 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Siamese Regression Networks with Efficient mid-level Feature Extraction for 3D Object Pose Estimation
Jul 08, 2016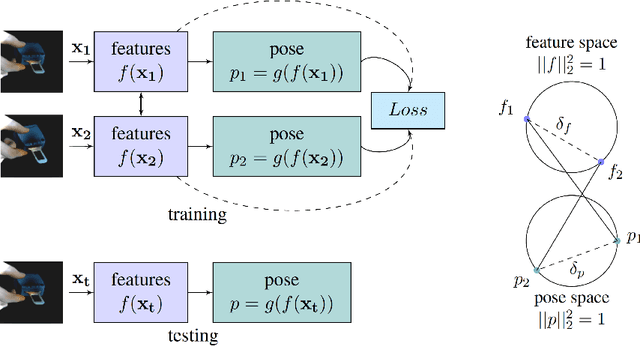

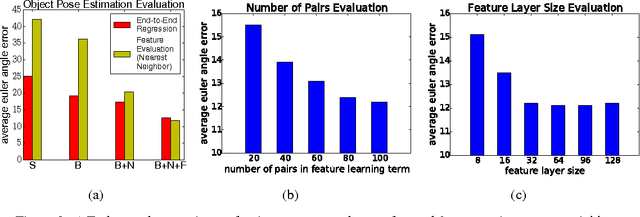

In this paper we tackle the problem of estimating the 3D pose of object instances, using convolutional neural networks. State of the art methods usually solve the challenging problem of regression in angle space indirectly, focusing on learning discriminative features that are later fed into a separate architecture for 3D pose estimation. In contrast, we propose an end-to-end learning framework for directly regressing object poses by exploiting Siamese Networks. For a given image pair, we enforce a similarity measure between the representation of the sample images in the feature and pose space respectively, that is shown to boost regression performance. Furthermore, we argue that our pose-guided feature learning using our Siamese Regression Network generates more discriminative features that outperform the state of the art. Last, our feature learning formulation provides the ability of learning features that can perform under severe occlusions, demonstrating high performance on our novel hand-object dataset.
Recovering 6D Object Pose and Predicting Next-Best-View in the Crowd
Apr 19, 2016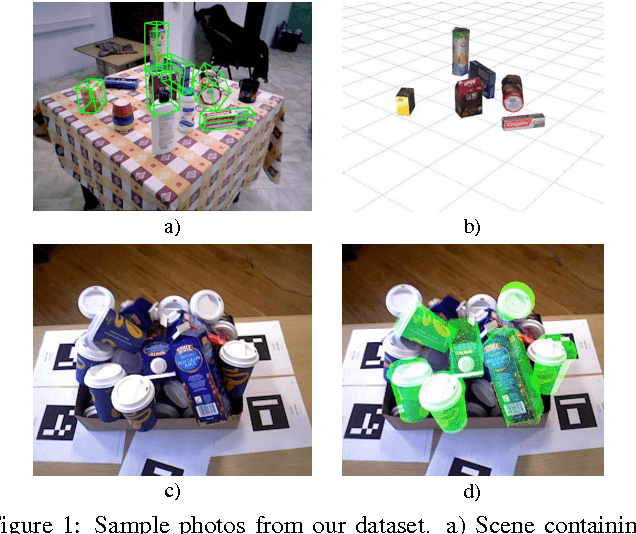
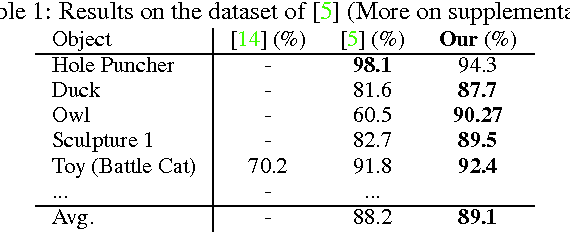
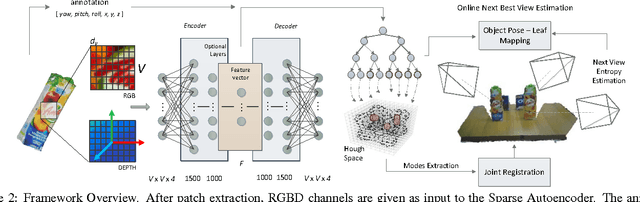

