 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforced Attention Learning
Feb 04, 2026Post-training with Reinforcement Learning (RL) has substantially improved reasoning in Large Language Models (LLMs) via test-time scaling. However, extending this paradigm to Multimodal LLMs (MLLMs) through verbose rationales yields limited gains for perception and can even degrade performance. We propose Reinforced Attention Learning (RAL), a policy-gradient framework that directly optimizes internal attention distributions rather than output token sequences. By shifting optimization from what to generate to where to attend, RAL promotes effective information allocation and improved grounding in complex multimodal inputs. Experiments across diverse image and video benchmarks show consistent gains over GRPO and other baselines. We further introduce On-Policy Attention Distillation, demonstrating that transferring latent attention behaviors yields stronger cross-modal alignment than standard knowledge distillation. Our results position attention policies as a principled and general alternative for multimodal post-training.
FedMCP: Parameter-Efficient Federated Learning with Model-Contrastive Personalization
Aug 28, 2024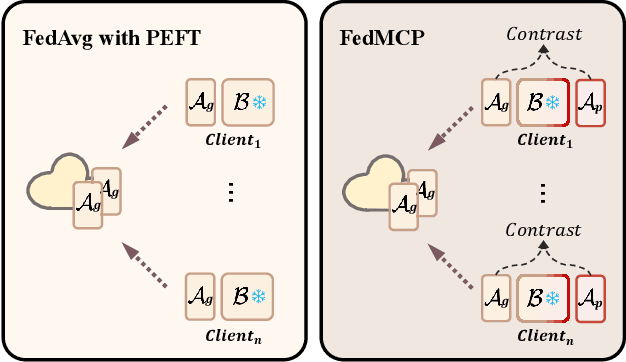
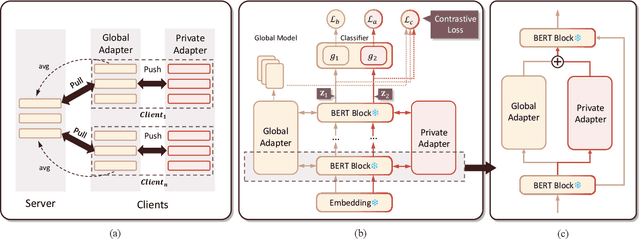
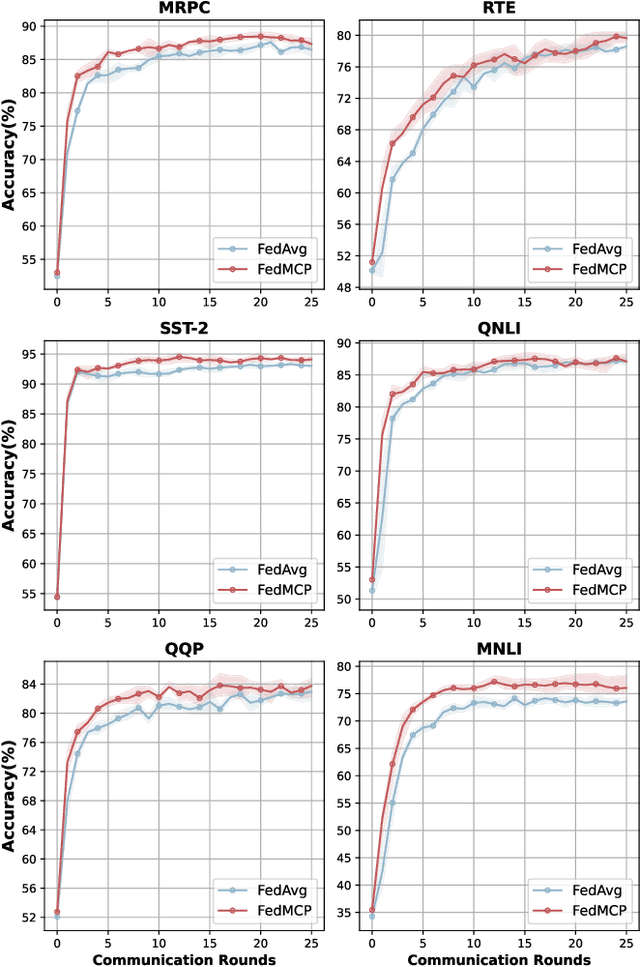
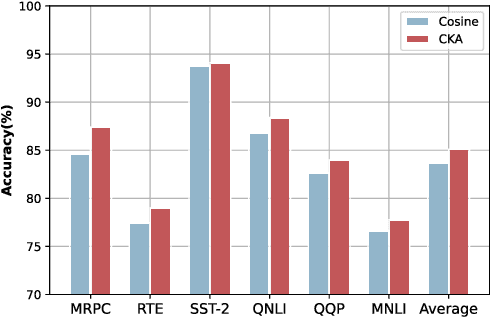
With increasing concerns and regulations on data privacy, fine-tuning pretrained language models (PLMs) in federated learning (FL) has become a common paradigm for NLP tasks. Despite being extensively studied, the existing methods for this problem still face two primary challenges. First, the huge number of parameters in large-scale PLMs leads to excessive communication and computational overhead. Second, the heterogeneity of data and tasks across clients poses a significant obstacle to achieving the desired fine-tuning performance. To address the above problems, we propose FedMCP, a novel parameter-efficient fine-tuning method with model-contrastive personalization for FL. Specifically, FedMCP adds two lightweight adapter modules, i.e., the global adapter and the private adapter, to the frozen PLMs within clients. In a communication round, each client sends