 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIM2E: Benchmarking the Group Equivariant Capability of Correspondence Matching Algorithms
Aug 21, 2022
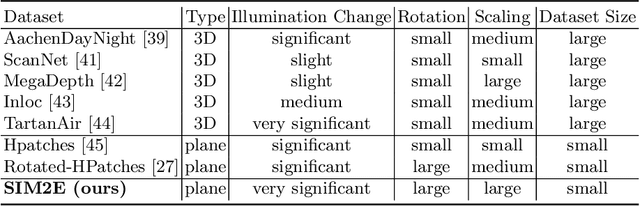

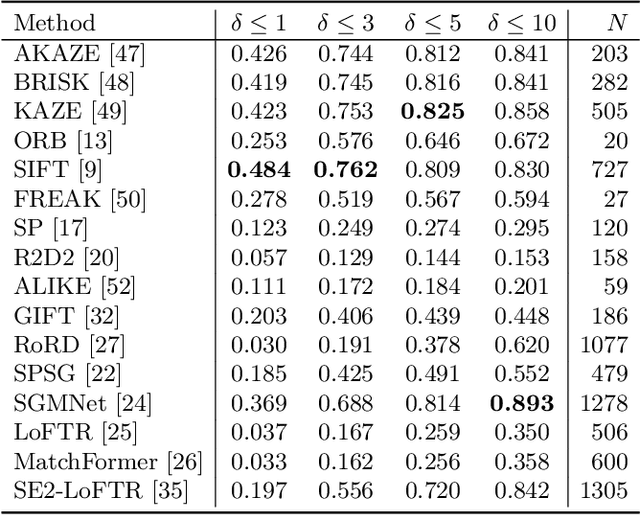
Correspondence matching is a fundamental problem in computer vision and robotics applications. Solving correspondence matching problems using neural networks has been on the rise recently. Rotation-equivariance and scale-equivariance are both critical in correspondence matching applications. Classical correspondence matching approaches are designed to withstand scaling and rotation transformations. However, the features extracted using convolutional neural networks (CNNs) are only translation-equivariant to a certain extent. Recently, researchers have strived to improve the rotation-equivariance of CNNs based on group theories. Sim(2) is the group of similarity transformations in the 2D plane. This paper presents a specialized dataset dedicated to evaluating sim(2)-equivariant correspondence matching algorithms. We compare the performance of 16 state-of-the-art (SoTA) correspondence matching approaches. The experimental results demonstrate the importance of group equivariant algorithms for correspondence matching on various sim(2) transformation conditions. Since the subpixel accuracy achieved by CNN-based correspondence matching approaches is unsatisfactory, this specific area requires more attention in future works. Our dataset is publicly available at: mias.group/SIM2E.
$\mathbb{X}$Resolution Correspondence Networks
Dec 17, 2020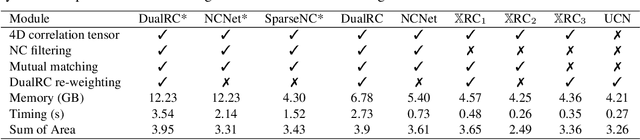
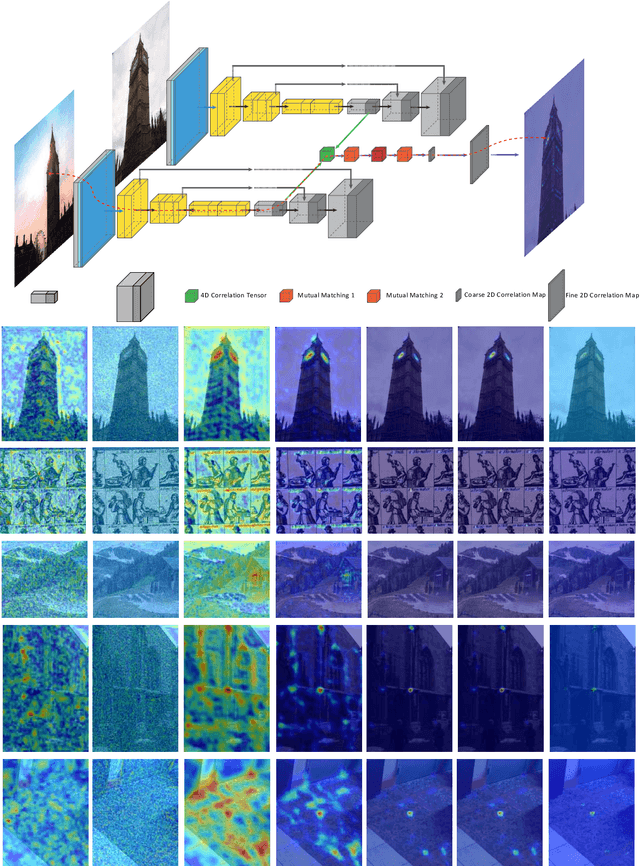
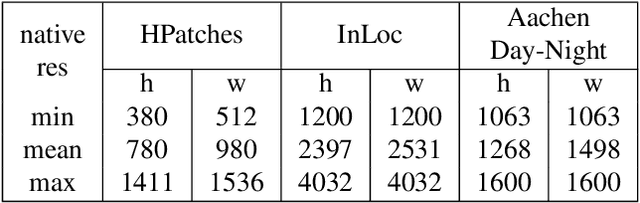
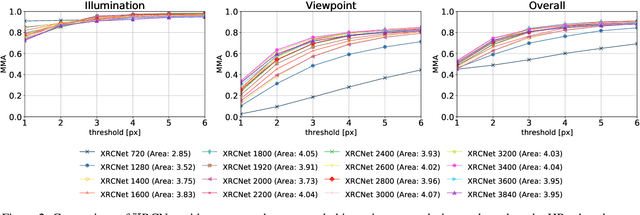
In this paper, we aim at establishing accurate dense correspondences between a pair of images with overlapping field of view under challenging illumination variation, viewpoint changes, and style differences. Through an extensive ablation study of the state-of-the-art correspondence networks, we surprisingly discovered that the widely adopted 4D correlation