 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\mathbb{X}$Resolution Correspondence Networks
Dec 17, 2020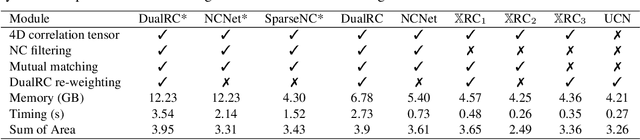
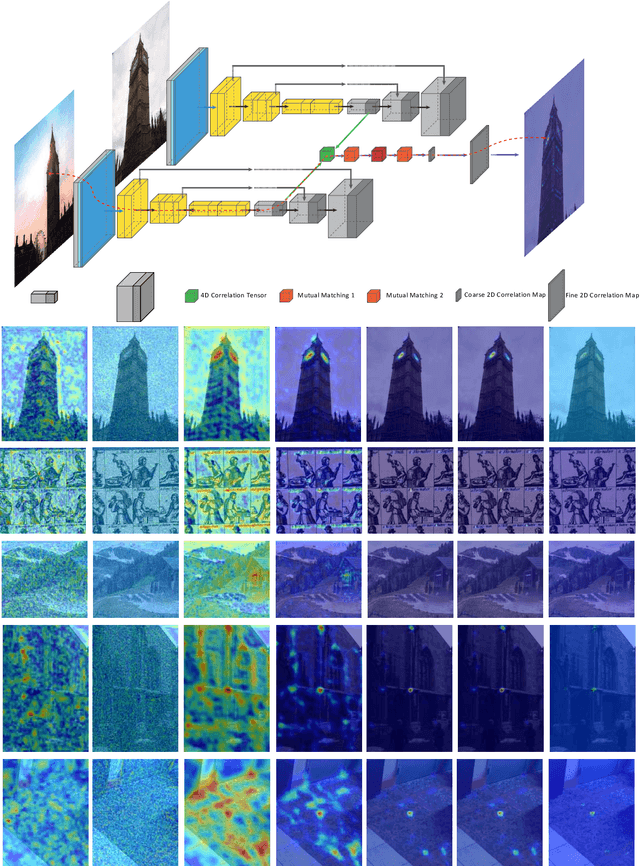
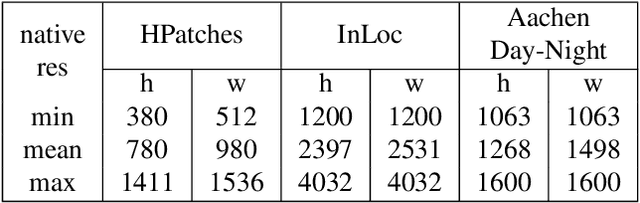
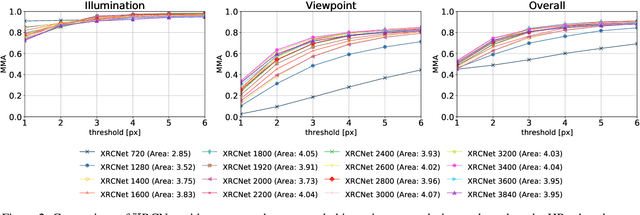
In this paper, we aim at establishing accurate dense correspondences between a pair of images with overlapping field of view under challenging illumination variation, viewpoint changes, and style differences. Through an extensive ablation study of the state-of-the-art correspondence networks, we surprisingly discovered that the widely adopted 4D correlation tensor and its related learning and processing modules could be de-parameterised and removed from training with merely a minor impact over the final matching accuracy. Disabling some of the most memory consuming and computational expensive modules dramatically speeds up the training procedure and allows to use 4x bigger batch size, which in turn compensates for the accuracy drop. Together with a multi-GPU inference stage, our method facilitates the systematic investigation of the relationship between matching accuracy and up-sampling resolution of the native testing images from 720p to 4K. This leads to finding an optimal resolution $\mathbb X$ that produces accurate matching performance surpassing the state-of-the-art methods particularly over the lower error band for the proposed network and evaluation datasets.
