 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualising Implicit Representations for Semantic Tasks
May 22, 2023Prior works have demonstrated that implicit representations trained only for reconstruction tasks typically generate encodings that are not useful for semantic tasks. In this work, we propose a method that contextualises the encodings of implicit representations, enabling their use in downstream tasks (e.g. semantic segmentation), without requiring access to the original training data or encoding network. Using an implicit representation trained for a reconstruction task alone, our contextualising module takes an encoding trained for reconstruction only and reveals meaningful semantic information that is hidden in the encodings, without compromising the reconstruction performance. With our proposed module, it becomes possible to pre-train implicit representations on larger datasets, improving their reconstruction performance compared to training on only a smaller labelled dataset, whilst maintaining their segmentation performance on the labelled dataset. Importantly, our method allows for future foundation implicit representation models to be fine-tuned on unseen tasks, regardless of encoder or dataset availability.
Approximating Continuous Convolutions for Deep Network Compression
Oct 17, 2022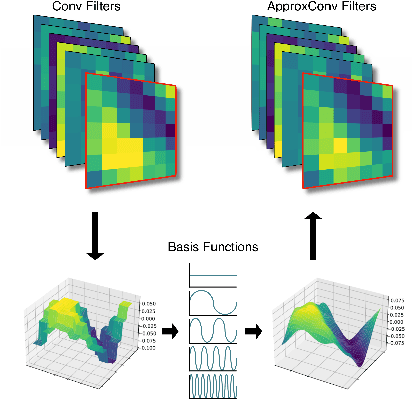
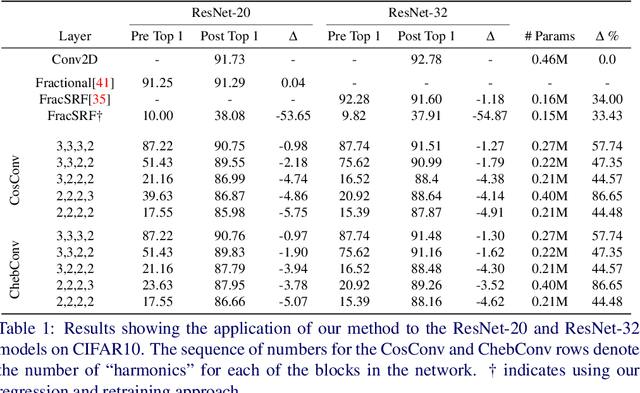
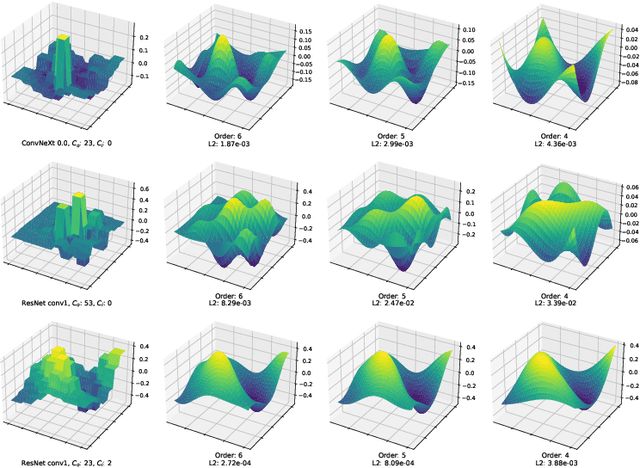
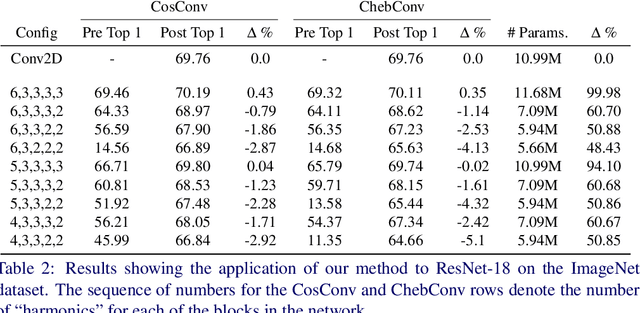
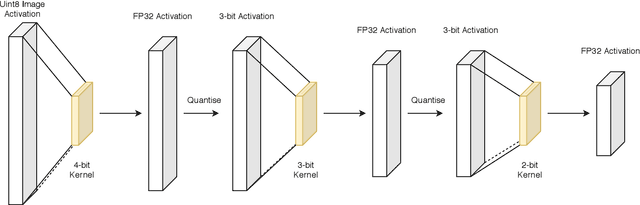
We present ApproxConv, a novel method for compressing the layers of a convolutional neural network. Reframing conventional discrete convolution as continuous convolution of parametrised functions over space, we use functional approximations to capture the essential structures of CNN filters with fewer parameters than conventional operations. Our method is able to reduce the size of trained CNN layers requiring only a small amount of fine-tuning. We show that our method is able to compress existing deep network models by half whilst losing only 1.86% accuracy. Further, we demonstrate that our method is compatible with other compression methods like quantisation allowing for further reductions in model size.
