 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Embedding 2: A Native Multimodal Embedding Model from Gemini
May 26, 2026We introduce Gemini Embedding 2, a native multimodal embedding model that allows embedding video, audio, image, and text modalities in a unified representation space. We leverage the multimodal capabilities of Gemini to produce embeddings for arbitrary combinations of interleaved inputs across all these modalities that generalize well across a wide variety of tasks. Applying large-scale contrastive learning in a multi-task multi-stage training setup, we achieve state-of-the-art performance on key embedding benchmarks including unimodal, cross-modal, and multimodal retrieval spanning a diverse set of tasks. We show that our embedding model demonstrates strong performance (with a score of 62.9 R@1 on MSCOCO, 68.8 NDCG@10 on Vatex, 69.9 on MTEB multilingual and 84.0 on MTEB Code) across a variety of tasks surpassing the performance of specialized models. These unified capabilities make Gemini Embedding 2 a promising candidate for downstream use cases such as RAG, recommendation and search. Furthermore, its robust zero-shot performance across distinct fields - from astronomy and bioscience to fine arts and the culinary arts - establishes it as a highly reliable, out-of-the-box representation even for specialized domains.
CRISP: Clustering Multi-Vector Representations for Denoising and Pruning
May 16, 2025Multi-vector models, such as ColBERT, are a significant advancement in neural information retrieval (IR), delivering state-of-the-art performance by representing queries and documents by multiple contextualized token-level embeddings. However, this increased representation size introduces considerable storage and computational overheads which have hindered widespread adoption in practice. A common approach to mitigate this overhead is to cluster the model's frozen vectors, but this strategy's effectiveness is fundamentally limited by the intrinsic clusterability of these embeddings. In this work, we introduce CRISP (Clustered Representations with Intrinsic Structure Pruning), a novel multi-vector training method which learns inherently clusterable representations directly within the end-to-end training process. By integrating clustering into the training phase rather than imposing it post-hoc, CRISP significantly outperforms post-hoc clustering at all representation sizes, as well as other token pruning methods. On the BEIR retrieval benchmarks, CRISP achieves a significant rate of ~3x reduction in the number of vectors while outperforming the original unpruned model. This indicates that learned clustering effectively denoises the model by filtering irrelevant information, thereby generating more robust multi-vector representations. With more aggressive clustering, CRISP achieves an 11x reduction in the number of vectors with only a $3.6\%$ quality loss.
Gemini Embedding: Generalizable Embeddings from Gemini
Mar 10, 2025In this report, we introduce Gemini Embedding, a state-of-the-art embedding model leveraging the power of Gemini, Google's most capable large language model. Capitalizing on Gemini's inherent multilingual and code understanding capabilities, Gemini Embedding produces highly generalizable embeddings for text spanning numerous languages and textual modalities. The representations generated by Gemini Embedding can be precomputed and applied to a variety of downstream tasks including classification, similarity, clustering, ranking, and retrieval. Evaluated on the Massive Multilingual Text Embedding Benchmark (MMTEB), which includes over one hundred tasks across 250+ languages, Gemini Embedding substantially outperforms prior state-of-the-art models, demonstrating considerable improvements in embedding quality. Achieving state-of-the-art performance across MMTEB's multilingual, English, and code benchmarks, our unified model demonstrates strong capabilities across a broad selection of tasks and surpasses specialized domain-specific models.
Leveraging LLMs for Synthesizing Training Data Across Many Languages in Multilingual Dense Retrieval
Nov 10, 2023



Dense retrieval models have predominantly been studied for English, where models have shown great success, due to the availability of human-labeled training pairs. However, there has been limited success for multilingual retrieval so far, as training data is uneven or scarcely available across multiple languages. Synthetic training data generation is promising (e.g., InPars or Promptagator), but has been investigated only for English. Therefore, to study model capabilities across both cross-lingual and monolingual retrieval tasks, we develop SWIM-IR, a synthetic retrieval training dataset containing 33 (high to very-low resource) languages for training multilingual dense retrieval models without requiring any human supervision. To construct SWIM-IR, we propose SAP (summarize-then-ask prompting), where the large language model (LLM) generates a textual summary prior to the query generation step. SAP assists the LLM in generating informative queries in the target language. Using SWIM-IR, we explore synthetic fine-tuning of multilingual dense retrieval models and evaluate them robustly on three retrieval benchmarks: XOR-Retrieve (cross-lingual), XTREME-UP (cross-lingual) and MIRACL (monolingual). Our models, called SWIM-X, are competitive with human-supervised dense retrieval models, e.g., mContriever, finding that SWIM-IR can cheaply substitute for expensive human-labeled retrieval training data.
