 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHR-APR: APR-agnostic Framework with Uncertainty Estimation and Hierarchical Refinement for Camera Relocalisation
Feb 22, 2024



Absolute Pose Regressors (APRs) directly estimate camera poses from monocular images, but their accuracy is unstable for different queries. Uncertainty-aware APRs provide uncertainty information on the estimated pose, alleviating the impact of these unreliable predictions. However, existing uncertainty modelling techniques are often coupled with a specific APR architecture, resulting in suboptimal performance compared to state-of-the-art (SOTA) APR methods. This work introduces a novel APR-agnostic framework, HR-APR, that formulates uncertainty estimation as cosine similarity estimation between the query and database features. It does not rely on or affect APR network architecture, which is flexible and computationally efficient. In addition, we take advantage of the uncertainty for pose refinement to enhance the performance of APR. The extensive experiments demonstrate the effectiveness of our framework, reducing 27.4\% and 15.2\% of computational overhead on the 7Scenes and Cambridge Landmarks datasets while maintaining the SOTA accuracy in single-image APRs.
SD4Match: Learning to Prompt Stable Diffusion Model for Semantic Matching
Oct 26, 2023In this paper, we address the challenge of matching semantically similar keypoints across image pairs. Existing research indicates that the intermediate output of the UNet within the Stable Diffusion (SD) can serve as robust image feature maps for such a matching task. We demonstrate that by employing a basic prompt tuning technique, the inherent potential of Stable Diffusion can be harnessed, resulting in a significant enhancement in accuracy over previous approaches. We further introduce a novel conditional prompting module that conditions the prompt on the local details of the input image pairs, leading to a further improvement in performance. We designate our approach as SD4Match, short for Stable Diffusion for Semantic Matching. Comprehensive evaluations of SD4Match on the PF-Pascal, PF-Willow, and SPair-71k datasets show that it sets new benchmarks in accuracy across all these datasets. Particularly, SD4Match outperforms the previous state-of-the-art by a margin of 12 percentage points on the challenging SPair-71k dataset.
Cos R-CNN for Online Few-shot Object Detection
Jul 25, 2023



We propose Cos R-CNN, a simple exemplar-based R-CNN formulation that is designed for online few-shot object detection. That is, it is able to localise and classify novel object categories in images with few examples without fine-tuning. Cos R-CNN frames detection as a learning-to-compare task: unseen classes are represented as exemplar images, and objects are detected based on their similarity to these exemplars. The cosine-based classification head allows for dynamic adaptation of classification parameters to the exemplar embedding, and encourages the clustering of similar classes in embedding space without the need for manual tuning of distance-metric hyperparameters. This simple formulation achieves best results on the recently proposed 5-way ImageNet few-shot detection benchmark, beating the online 1/5/10-shot scenarios by more than 8/3/1%, as well as performing up to 20% better in online 20-way few-shot VOC across all shots on novel classes.