Towards Generalising Neural Implicit Representations
Jan 29, 2021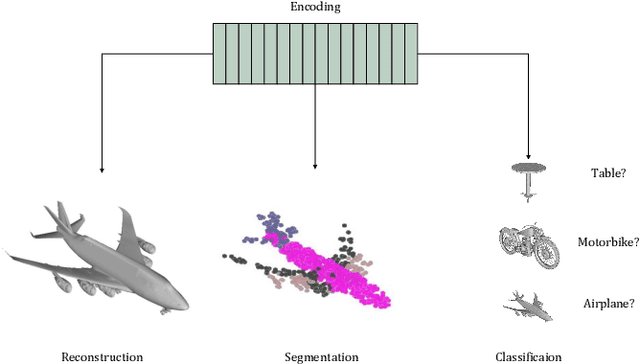
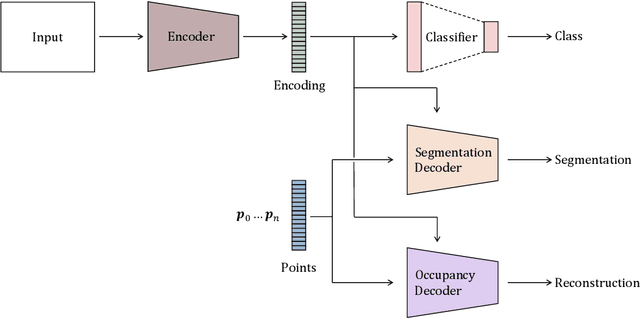
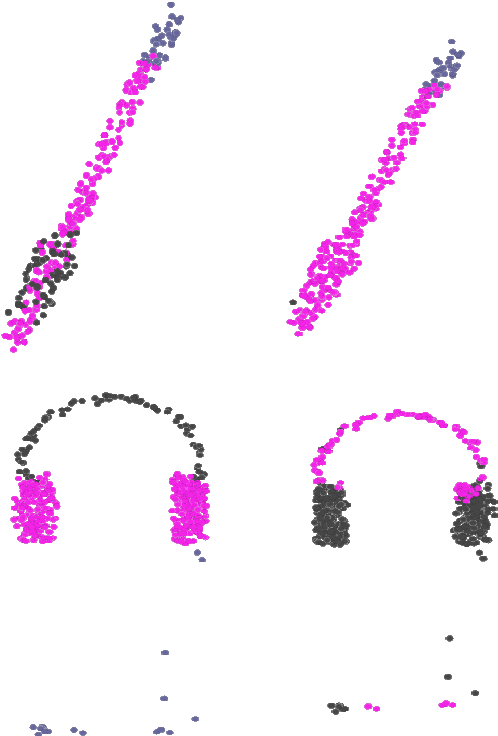
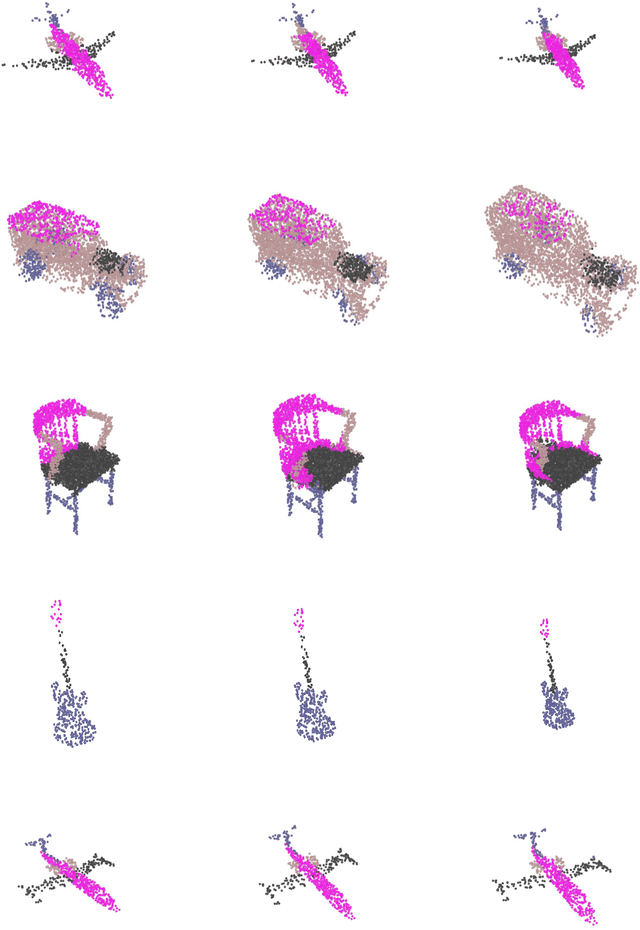
Neural implicit representations have shown substantial improvements in efficiently storing 3D data, when compared to conventional formats. However, the focus of existing work has mainly been on storage and subsequent reconstruction. In this work, we argue that training neural representations for both reconstruction tasks, alongside conventional tasks, can produce more general encodings that admit equal quality reconstructions to single task training, whilst providing improved results on conventional tasks when compared to single task encodings. Through multi-task experiments on reconstruction, classification, and segmentation our approach learns feature rich encodings that produce high quality results for each task. We also reformulate the segmentation task, creating a more representative challenge for implicit representation contexts.