A Summary of the 4th International Workshop on Recovering 6D Object Pose
Oct 09, 2018
This document summarizes the 4th International Workshop on Recovering 6D Object Pose which was organized in conjunction with ECCV 2018 in Munich. The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation. The workshop was attended by 100+ people working on relevant topics in both academia and industry who shared up-to-date advances and discussed open problems.
A Learning-based Variable Size Part Extraction Architecture for 6D Object Pose Recovery in Depth
Jan 09, 2017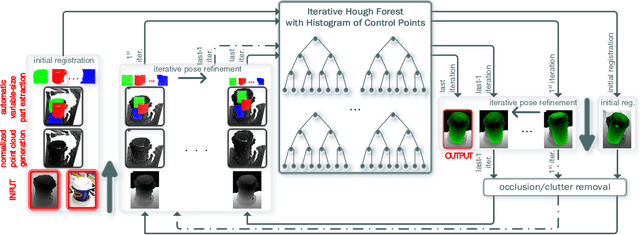
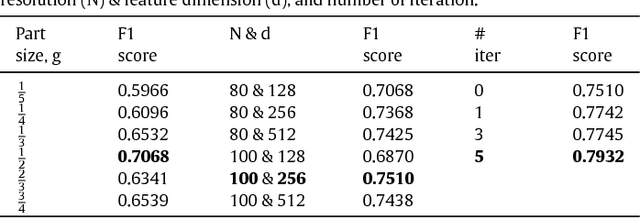
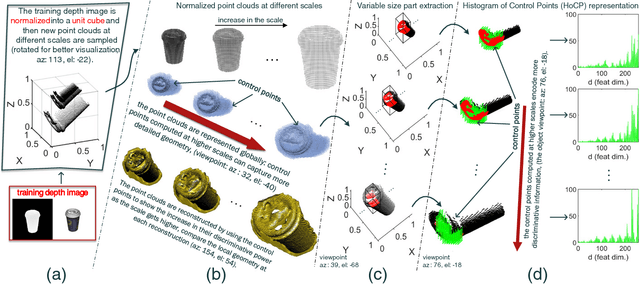
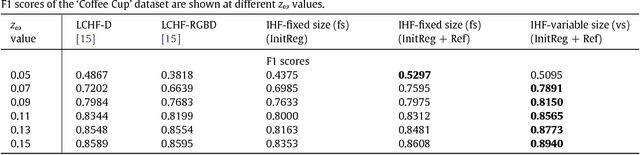
State-of-the-art techniques for 6D object pose recovery depend on occlusion-free point clouds to accurately register objects in 3D space. To deal with this shortcoming, we introduce a novel architecture called Iterative Hough Forest with Histogram of Control Points that is capable of estimating the 6D pose of occluded and cluttered objects given a candidate 2D bounding box. Our Iterative Hough Forest (IHF) is learnt using parts extracted only from the positive samples. These parts are represented with Histogram of Control Points (HoCP), a "scale-variant" implicit volumetric description, which we derive from recently introduced Implicit B-Splines (IBS). The rich discriminative information provided by the scale-variant HoCP features is leveraged during inference. An automatic variable size part extraction framework iteratively refines the object's initial pose that is roughly aligned due to the extraction of coarsest parts, the ones occupying the largest area in image pixels. The iterative refinement is accomplished based on finer (smaller) parts that are represented with more discriminative control point descriptors by using our Iterative Hough Forest. Experiments conducted on a publicly available dataset report that our approach show better registration performance than the state-of-the-art methods.