tensor and its related learning and processing modules could be de-parameterised and removed from training with merely a minor impact over the final matching accuracy. Disabling some of the most memory consuming and computational expensive modules dramatically speeds up the training procedure and allows to use 4x bigger batch size, which in turn compensates for the accuracy drop. Together with a multi-GPU inference stage, our method facilitates the systematic investigation of the relationship between matching accuracy and up-sampling resolution of the native testing images from 720p to 4K. This leads to finding an optimal resolution $\mathbb X$ that produces accurate matching performance surpassing the state-of-the-art methods particularly over the lower error band for the proposed network and evaluation datasets.
Dual-Resolution Correspondence Networks
Jun 16, 2020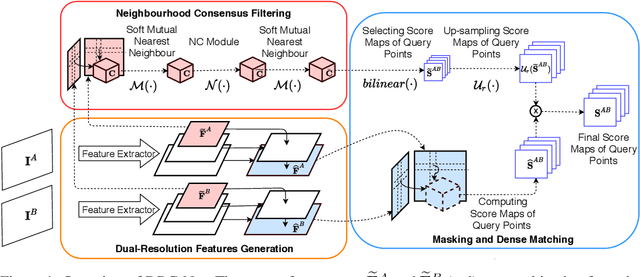
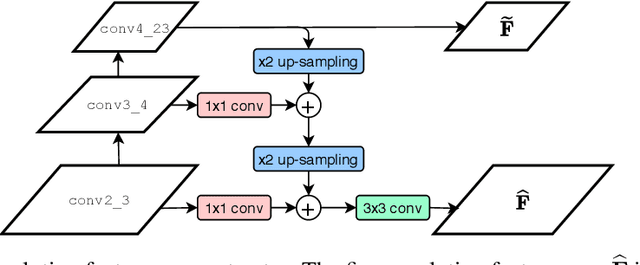
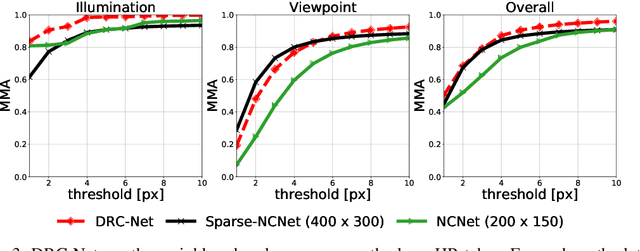

We tackle the problem of establishing dense pixel-wise correspondences between a pair of images. In this work, we introduce Dual-Resolution Correspondence Networks (DRC-Net), to obtain pixel-wise correspondences in a coarse-to-fine manner. DRC-Net extracts both coarse- and fine- resolution feature maps. The coarse maps are used to produce a full but coarse 4D correlation tensor, which is then refined by a learnable neighbourhood consensus module. The fine-resolution feature maps are used to obtain the final dense correspondences guided by the refined coarse 4D correlation tensor. The selected coarse-resolution matching scores allow the fine-resolution features to focus only on a limited number of possible matches with high confidence. In this way, DRC-Net dramatically increases matching reliability and localisation accuracy, while avoiding to apply the expensive 4D convolution kernels on fine-resolution feature maps. We comprehensively evaluate our method on large-scale public benchmarks including HPatches, InLoc, and Aachen Day-Night. It achieves the state-of-the-art results on all of them.