Finding Non-Uniform Quantization Schemes using Multi-Task Gaussian Processes
Jul 20, 2020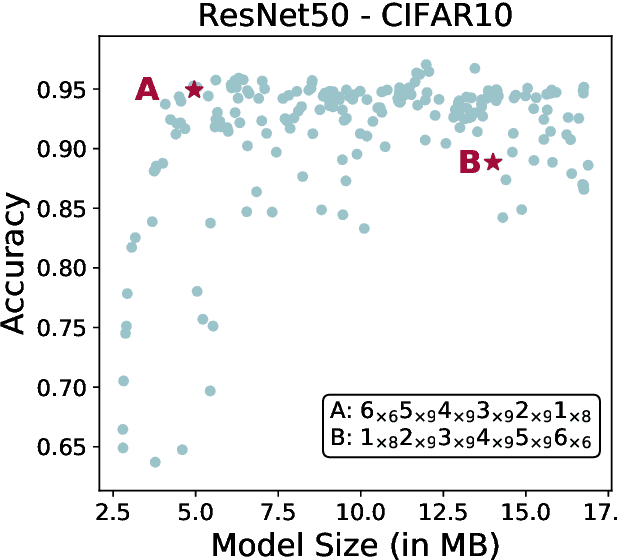
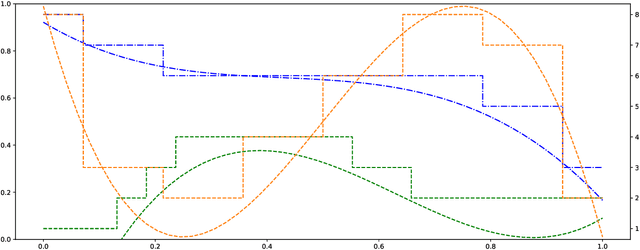

We propose a novel method for neural network quantization that casts the neural architecture search problem as one of hyperparameter search to find non-uniform bit distributions throughout the layers of a CNN. We perform the search assuming a Multi-Task Gaussian Processes prior, which splits the problem to multiple tasks, each corresponding to different number of training epochs, and explore the space by sampling those configurations that yield maximum information. We then show that with significantly lower precision in the last layers we achieve a minimal loss of accuracy with appreciable memory savings. We test our findings on the CIFAR10 and ImageNet datasets using the VGG, ResNet and GoogLeNet architectures.