only the global adapter to the server for federated aggregation. Furthermore, FedMCP introduces a model-contrastive regularization term between the two adapters. This, on the one hand, encourages the global adapter to assimilate universal knowledge and, on the other hand, the private adapter to capture client-specific knowledge. By leveraging both adapters, FedMCP can effectively provide fine-tuned personalized models tailored to individual clients. Extensive experiments on highly heterogeneous cross-task, cross-silo datasets show that FedMCP achieves substantial performance improvements over state-of-the-art FL fine-tuning approaches for PLMs.
Aligning Query Representation with Rewritten Query and Relevance Judgments in Conversational Search
Jul 29, 2024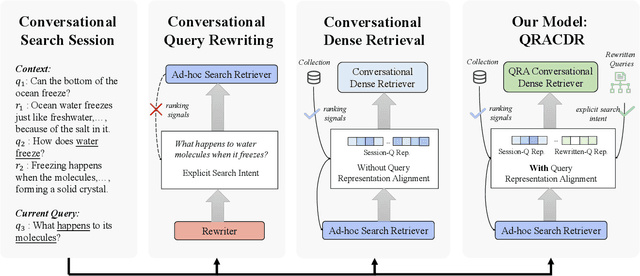
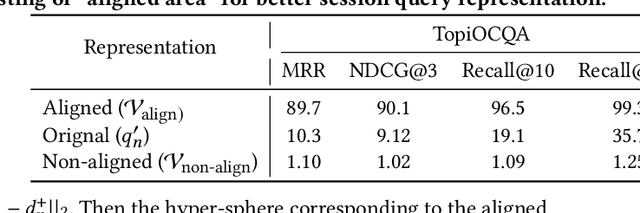
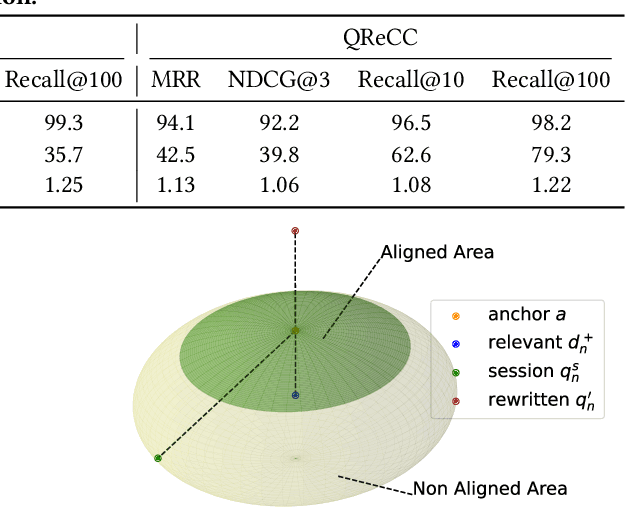

Conversational search supports multi-turn user-system interactions to solve complex information needs. Different from the traditional single-turn ad-hoc search, conversational search encounters a more challenging problem of context-dependent query understanding with the lengthy and long-tail conversational history context. While conversational query rewriting methods leverage explicit rewritten queries to train a rewriting model to transform the context-dependent query into a stand-stone search query, this is usually done without considering the quality of search results. Conversational dense retrieval methods use fine-tuning to improve a pre-trained ad-hoc query encoder, but they are limited by the conversational search data available for training. In this paper, we leverage both rewritten queries and relevance judgments in the conversational search data to train a better query representation model. The key idea is to align the query representation with those of rewritten queries and relevant documents. The proposed model -- Query Representation Alignment Conversational Dense Retriever, QRACDR, is tested on eight datasets, including various settings in conversational search and ad-hoc search. The results demonstrate the strong performance of QRACDR compared with state-of-the-art methods, and confirm the effectiveness of representation alignment.