SimpleRecon: 3D Reconstruction Without 3D Convolutions
Aug 31, 2022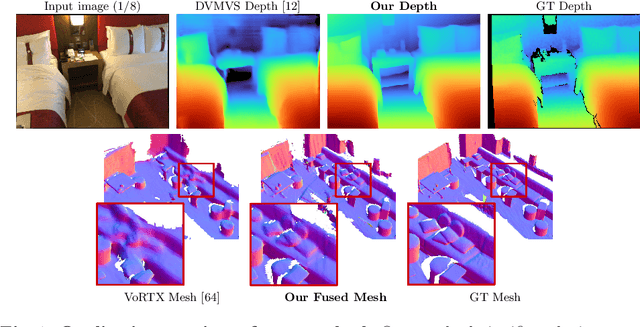
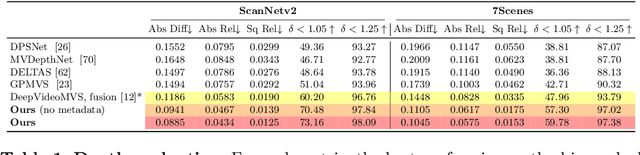
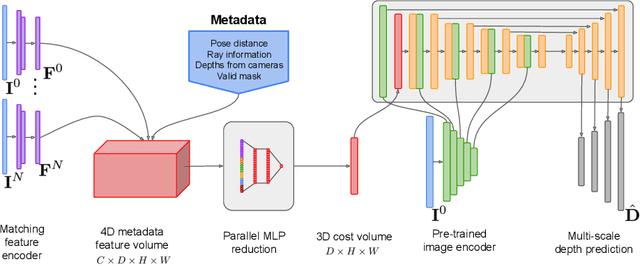
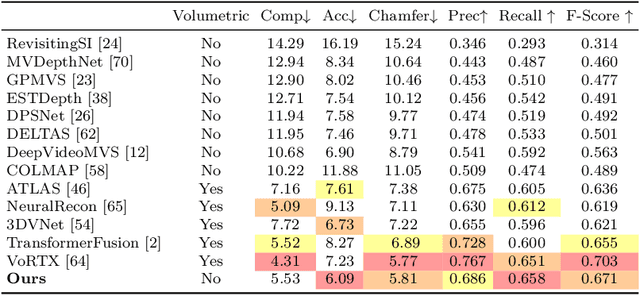
Traditionally, 3D indoor scene reconstruction from posed images happens in two phases: per-image depth estimation, followed by depth merging and surface reconstruction. Recently, a family of methods have emerged that perform reconstruction directly in final 3D volumetric feature space. While these methods have shown impressive reconstruction results, they rely on expensive 3D convolutional layers, limiting their application in resource-constrained environments. In this work, we instead go back to the traditional route, and show how focusing on high quality multi-view depth prediction leads to highly accurate 3D reconstructions using simple off-the-shelf depth fusion. We propose a simple state-of-the-art multi-view depth estimator with two main contributions: 1) a carefully-designed 2D CNN which utilizes strong image priors alongside a plane-sweep feature volume and geometric losses, combined with 2) the integration of keyframe and geometric metadata into the cost volume which allows informed depth plane scoring. Our method achieves a significant lead over the current state-of-the-art for depth estimation and close or better for 3D reconstruction on ScanNet and 7-Scenes, yet still allows for online real-time low-memory reconstruction. Code, models and results are available at https://nianticlabs.github.io/simplerecon
Learning to Count Anything: Reference-less Class-agnostic Counting with Weak Supervision
May 20, 2022
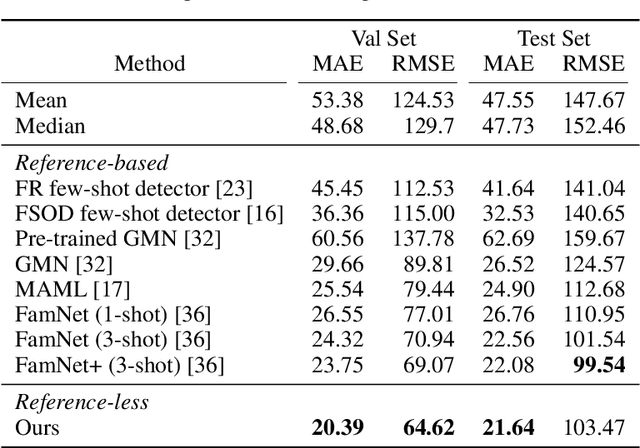
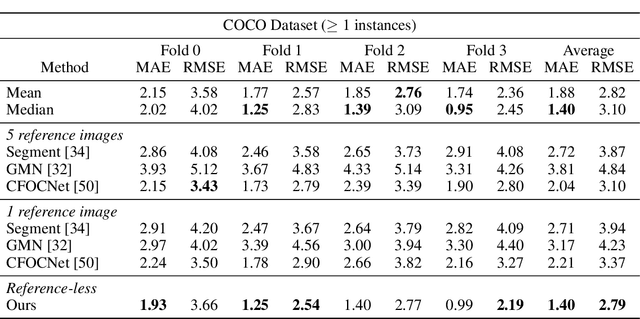

Object counting is a seemingly simple task with diverse real-world applications. Most counting methods focus on counting instances of specific, known classes. While there are class-agnostic counting methods that can generalise to unseen classes, these methods require reference images to define the type of object to be counted, as well as instance annotations during training. We identify that counting is, at its core, a repetition-recognition task and show that a general feature space, with global context, is sufficient to enumerate instances in an image without a prior on the object type present. Specifically, we demonstrate that self-supervised vision transformer features combined with a lightweight count regression head achieve competitive results when compared to other class-agnostic counting tasks without the need for point-level supervision or reference images. Our method thus facilitates counting on a constantly changing set composition. To the best of our knowledge, we are both the first reference-less class-agnostic counting method as well as the first weakly-supervised class-agnostic counting method.
