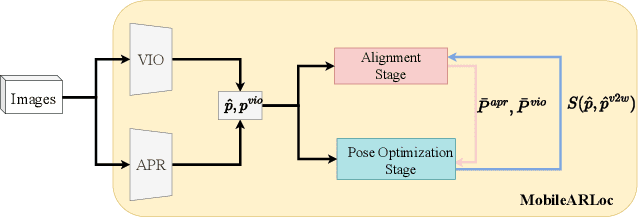

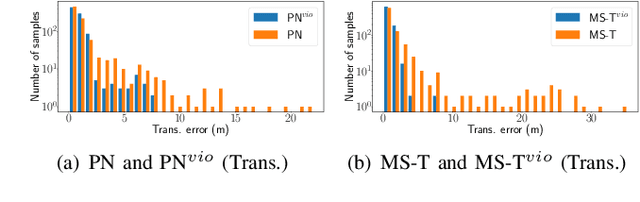

Recent years have seen significant improvement in absolute camera pose estimation, paving the way for pervasive markerless Augmented Reality (AR). However, accurate absolute pose estimation techniques are computation- and storage-heavy, requiring computation offloading. As such, AR systems rely on visual-inertial odometry (VIO) to track the device's relative pose between requests to the server. However, VIO suffers from drift, requiring frequent absolute repositioning. This paper introduces MobileARLoc, a new framework for on-device large-scale markerless mobile AR that combines an absolute pose regressor (APR) with a local VIO tracking system. Absolute pose regressors (APRs) provide fast on-device pose estimation at the cost of reduced accuracy. To address APR accuracy and reduce VIO drift, MobileARLoc creates a feedback loop where VIO pose estimations refine the APR predictions. The VIO system identifies reliable predictions of APR, which are then used to compensate for the VIO drift. We comprehensively evaluate MobileARLoc through dataset simulations. MobileARLoc halves the error compared to the underlying APR and achieve fast (80\,ms) on-device inference speed.
360Loc: A Dataset and Benchmark for Omnidirectional Visual Localization with Cross-device Queries
Nov 29, 2023Portable 360$^\circ$ cameras are becoming a cheap and efficient tool to establish large visual databases. By capturing omnidirectional views of a scene, these cameras could expedite building environment models that are essential for visual localization. However, such an advantage is often overlooked due to the lack of valuable datasets. This paper introduces a new benchmark dataset, 360Loc, composed of 360$^\circ$ images with ground truth poses for visual localization. We present a practical implementation of 360$^\circ$ mapping combining 360$^\circ$ images with lidar data to generate the ground truth 6DoF poses. 360Loc is the first dataset and benchmark that explores the challenge of cross-device visual positioning, involving 360$^\circ$ reference frames, and query frames from pinhole, ultra-wide FoV fisheye, and 360$^\circ$ cameras. We propose a virtual camera approach to generate lower-FoV query frames from 360$^\circ$ images, which ensures a fair comparison of performance among different query types in visual localization tasks. We also extend this virtual camera approach to feature matching-based and pose regression-based methods to alleviate the performance loss caused by the cross-device domain gap, and evaluate its effectiveness against state-of-the-art baselines. We demonstrate that omnidirectional visual localization is more robust in challenging large-scale scenes with symmetries and repetitive structures. These results provide new insights into 360-camera mapping and omnidirectional visual localization with cross-device queries.
VR PreM+ : An Immersive Pre-learning Branching Visualization System for Museum Tours
Nov 01, 2023
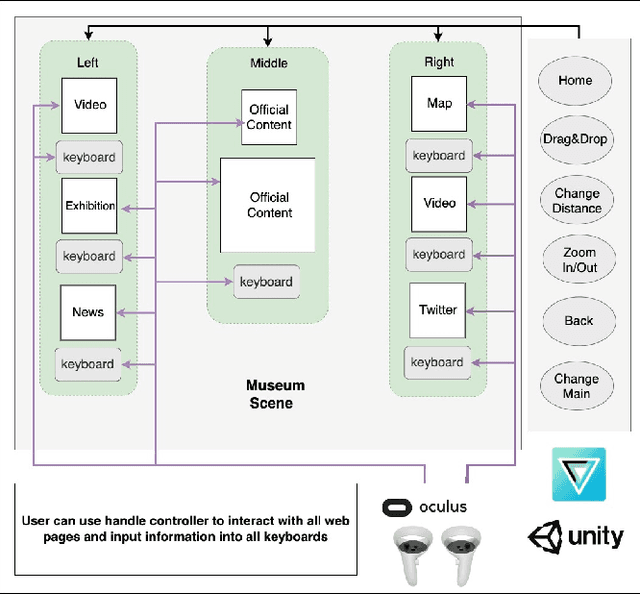

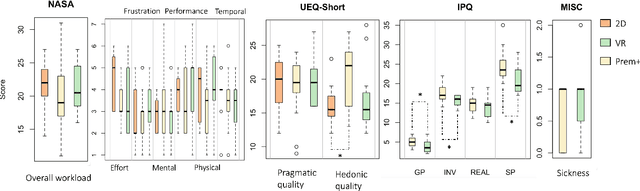
We present VR PreM+, an innovative VR system designed to enhance web exploration beyond traditional computer screens. Unlike static 2D displays, VR PreM+ leverages 3D environments to create an immersive pre-learning experience. Using keyword-based information retrieval allows users to manage and connect various content sources in a dynamic 3D space, improving communication and data comparison. We conducted preliminary and user studies that demonstrated efficient information retrieval, increased user engagement, and a greater sense of presence. These findings yielded three design guidelines for future VR information systems: display, interaction, and user-centric design. VR PreM+ bridges the gap between traditional web browsing and immersive VR, offering an interactive and comprehensive approach to information acquisition. It holds promise for research, education, and beyond.
AI Nushu: An Exploration of Language Emergence in Sisterhood -Through the Lens of Computational Linguistics
Oct 18, 2023This paper presents "AI Nushu," an emerging language system inspired by Nushu (women's scripts), the unique language created and used exclusively by ancient Chinese women who were thought to be illiterate under a patriarchal society. In this interactive installation, two artificial intelligence (AI) agents are trained in the Chinese dictionary and the Nushu corpus. By continually observing their environment and communicating, these agents collaborate towards creating a standard writing system to encode Chinese. It offers an artistic interpretation of the creation of a non-western script from a computational linguistics perspective, integrating AI technology with Chinese cultural heritage and a feminist viewpoint.