 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond English: Uncovering the Multilingual Gap in Vision-Language-Action Models
Jun 14, 2026Vision-Language-Action models have recently demonstrated promising capabilities in learning generalist robot policies from large-scale multimodal data. However, most existing VLA systems are trained and evaluated primarily with English instructions, leaving their ability to understand and execute instructions in other languages largely unexplored. While the underlying large language models often possess multilingual capabilities, it remains unclear whether these multilingual capabilities transfer to VLAs during training. In this work, we present the first systematic study of multilingual instruction following in VLA models. We first construct multilingual instructions by extending existing benchmarks with translations of their instructions. Using these instructions, we evaluate several representative VLA models across a range of tasks in simulation settings. Our experiments reveal a significant multilingual gap: models trained primarily on English instructions exhibit substantial performance degradation when evaluated on other languages, even when the underlying language backbone is multilingual. We provide several findings and analyses to understand the multilingual gap. Cross-lingual transfer behavior analysis shows that performance drops correlate with both instruction understanding and action execution. Representation analyses suggest that multilingual instruction-caused representation shifts may contribute to the multilingual gap. Motivated by these findings, we further explore strategies to improve multilingual performance in VLAs. We propose a simple yet effective multilingual fine-tuning approach, Multilingual Principal Component Alignment, which leverages Principal Component Analysis to get the principal component subspace and align projected multilingual representations, effectively reducing the multilingual performance gap.
UniScale: Adaptive Unified Inference Scaling via Online Joint Optimization of Model Routing and Test-Time Scaling
May 29, 2026In real-world deployments of large language models (LLMs), balancing inference quality and computational cost has become a central challenge. Existing approaches tackle this trade-off along two largely independent dimensions: model routing, which switches among models of different scales to match request complexity, and test-time scaling (TTS), which adjusts inference-time compute within a fixed model for fine-grained control. However, this decoupled design introduces inherent limitations. Model routing yields coarse-grained, discrete performance changes due to the sparse set of model scales, while single-model TTS often encounters capacity ceilings and exhibits diminishing returns as compute increases. Moreover, treating the two mechanisms separately restricts adaptability in dynamic inference environments. To overcome these limitations, we introduce Unified Inference Scaling (UIS), which unifies model routing and TTS in a single optimization space. Building on this formulation, we propose UniScale, an online framework that models adaptive UIS as a contextual multi-armed bandit problem and learns inference policies via LinUCB. The framework incorporates efficiency-aware learning and cost modeling to ensure stable and scalable optimization over high-dimensional action spaces. Evaluation shows that UniScale effectively exploits the synergy in the UIS space to deliver a fine-grained and consistently better quality-cost trade-off across diverse, dynamic inference scenarios.
CroSearch-R1: Better Leveraging Cross-lingual Knowledge for Retrieval-Augmented Generation
Apr 28, 2026A multilingual collection may contain useful knowledge in other languages to supplement and correct the facts in the original language for Retrieval-Augmented Generation (RAG). However, the vanilla approach that simply concatenates multiple pieces of knowledge from different languages into the context may fail to improve effectiveness due to the potential disparities across languages. To better leverage multilingual knowledge, we propose CroSearch-R1, a search-augmented reinforcement learning framework to integrate multilingual knowledge into the Group Relative Policy Optimization (GRPO) process. In particular, the approach adopts a multi-turn retrieval strategy with cross-lingual knowledge integration to dynamically align the knowledge from other languages as supplementary evidence into a unified representation space. Furthermore, we introduce a multilingual rollout mechanism to optimize reasoning transferability across languages. Experimental results demonstrate that our framework effectively leverages cross-lingual complementarity and improves the effectiveness of RAG with multilingual collections.
Multi-Aspect Knowledge Distillation for Language Model with Low-rank Factorization
Apr 03, 2026Knowledge distillation is an effective technique for pre-trained language model compression. However, existing methods only focus on the knowledge distribution among layers, which may cause the loss of fine-grained information in the alignment process. To address this issue, we introduce the Multi-aspect Knowledge Distillation (MaKD) method, which mimics the self-attention and feed-forward modules in greater depth to capture rich language knowledge information at different aspects. Experimental results demonstrate that MaKD can achieve competitive performance compared with various strong baselines with the same storage parameter budget. In addition, our method also performs well in distilling auto-regressive architecture models.