ConvSDG: Session Data Generation for Conversational Search
Mar 17, 2024



Conversational search provides a more convenient interface for users to search by allowing multi-turn interaction with the search engine. However, the effectiveness of the conversational dense retrieval methods is limited by the scarcity of training data required for their fine-tuning. Thus, generating more training conversational sessions with relevant labels could potentially improve search performance. Based on the promising capabilities of large language models (LLMs) on text generation, we propose ConvSDG, a simple yet effective framework to explore the feasibility of boosting conversational search by using LLM for session data generation. Within this framework, we design dialogue/session-level and query-level data generation with unsupervised and semi-supervised learning, according to the availability of relevance judgments. The generated data are used to fine-tune the conversational dense retriever. Extensive experiments on four widely used datasets demonstrate the effectiveness and broad applicability of our ConvSDG framework compared with several strong baselines.
History-Aware Conversational Dense Retrieval
Jan 30, 2024



Conversational search facilitates complex information retrieval by enabling multi-turn interactions between users and the system. Supporting such interactions requires a comprehensive understanding of the conversational inputs to formulate a good search query based on historical information. In particular, the search query should include the relevant information from the previous conversation turns. However, current approaches for conversational dense retrieval primarily rely on fine-tuning a pre-trained ad-hoc retriever using the whole conversational search session, which can be lengthy and noisy. Moreover, existing approaches are limited by the amount of manual supervision signals in the existing datasets. To address the aforementioned issues, we propose a History-Aware Conversational Dense Retrieval (HAConvDR) system, which incorporates two ideas: context-denoised query reformulation and automatic mining of supervision signals based on the actual impact of historical turns. Experiments on two public conversational search datasets demonstrate the improved history modeling capability of HAConvDR, in particular for long conversations with topic shifts.
Exploring Dual Encoder Architectures for Question Answering
Apr 14, 2022
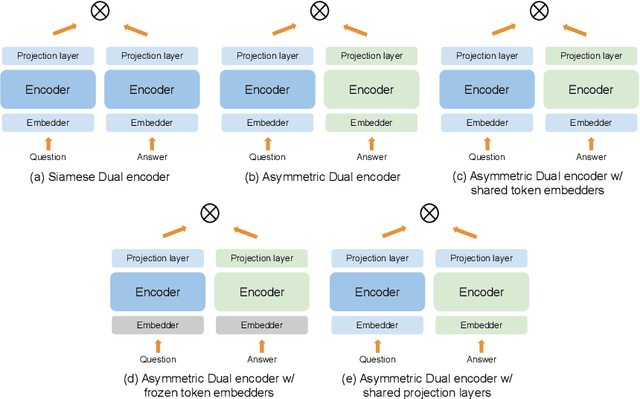
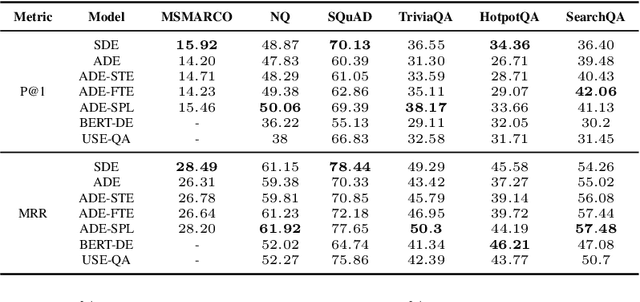

Dual encoders have been used for question-answering (QA) and information retrieval (IR) tasks with good results. There are two major types of dual encoders, Siamese Dual Encoders (SDE), with parameters shared across two encoders, and Asymmetric Dual Encoder (ADE), with two distinctly parameterized encoders. In this work, we explore the dual encoder architectures for QA retrieval tasks. By evaluating on MS MARCO and the MultiReQA benchmark, we show that SDE performs significantly better than ADE. We further propose three different improved versions of ADEs. Based on the evaluation of QA retrieval tasks and direct analysis of the embeddings, we demonstrate that sharing parameters in projection layers would enable ADEs to perform competitively with SDEs.