Correspondence Networks with Adaptive Neighbourhood Consensus
Mar 26, 2020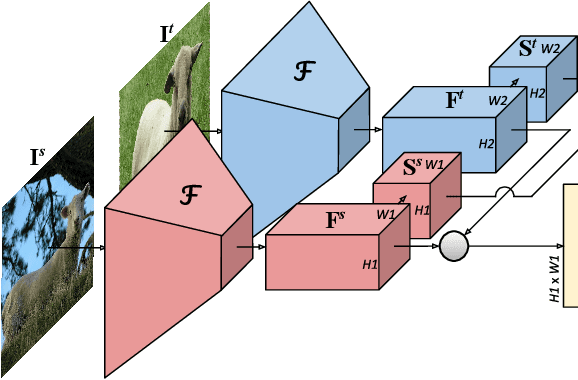
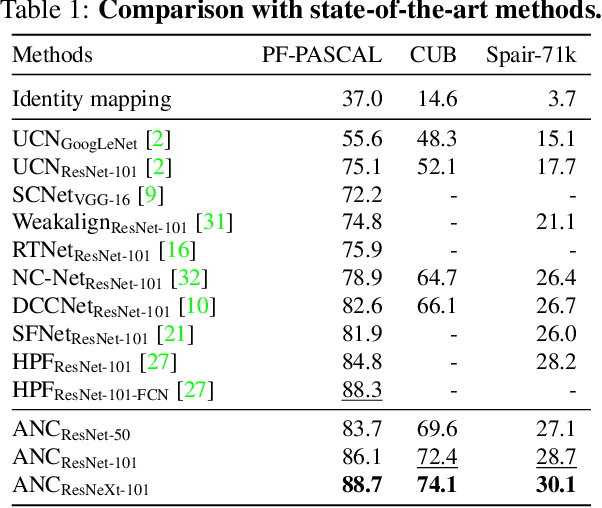
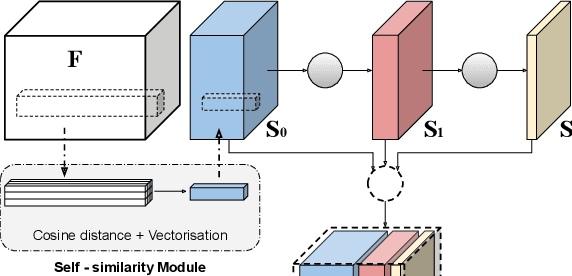

In this paper, we tackle the task of establishing dense visual correspondences between images containing objects of the same category. This is a challenging task due to large intra-class variations and a lack of dense pixel level annotations. We propose a convolutional neural network architecture, called adaptive neighbourhood consensus network (ANC-Net), that can be trained end-to-end with sparse key-point annotations, to handle this challenge. At the core of ANC-Net is our proposed non-isotropic 4D convolution kernel, which forms the building block for the adaptive neighbourhood consensus module for robust matching. We also introduce a simple and efficient multi-scale self-similarity module in ANC-Net to make the learned feature robust to intra-class variations. Furthermore, we propose a novel orthogonal loss that can enforce the one-to-one matching constraint. We thoroughly evaluate the effectiveness of our method on various benchmarks, where it substantially outperforms state-of-the-art methods.
FlowNet3D++: Geometric Losses For Deep Scene Flow Estimation
Dec 10, 2019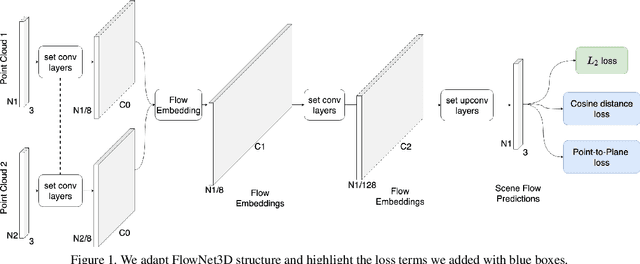
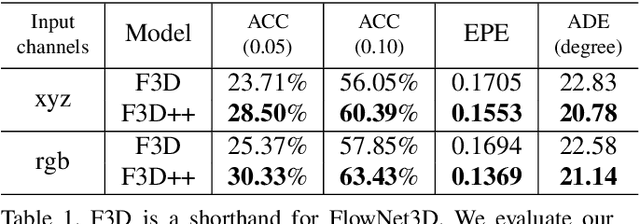
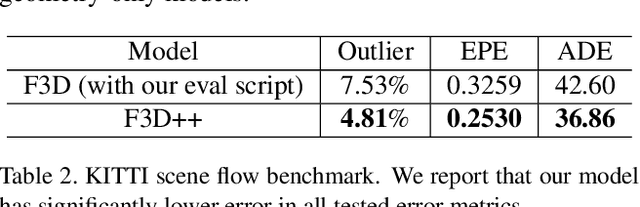
We present FlowNet3D++, a deep scene flow estimation network. Inspired by classical methods, FlowNet3D++ incorporates geometric constraints in the form of point-to-plane distance and angular alignment between individual vectors in the flow field, into FlowNet3D. We demonstrate that the addition of these geometric loss terms improves the previous state-of-art FlowNet3D accuracy from 57.85% to 63.43%. To further demonstrate the effectiveness of our geometric constraints, we propose a benchmark for flow estimation on the task of dynamic 3D reconstruction, thus providing a more holistic and practical measure of performance than the breakdown of individual metrics previously used to evaluate scene flow. This is made possible through the contribution of a novel pipeline to integrate point-based scene flow predictions into a global dense volume. FlowNet3D++ achieves up to a 15.0% reduction in reconstruction error over FlowNet3D, and up to a 35.2% improvement over KillingFusion alone. We will release our scene flow estimation code later.