The Temporal Opportunist: Self-Supervised Multi-Frame Monocular Depth
Apr 29, 2021
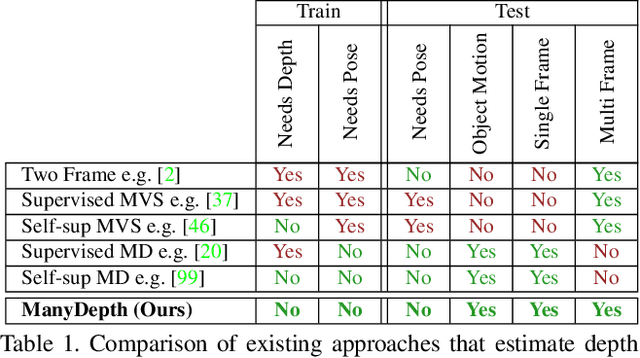
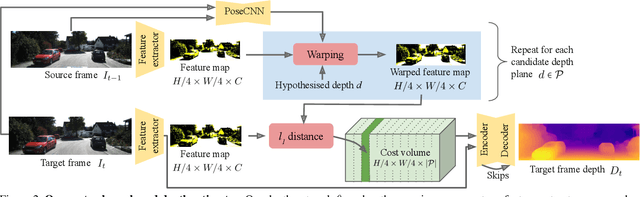
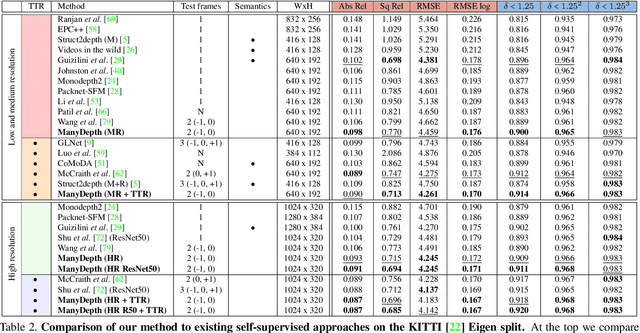
Self-supervised monocular depth estimation networks are trained to predict scene depth using nearby frames as a supervision signal during training. However, for many applications, sequence information in the form of video frames is also available at test time. The vast majority of monocular networks do not make use of this extra signal, thus ignoring valuable information that could be used to improve the predicted depth. Those that do, either use computationally expensive test-time refinement techniques or off-the-shelf recurrent networks, which only indirectly make use of the geometric information that is inherently available. We propose ManyDepth, an adaptive approach to dense depth estimation that can make use of sequence information at test time, when it is available. Taking inspiration from multi-view stereo, we propose a deep end-to-end cost volume based approach that is trained using self-supervision only. We present a novel consistency loss that encourages the network to ignore the cost volume when it is deemed unreliable, e.g. in the case of moving objects, and an augmentation scheme to cope with static cameras. Our detailed experiments on both KITTI and Cityscapes show that we outperform all published self-supervised baselines, including those that use single or multiple frames at test time.