Large Dual Encoders Are Generalizable Retrievers
Dec 15, 2021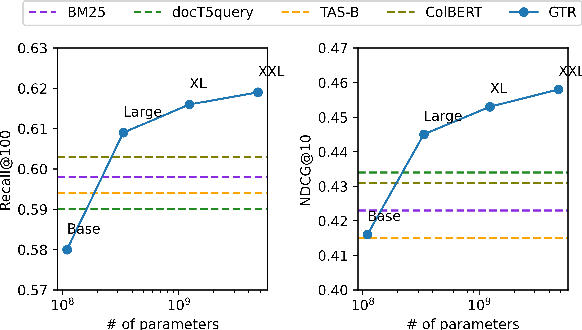
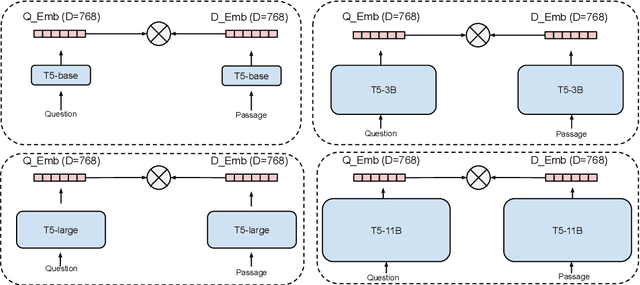

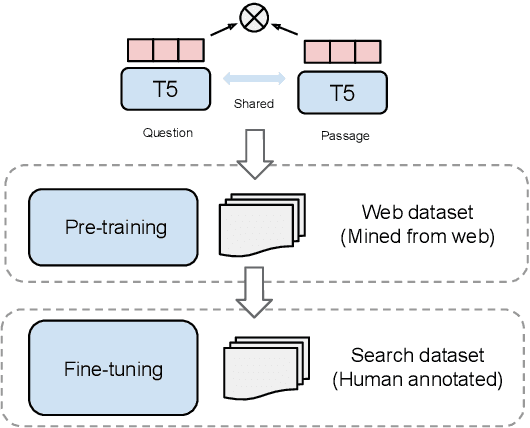
It has been shown that dual encoders trained on one domain often fail to generalize to other domains for retrieval tasks. One widespread belief is that the bottleneck layer of a dual encoder, where the final score is simply a dot-product between a query vector and a passage vector, is too limited to make dual encoders an effective retrieval model for out-of-domain generalization. In this paper, we challenge this belief by scaling up the size of the dual encoder model {\em while keeping the bottleneck embedding size fixed.} With multi-stage training, surprisingly, scaling up the model size brings significant improvement on a variety of retrieval tasks, especially for out-of-domain generalization. Experimental results show that our dual encoders, \textbf{G}eneralizable \textbf{T}5-based dense \textbf{R}etrievers (GTR), outperform %ColBERT~\cite{khattab2020colbert} and existing sparse and dense retrievers on the BEIR dataset~\cite{thakur2021beir} significantly. Most surprisingly, our ablation study finds that GTR is very data efficient, as it only needs 10\% of MS Marco supervised data to achieve the best out-of-domain performance. All the GTR models are released at https://tfhub.dev/google/collections/gtr/1.