Object detection and 6D pose estimation in the crowd (scenes with multiple object instances, severe foreground occlusions and background distractors), has become an important problem in many rapidly evolving technological areas such as robotics and augmented reality. Single shot-based 6D pose estimators with manually designed features are still unable to tackle the above challenges, motivating the research towards unsupervised feature learning and next-best-view estimation. In this work, we present a complete framework for both single shot-based 6D object pose estimation and next-best-view prediction based on Hough Forests, the state of the art object pose estimator that performs classification and regression jointly. Rather than using manually designed features we a) propose an unsupervised feature learnt from depth-invariant patches using a Sparse Autoencoder and b) offer an extensive evaluation of various state of the art features. Furthermore, taking advantage of the clustering performed in the leaf nodes of Hough Forests, we learn to estimate the reduction of uncertainty in other views, formulating the problem of selecting the next-best-view. To further improve pose estimation, we propose an improved joint registration and hypotheses verification module as a final refinement step to reject false detections. We provide two additional challenging datasets inspired from realistic scenarios to extensively evaluate the state of the art and our framework. One is related to domestic environments and the other depicts a bin-picking scenario mostly found in industrial settings. We show that our framework significantly outperforms state of the art both on public and on our datasets.
Latent-Class Hough Forests for 6 DoF Object Pose Estimation
Feb 03, 2016
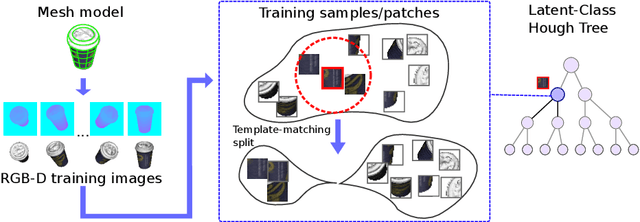
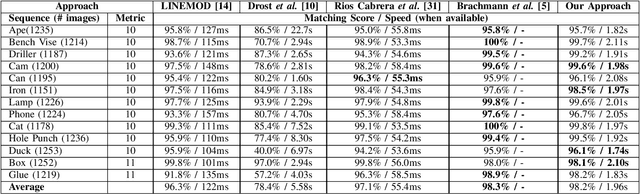
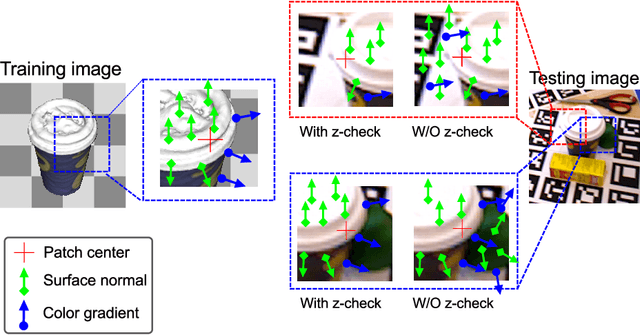
In this paper we present Latent-Class Hough Forests, a method for object detection and 6 DoF pose estimation in heavily cluttered and occluded scenarios. We adapt a state of the art template matching feature into a scale-invariant patch descriptor and integrate it into a regression forest using a novel template-based split function. We train with positive samples only and we treat class distributions at the leaf nodes as latent variables. During testing we infer by iteratively updating these distributions, providing accurate estimation of background clutter and foreground occlusions and, thus, better detection rate. Furthermore, as a by-product, our Latent-Class Hough Forests can provide accurate occlusion aware segmentation masks, even in the multi-instance scenario. In addition to an existing public dataset, which contains only single-instance sequences with large amounts of clutter, we have collected two, more challenging, datasets for multiple-instance detection containing heavy 2D and 3D clutter as well as foreground occlusions. We provide extensive experiments on the various parameters of the framework such as patch size, number of trees and number of iterations to infer class distributions at test time. We also evaluate the Latent-Class Hough Forests on all datasets where we outperform state of the art methods.