Imagination Helps Visual Reasoning, But Not Yet in Latent Space
Feb 26, 2026Latent visual reasoning aims to mimic human's imagination process by meditating through hidden states of Multimodal Large Language Models. While recognized as a promising paradigm for visual reasoning, the underlying mechanisms driving its effectiveness remain unclear. Motivated to demystify the true source of its efficacy, we investigate the validity of latent reasoning using Causal Mediation Analysis. We model the process as a causal chain: the input as the treatment, the latent tokens as the mediator, and the final answer as the outcome. Our findings uncover two critical disconnections: (a) Input-Latent Disconnect: dramatic perturbations on the input result in negligible changes to the latent tokens, suggesting that latent tokens do not effectively attend to the input sequence. (b) Latent-Answer Disconnect: perturbations on the latent tokens yield minimal impact on the final answer, indicating the limited causal effect latent tokens imposing on the outcome. Furthermore, extensive probing analysis reveals that latent tokens encode limited visual information and exhibit high similarity. Consequently, we challenge the necessity of latent reasoning and propose a straightforward alternative named CapImagine, which teaches the model to explicitly imagine using text. Experiments on vision-centric benchmarks show that CapImagine significantly outperforms complex latent-space baselines, highlighting the superior potential of visual reasoning through explicit imagination.
Workflow-R1: Group Sub-sequence Policy Optimization for Multi-turn Workflow Construction
Feb 01, 2026The rapid evolution of agentic workflows has demonstrated strong performance of LLM-based agents in addressing complex reasoning tasks. However, existing workflow optimization methods typically formulate workflow synthesis as a static, one-shot code-centric generation problem. This paradigm imposes excessive constraints on the model's coding capabilities and restricts the flexibility required for dynamic problem-solving. In this paper, we present Workflow-R1, a framework that reformulates workflow construction as a multi-turn, natural language-based sequential decision-making process. To resolve the optimization granularity mismatch inherent in such multi-turn interactions, we introduce Group Sub-sequence Policy Optimization (GSsPO). While explicitly tailored to align with the interleaved Think-Action dynamics of agentic reasoning, GSsPO fundamentally functions as a structure-aware RL algorithm generalizable to a broad class of multi-turn agentic sequential decision-making tasks. By recalibrating the optimization unit to the composite sub-sequence, specifically the atomic Think-Action cycle, it aligns gradient updates with the semantic boundaries of these interactions, ensuring robust learning in complex multi-turn reasoning tasks. Through extensive experiments on multiple QA benchmarks, Workflow-R1 outperforms competitive baselines, validating GSsPO as a generalized solution for sequential reasoning and establishing Workflow-R1 as a promising new paradigm for automated workflow optimization.
Language-Coupled Reinforcement Learning for Multilingual Retrieval-Augmented Generation
Jan 21, 2026Multilingual retrieval-augmented generation (MRAG) requires models to effectively acquire and integrate beneficial external knowledge from multilingual collections. However, most existing studies employ a unitive process where queries of equivalent semantics across different languages are processed through a single-turn retrieval and subsequent optimization. Such a ``one-size-fits-all'' strategy is often suboptimal in multilingual settings, as the models occur to knowledge bias and conflict during the interaction with the search engine. To alleviate the issues, we propose LcRL, a multilingual search-augmented reinforcement learning framework that integrates a language-coupled Group Relative Policy Optimization into the policy and reward models. We adopt the language-coupled group sampling in the rollout module to reduce knowledge bias, and regularize an auxiliary anti-consistency penalty in the reward models to mitigate the knowledge conflict. Experimental results demonstrate that LcRL not only achieves competitive performance but is also appropriate for various practical scenarios such as constrained training data and retrieval over collections encompassing a large number of languages. Our code is available at https://github.com/Cherry-qwq/LcRL-Open.
When Helpers Become Hazards: A Benchmark for Analyzing Multimodal LLM-Powered Safety in Daily Life
Jan 07, 2026As Multimodal Large Language Models (MLLMs) become an indispensable assistant in human life, the unsafe content generated by MLLMs poses a danger to human behavior, perpetually overhanging human society like a sword of Damocles. To investigate and evaluate the safety impact of MLLMs responses on human behavior in daily life, we introduce SaLAD, a multimodal safety benchmark which contains 2,013 real-world image-text samples across 10 common categories, with a balanced design covering both unsafe scenarios and cases of oversensitivity. It emphasizes realistic risk exposure, authentic visual inputs, and fine-grained cross-modal reasoning, ensuring that safety risks cannot be inferred from text alone. We further propose a safety-warning-based evaluation framework that encourages models to provide clear and informative safety warnings, rather than generic refusals. Results on 18 MLLMs demonstrate that the top-performing models achieve a safe response rate of only 57.2% on unsafe queries. Moreover, even popular safety alignment methods limit effectiveness of the models in our scenario, revealing the vulnerabilities of current MLLMs in identifying dangerous behaviors in daily life. Our dataset is available at https://github.com/xinyuelou/SaLAD.