Direct-PoseNet: Absolute Pose Regression with Photometric Consistency
Apr 08, 2021


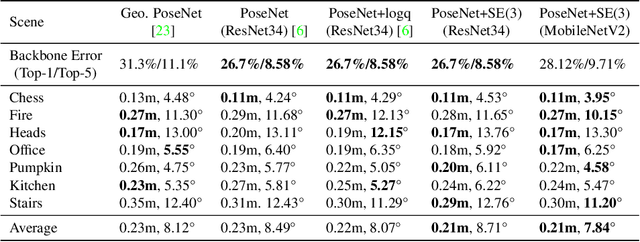
We present a relocalization pipeline, which combines an absolute pose regression (APR) network with a novel view synthesis based direct matching module, offering superior accuracy while maintaining low inference time. Our contribution is twofold: i) we design a direct matching module that supplies a photometric supervision signal to refine the pose regression network via differentiable rendering; ii) we modify the rotation representation from the classical quaternion to SO(3) in pose regression, removing the need for balancing rotation and translation loss terms. As a result, our network Direct-PoseNet achieves state-of-the-art performance among all other single-image APR methods on the 7-Scenes benchmark and the LLFF dataset.
Correspondence Networks with Adaptive Neighbourhood Consensus
Mar 26, 2020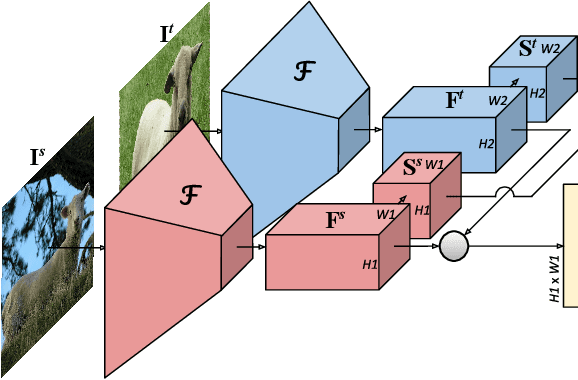
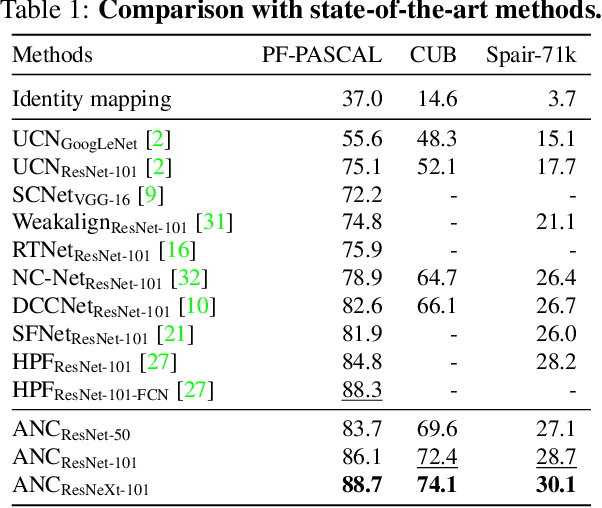
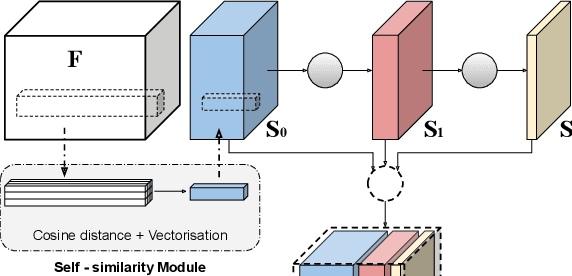

In this paper, we tackle the task of establishing dense visual correspondences between images containing objects of the same category. This is a challenging task due to large intra-class variations and a lack of dense pixel level annotations. We propose a convolutional neural network architecture, called adaptive neighbourhood consensus network (ANC-Net), that can be trained end-to-end with sparse key-point annotations, to handle this challenge. At the core of ANC-Net is our proposed non-isotropic 4D convolution kernel, which forms the building block for the adaptive neighbourhood consensus module for robust matching. We also introduce a simple and efficient multi-scale self-similarity module in ANC-Net to make the learned feature robust to intra-class variations. Furthermore, we propose a novel orthogonal loss that can enforce the one-to-one matching constraint. We thoroughly evaluate the effectiveness of our method on various benchmarks, where it substantially outperforms state-of-the-art methods.