Iterative Hough Forest with Histogram of Control Points for 6 DoF Object Registration from Depth Images
Jan 09, 2017
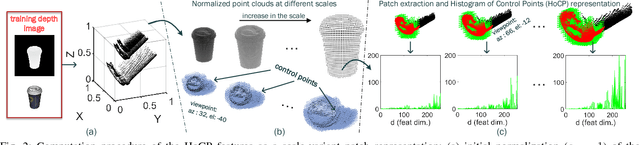
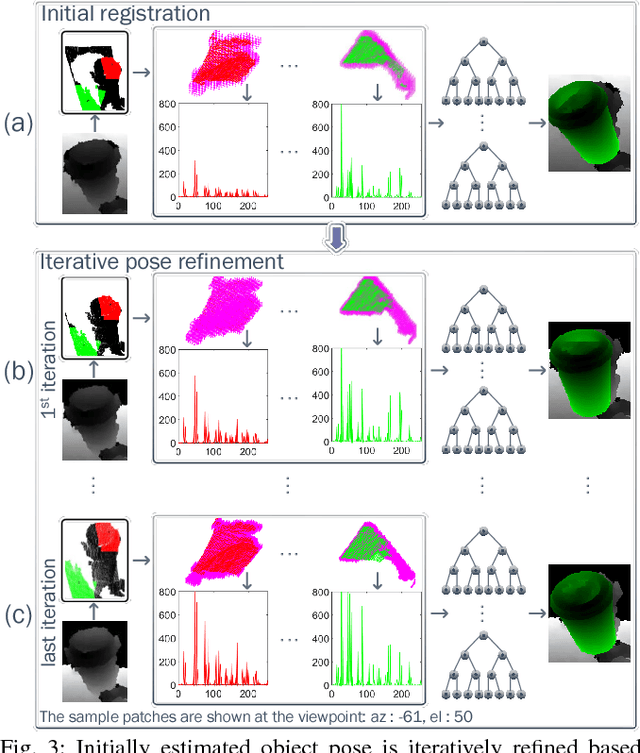
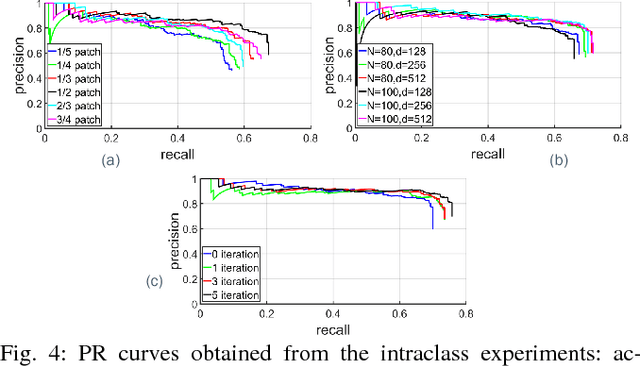
State-of-the-art techniques proposed for 6D object pose recovery depend on occlusion-free point clouds to accurately register objects in 3D space. To reduce this dependency, we introduce a novel architecture called Iterative Hough Forest with Histogram of Control Points that is capable of estimating occluded and cluttered objects' 6D pose given a candidate 2D bounding box. Our Iterative Hough Forest is learnt using patches extracted only from the positive samples. These patches are represented with Histogram of Control Points (HoCP), a "scale-variant" implicit volumetric description, which we derive from recently introduced Implicit B-Splines (IBS). The rich discriminative information provided by this scale-variance is leveraged during inference, where the initial pose estimation of the object is iteratively refined based on more discriminative control points by using our Iterative Hough Forest. We conduct experiments on several test objects of a publicly available dataset to test our architecture and to compare with the state-of-the-art.