Think Natively: Unlocking Multilingual Reasoning with Consistency-Enhanced Reinforcement Learning
Oct 08, 2025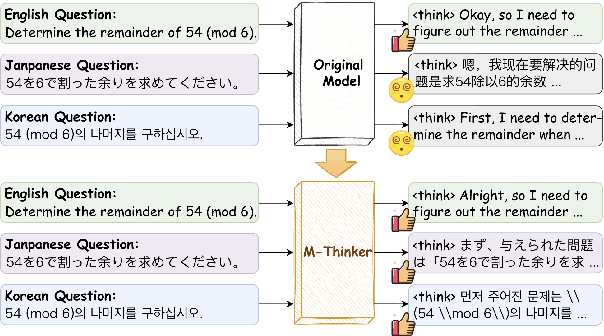
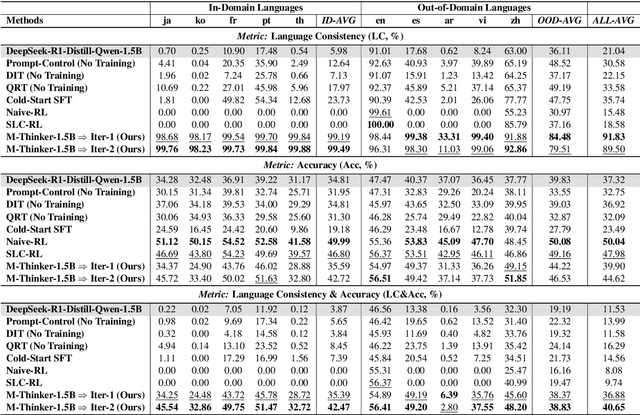
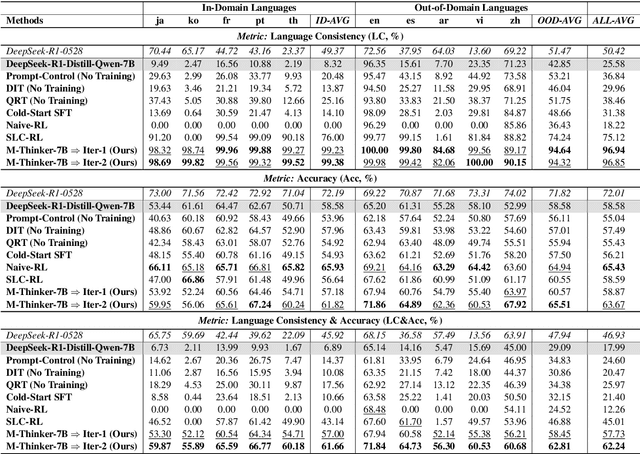

Large Reasoning Models (LRMs) have achieved remarkable performance on complex reasoning tasks by adopting the "think-then-answer" paradigm, which enhances both accuracy and interpretability. However, current LRMs exhibit two critical limitations when processing non-English languages: (1) They often struggle to maintain input-output language consistency; (2) They generally perform poorly with wrong reasoning paths and lower answer accuracy compared to English. These limitations significantly degrade the user experience for non-English speakers and hinder the global deployment of LRMs. To address these limitations, we propose M-Thinker, which is trained by the GRPO algorithm that involves a Language Consistency (LC) reward and a novel Cross-lingual Thinking Alignment (CTA) reward. Specifically, the LC reward defines a strict constraint on the language consistency between the input, thought, and answer. Besides, the CTA reward compares the model's non-English reasoning paths with its English reasoning path to transfer its own reasoning capability from English to non-English languages. Through an iterative RL procedure, our M-Thinker-1.5B/7B models not only achieve nearly 100% language consistency and superior performance on two multilingual benchmarks (MMATH and PolyMath), but also exhibit excellent generalization on out-of-domain languages.
Boosting Data Utilization for Multilingual Dense Retrieval
Sep 11, 2025Multilingual dense retrieval aims to retrieve relevant documents across different languages based on a unified retriever model. The challenge lies in aligning representations of different languages in a shared vector space. The common practice is to fine-tune the dense retriever via contrastive learning, whose effectiveness highly relies on the quality of the negative sample and the efficacy of mini-batch data. Different from the existing studies that focus on developing sophisticated model architecture, we propose a method to boost data utilization for multilingual dense retrieval by obtaining high-quality hard negative samples and effective mini-batch data. The extensive experimental results on a multilingual retrieval benchmark, MIRACL, with 16 languages demonstrate the effectiveness of our method by outperforming several existing strong baselines.