Thinking Outside the Box: Generation of Unconstrained 3D Room Layouts
May 08, 2019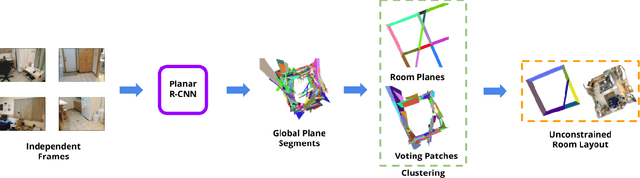
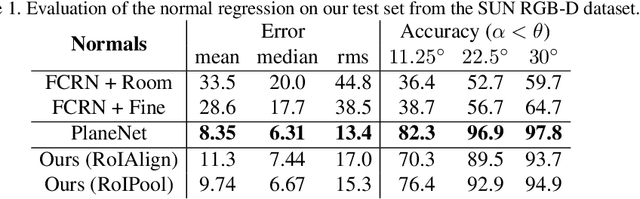

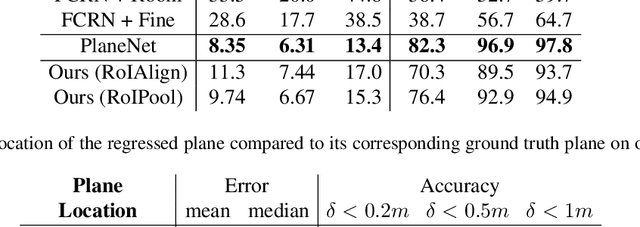
We propose a method for room layout estimation that does not rely on the typical box approximation or Manhattan world assumption. Instead, we reformulate the geometry inference problem as an instance detection task, which we solve by directly regressing 3D planes using an R-CNN. We then use a variant of probabilistic clustering to combine the 3D planes regressed at each frame in a video sequence, with their respective camera poses, into a single global 3D room layout estimate. Finally, we showcase results which make no assumptions about perpendicular alignment, so can deal effectively with walls in any alignment.
HDRFusion: HDR SLAM using a low-cost auto-exposure RGB-D sensor
Apr 04, 2016
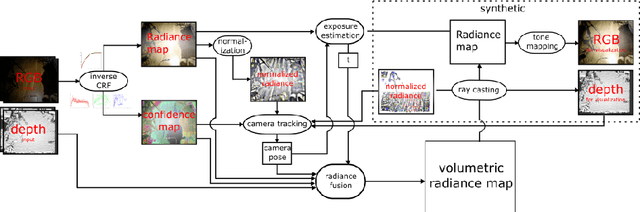

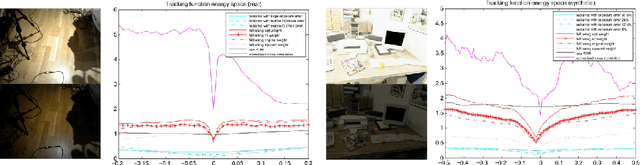
We describe a new method for comparing frame appearance in a frame-to-model 3-D mapping and tracking system using an low dynamic range (LDR) RGB-D camera which is robust to brightness changes caused by auto exposure. It is based on a normalised radiance measure which is invariant to exposure changes and not only robustifies the tracking under changing lighting conditions, but also enables the following exposure compensation perform accurately to allow online building of high dynamic range (HDR) maps. The latter facilitates the frame-to-model tracking to minimise drift as well as better capturing light variation within the scene. Results from experiments with synthetic and real data demonstrate that the method provides both improved tracking and maps with far greater dynamic range of luminosity.