Passage Retrieval for Outside-Knowledge Visual Question Answering
May 09, 2021

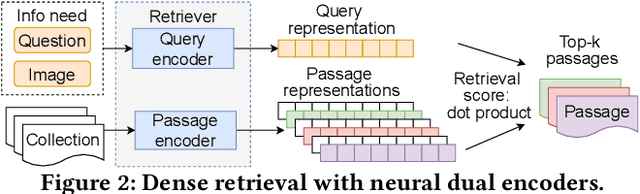
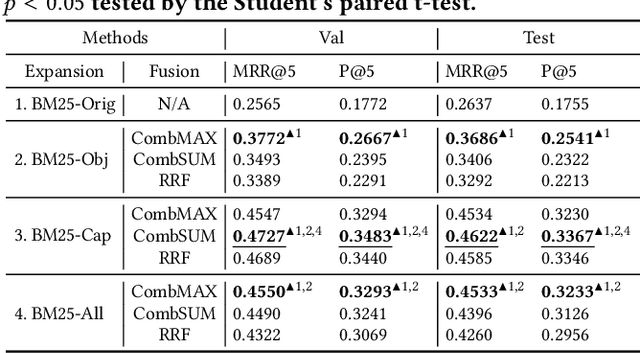
In this work, we address multi-modal information needs that contain text questions and images by focusing on passage retrieval for outside-knowledge visual question answering. This task requires access to outside knowledge, which in our case we define to be a large unstructured passage collection. We first conduct sparse retrieval with BM25 and study expanding the question with object names and image captions. We verify that visual clues play an important role and captions tend to be more informative than object names in sparse retrieval. We then construct a dual-encoder dense retriever, with the query encoder being LXMERT, a multi-modal pre-trained transformer. We further show that dense retrieval significantly outperforms sparse retrieval that uses object expansion. Moreover, dense retrieval matches the performance of sparse retrieval that leverages human-generated captions.
Privacy-Adaptive BERT for Natural Language Understanding
Apr 15, 2021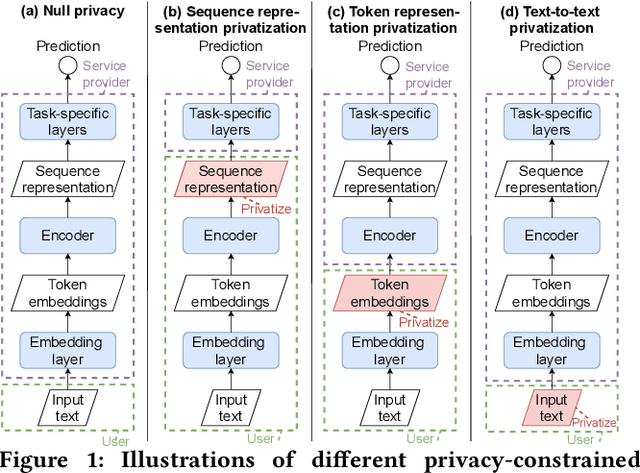
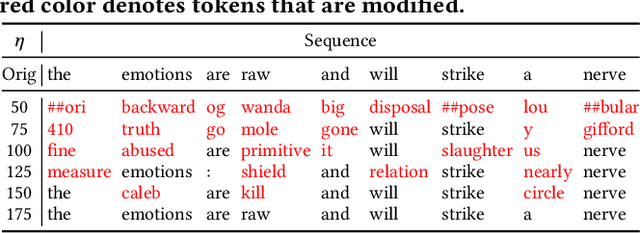
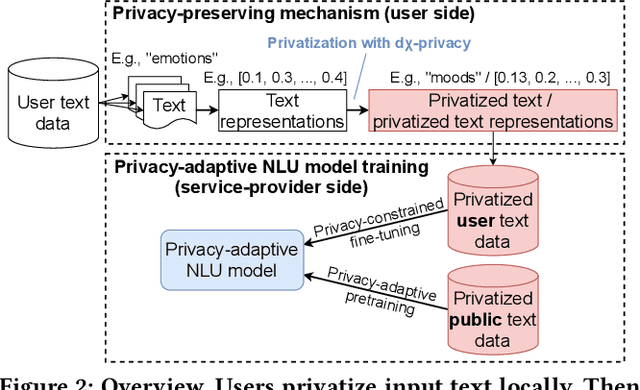
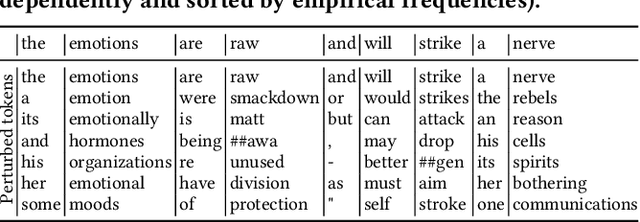
When trying to apply the recent advance of Natural Language Understanding (NLU) technologies to real-world applications, privacy preservation imposes a crucial challenge, which, unfortunately, has not been well resolved. To address this issue, we study how to improve the effectiveness of NLU models under a Local Privacy setting, using BERT, a widely-used pretrained Language Model (LM), as an example. We systematically study the strengths and weaknesses of imposing dx-privacy, a relaxed variant of Local Differential Privacy, at different stages of language modeling: input text, token embeddings, and sequence representations. We then focus on the former two with privacy-constrained fine-tuning experiments to reveal the utility of BERT under local privacy constraints. More importantly, to the best of our knowledge, we are the first to propose privacy-adaptive LM pretraining methods and demonstrate that they can significantly improve model performance on privatized text input. We also interpret the level of privacy preservation and provide our guidance on privacy parameter selections.