Siamese Regression Networks with Efficient mid-level Feature Extraction for 3D Object Pose Estimation
Jul 08, 2016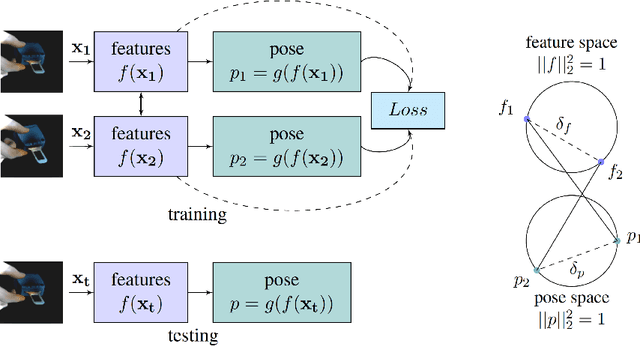

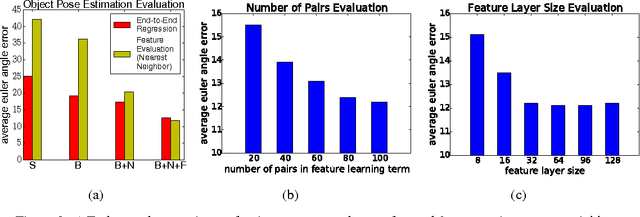

In this paper we tackle the problem of estimating the 3D pose of object instances, using convolutional neural networks. State of the art methods usually solve the challenging problem of regression in angle space indirectly, focusing on learning discriminative features that are later fed into a separate architecture for 3D pose estimation. In contrast, we propose an end-to-end learning framework for directly regressing object poses by exploiting Siamese Networks. For a given image pair, we enforce a similarity measure between the representation of the sample images in the feature and pose space respectively, that is shown to boost regression performance. Furthermore, we argue that our pose-guided feature learning using our Siamese Regression Network generates more discriminative features that outperform the state of the art. Last, our feature learning formulation provides the ability of learning features that can perform under severe occlusions, demonstrating high performance on our novel hand-object dataset.
Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd
Apr 19, 2016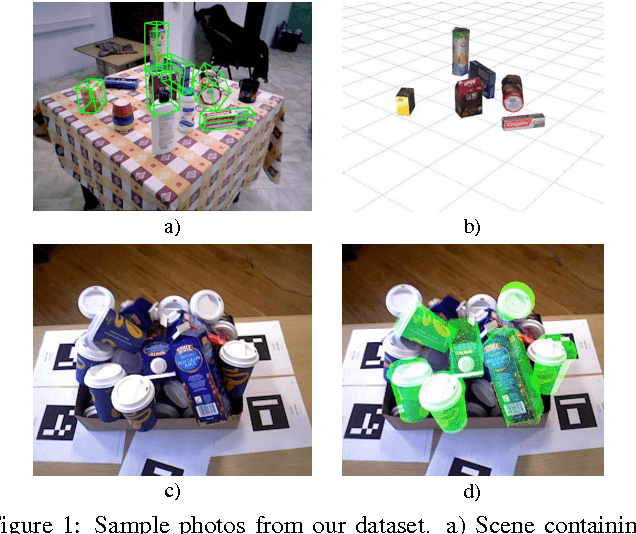
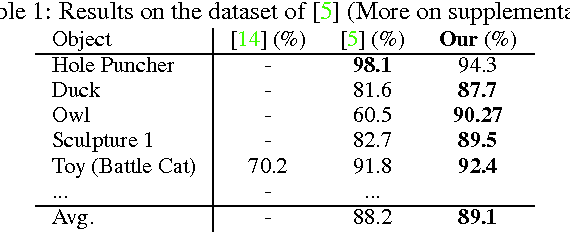
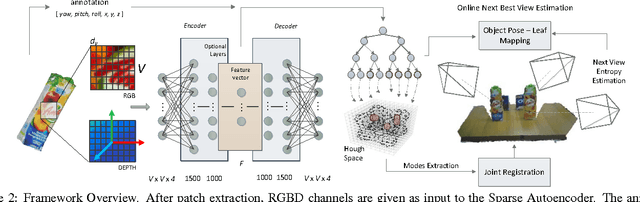

Object detection and 6D pose estimation in the crowd (scenes with multiple object instances, severe foreground occlusions and background distractors), has become an important problem in many rapidly evolving technological areas such as robotics and augmented reality. Single shot-based 6D pose estimators with manually designed features are still unable to tackle the above challenges, motivating the research towards unsupervised feature learning and next-best-view estimation. In this work, we present a complete framework for both single shot-based 6D object pose estimation and next-best-view prediction based on Hough Forests, the state of the art object pose estimator that performs classification and regression jointly. Rather than using manually designed features we a) propose an unsupervised feature learnt from depth-invariant patches using a Sparse Autoencoder and b) offer an extensive evaluation of