Domain-invariant Stereo Matching Networks
Nov 29, 2019
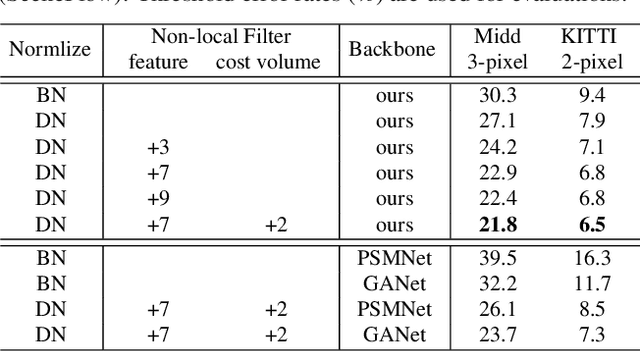

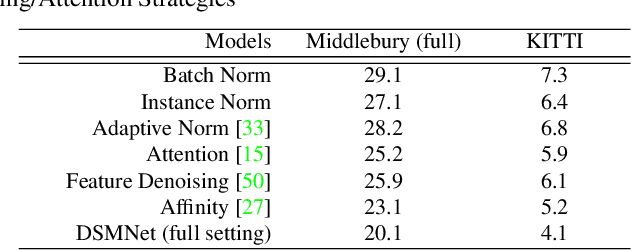
State-of-the-art stereo matching networks have difficulties in generalizing to new unseen environments due to significant domain differences, such as color, illumination, contrast, and texture. In this paper, we aim at designing a domain-invariant stereo matching network (DSMNet) that generalizes well to unseen scenes. To achieve this goal, we propose i) a novel "domain normalization" approach that regularizes the distribution of learned representations to allow them to be invariant to domain differences, and ii) a trainable non-local graph-based filter for extracting robust structural and geometric representations that can further enhance domain-invariant generalizations. When trained on synthetic data and generalized to real test sets, our model performs significantly better than all state-of-the-art models. It even outperforms some deep learning models (e.g. MC-CNN) fine-tuned with test-domain data.
Thinking Outside the Box: Generation of Unconstrained 3D Room Layouts
May 08, 2019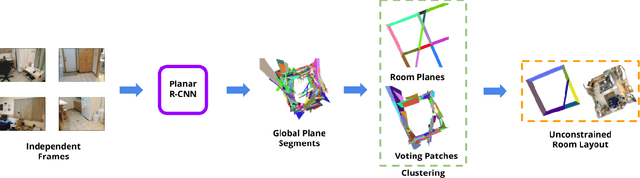
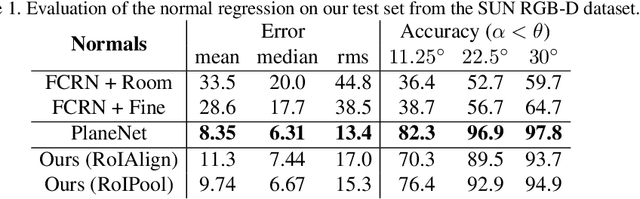

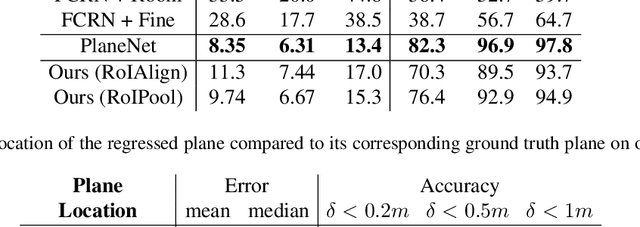
We propose a method for room layout estimation that does not rely on the typical box approximation or Manhattan world assumption. Instead, we reformulate the geometry inference problem as an instance detection task, which we solve by directly regressing 3D planes using an R-CNN. We then use a variant of probabilistic clustering to combine the 3D planes regressed at each frame in a video sequence, with their respective camera poses, into a single global 3D room layout estimate. Finally, we showcase results which make no assumptions about perpendicular alignment, so can deal effectively with walls in any alignment.