Weakly-Supervised Open-Retrieval Conversational Question Answering
Mar 03, 2021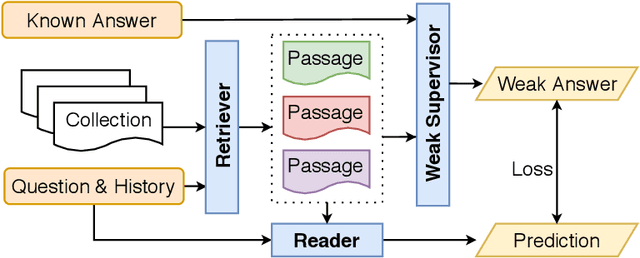
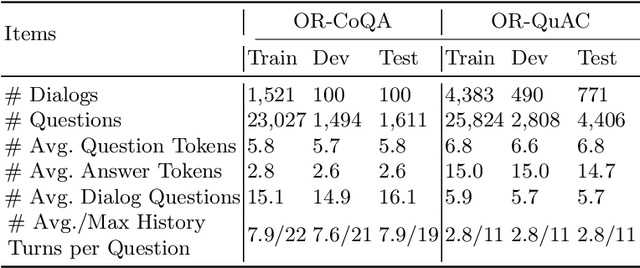
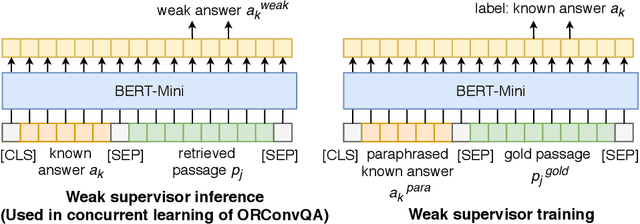
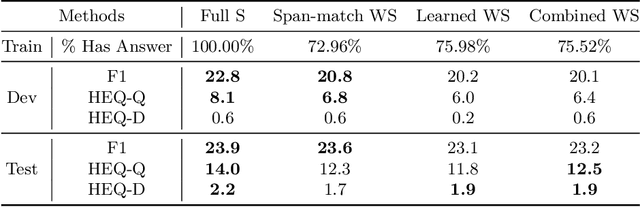
Recent studies on Question Answering (QA) and Conversational QA (ConvQA) emphasize the role of retrieval: a system first retrieves evidence from a large collection and then extracts answers. This open-retrieval ConvQA setting typically assumes that each question is answerable by a single span of text within a particular passage (a span answer). The supervision signal is thus derived from whether or not the system can recover an exact match of this ground-truth answer span from the retrieved passages. This method is referred to as span-match weak supervision. However, information-seeking conversations are challenging for this span-match method since long answers, especially freeform answers, are not necessarily strict spans of any passage. Therefore, we introduce a learned weak supervision approach that can identify a paraphrased span of the known answer in a passage. Our experiments on QuAC and CoQA datasets show that the span-match weak supervisor can only handle conversations with span answers, and has less satisfactory results for freeform answers generated by people. Our method is more flexible as it can handle both span answers and freeform answers. Moreover, our method can be more powerful when combined with the span-match method which shows it is complementary to the span-match method. We also conduct in-depth analyses to show more insights on open-retrieval ConvQA under a weak supervision setting.