Correspondence Networks with Adaptive Neighbourhood Consensus
Mar 26, 2020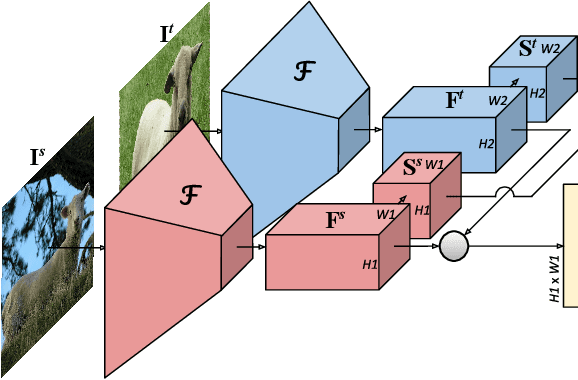
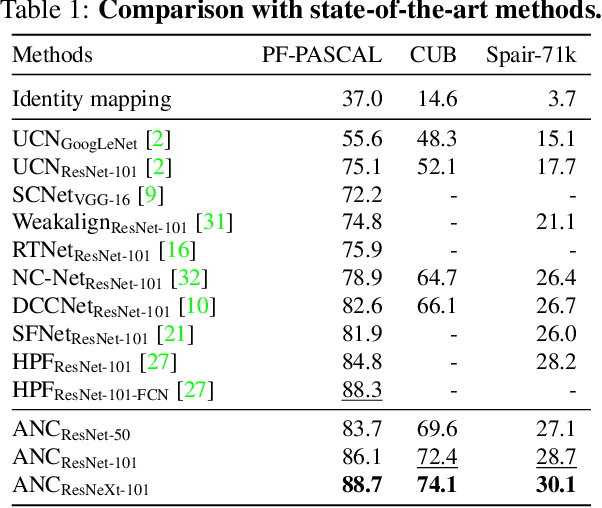
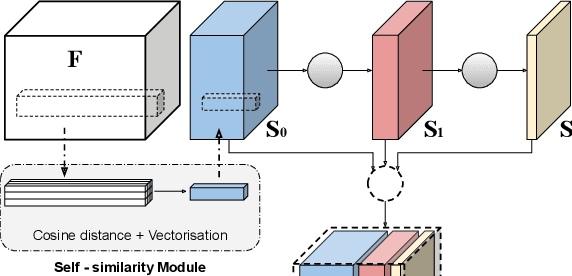

In this paper, we tackle the task of establishing dense visual correspondences between images containing objects of the same category. This is a challenging task due to large intra-class variations and a lack of dense pixel level annotations. We propose a convolutional neural network architecture, called adaptive neighbourhood consensus network (ANC-Net), that can be trained end-to-end with sparse key-point annotations, to handle this challenge. At the core of ANC-Net is our proposed non-isotropic 4D convolution kernel, which forms the building block for the adaptive neighbourhood consensus module for robust matching. We also introduce a simple and efficient multi-scale self-similarity module in ANC-Net to make the learned feature robust to intra-class variations. Furthermore, we propose a novel orthogonal loss that can enforce the one-to-one matching constraint. We thoroughly evaluate the effectiveness of our method on various benchmarks, where it substantially outperforms state-of-the-art methods.