Large Dual Encoders Are Generalizable Retrievers
Dec 15, 2021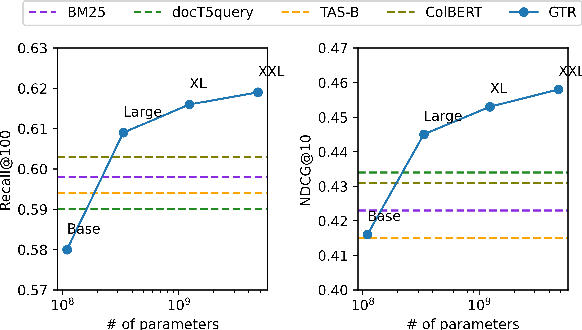
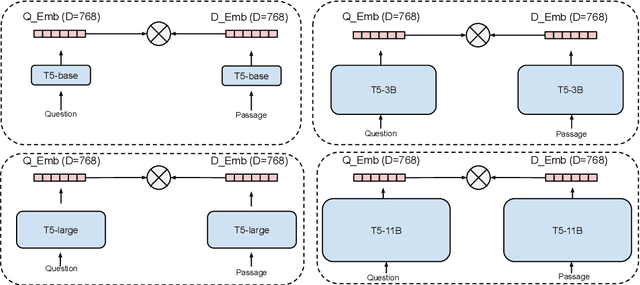

It has been shown that dual encoders trained on one domain often fail to generalize to other domains for retrieval tasks. One widespread belief is that the bottleneck layer of a dual encoder, where the final score is simply a dot-product between a query vector and a passage vector, is too limited to make dual encoders an effective retrieval model for out-of-domain generalization. In this paper, we challenge this belief by scaling up the size of the dual encoder model {\em while keeping the bottleneck embedding size fixed.} With multi-stage training, surprisingly, scaling up the model size brings significant improvement on a variety of retrieval tasks, especially for out-of-domain generalization. Experimental results show that our dual encoders, \textbf{G}eneralizable \textbf{T}5-based dense \textbf{R}etrievers (GTR), outperform %ColBERT~\cite{khattab2020colbert} and existing sparse and dense retrievers on the BEIR dataset~\cite{thakur2021beir} significantly. Most surprisingly, our ablation study finds that GTR is very data efficient, as it only needs 10\% of MS Marco supervised data to achieve the best out-of-domain performance. All the GTR models are released at https://tfhub.dev/google/collections/gtr/1.
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models
Aug 26, 2021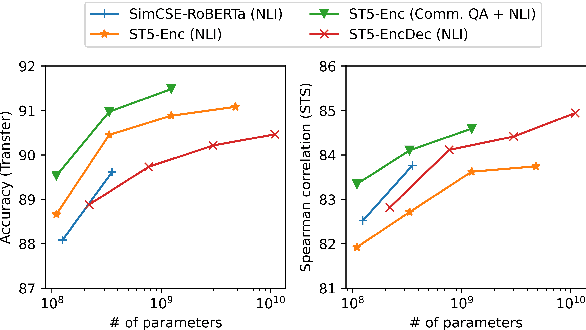
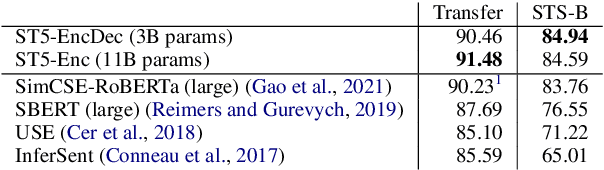
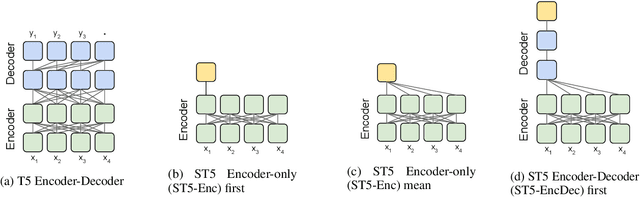
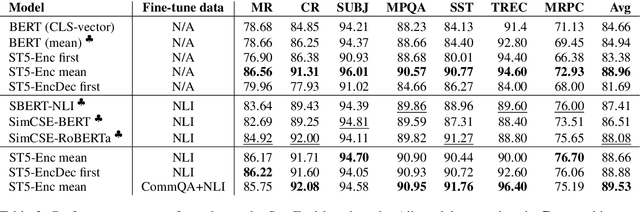
We provide the first exploration of text-to-text transformers (T5) sentence embeddings. Sentence embeddings are broadly useful for language processing tasks. While T5 achieves impressive performance on language tasks cast as sequence-to-sequence mapping problems, it is unclear how to produce sentence embeddings from encoder-decoder models. We investigate three methods for extracting T5 sentence embeddings: two utilize only the T5 encoder and one uses the full T5 encoder-decoder model. Our encoder-only models outperforms BERT-based sentence embeddings on both transfer tasks and semantic textual similarity (STS). Our encoder-decoder method achieves further improvement on STS. Scaling up T5 from millions to billions of parameters is found to produce consistent improvements on downstream tasks. Finally, we introduce a two-stage contrastive learning approach that achieves a new state-of-art on STS using sentence embeddings, outperforming both Sentence BERT and SimCSE.