various state of the art features. Furthermore, taking advantage of the clustering performed in the leaf nodes of Hough Forests, we learn to estimate the reduction of uncertainty in other views, formulating the problem of selecting the next-best-view. To further improve pose estimation, we propose an improved joint registration and hypotheses verification module as a final refinement step to reject false detections. We provide two additional challenging datasets inspired from realistic scenarios to extensively evaluate the state of the art and our framework. One is related to domestic environments and the other depicts a bin-picking scenario mostly found in industrial settings. We show that our framework significantly outperforms state of the art both on public and on our datasets.
Latent-Class Hough Forests for 6 DoF Object Pose Estimation
Feb 03, 2016
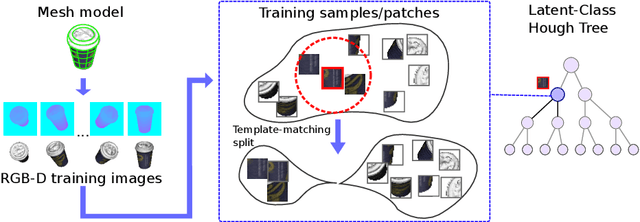
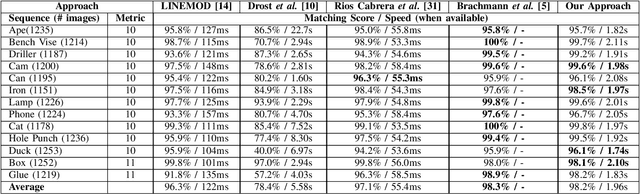
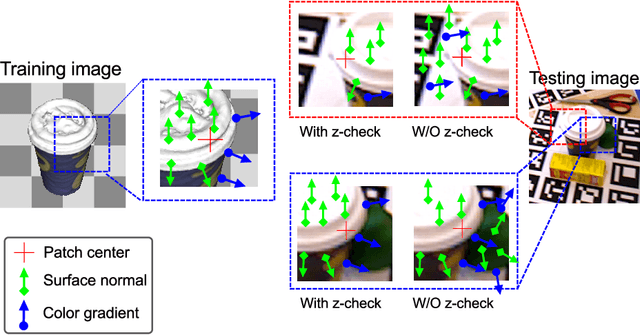
In this paper we present Latent-Class Hough Forests, a method for object detection and 6 DoF pose estimation in heavily cluttered and occluded scenarios. We adapt a state of the art template matching feature into a scale-invariant patch descriptor and integrate it into a regression forest using a novel template-based split function. We train with positive samples only and we treat class distributions at the leaf nodes as latent variables. During testing we infer by iteratively updating these distributions, providing accurate estimation of background clutter and foreground occlusions and, thus, better detection rate. Furthermore, as a by-product, our Latent-Class Hough Forests can provide accurate occlusion aware segmentation masks, even in the multi-instance scenario. In addition to an existing public dataset, which contains only single-instance sequences with large amounts of clutter, we have collected two, more challenging, datasets for multiple-instance detection containing heavy 2D and 3D clutter as well as foreground occlusions. We provide extensive experiments on the various parameters of the framework such as patch size, number of trees and number of iterations to infer class distributions at test time. We also evaluate the Latent-Class Hough Forests on all datasets where we outperform state of the art methods.