 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniGeo: Towards a Multimodal Large Language Models for Geospatial Artificial Intelligence
Mar 20, 2025The rapid advancement of multimodal large language models (LLMs) has opened new frontiers in artificial intelligence, enabling the integration of diverse large-scale data types such as text, images, and spatial information. In this paper, we explore the potential of multimodal LLMs (MLLM) for geospatial artificial intelligence (GeoAI), a field that leverages spatial data to address challenges in domains including Geospatial Semantics, Health Geography, Urban Geography, Urban Perception, and Remote Sensing. We propose a MLLM (OmniGeo) tailored to geospatial applications, capable of processing and analyzing heterogeneous data sources, including satellite imagery, geospatial metadata, and textual descriptions. By combining the strengths of natural language understanding and spatial reasoning, our model enhances the ability of instruction following and the accuracy of GeoAI systems. Results demonstrate that our model outperforms task-specific models and existing LLMs on diverse geospatial tasks, effectively addressing the multimodality nature while achieving competitive results on the zero-shot geospatial tasks. Our code will be released after publication.
Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models
Jul 18, 2024



In this paper, we investigate the use of diffusion models which are pre-trained on large-scale image-caption pairs for open-vocabulary 3D semantic understanding. We propose a novel method, namely Diff2Scene, which leverages frozen representations from text-image generative models, along with salient-aware and geometric-aware masks, for open-vocabulary 3D semantic segmentation and visual grounding tasks. Diff2Scene gets rid of any labeled 3D data and effectively identifies objects, appearances, materials, locations and their compositions in 3D scenes. We show that it outperforms competitive baselines and achieves significant improvements over state-of-the-art methods. In particular, Diff2Scene improves the state-of-the-art method on ScanNet200 by 12%.
Adversarially Masked Video Consistency for Unsupervised Domain Adaptation
Mar 24, 2024



We study the problem of unsupervised domain adaptation for egocentric videos. We propose a transformer-based model to learn class-discriminative and domain-invariant feature representations. It consists of two novel designs. The first module is called Generative Adversarial Domain Alignment Network with the aim of learning domain-invariant representations. It simultaneously learns a mask generator and a domain-invariant encoder in an adversarial way. The domain-invariant encoder is trained to minimize the distance between the source and target domain. The masking generator, conversely, aims at producing challenging masks by maximizing the domain distance. The second is a Masked Consistency Learning module to learn class-discriminative representations. It enforces the prediction consistency between the masked target videos and their full forms. To better evaluate the effectiveness of domain adaptation methods, we construct a more challenging benchmark for egocentric videos, U-Ego4D. Our method achieves state-of-the-art performance on the Epic-Kitchen and the proposed U-Ego4D benchmark.
STMT: A Spatial-Temporal Mesh Transformer for MoCap-Based Action Recognition
Mar 31, 2023



We study the problem of human action recognition using motion capture (MoCap) sequences. Unlike existing techniques that take multiple manual steps to derive standardized skeleton representations as model input, we propose a novel Spatial-Temporal Mesh Transformer (STMT) to directly model the mesh sequences. The model uses a hierarchical transformer with intra-frame off-set attention and inter-frame self-attention. The attention mechanism allows the model to freely attend between any two vertex patches to learn non-local relationships in the spatial-temporal domain. Masked vertex modeling and future frame prediction are used as two self-supervised tasks to fully activate the bi-directional and auto-regressive attention in our hierarchical transformer. The proposed method achieves state-of-the-art performance compared to skeleton-based and point-cloud-based models on common MoCap benchmarks. Code is available at https://github.com/zgzxy001/STMT.
Graph Intention Network for Click-through Rate Prediction in Sponsored Search
Mar 30, 2021
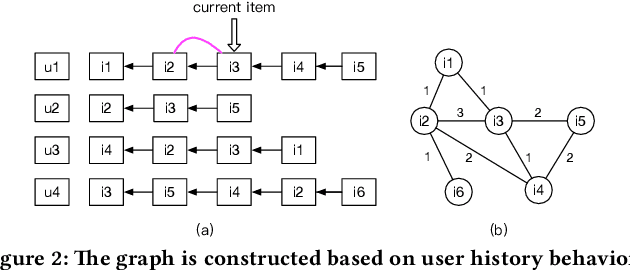


Estimating click-through rate (CTR) accurately has an essential impact on improving user experience and revenue in sponsored search. For CTR prediction model, it is necessary to make out user real-time search intention. Most of the current work is to mine their intentions based on user real-time behaviors. However, it is difficult to capture the intention when user behaviors are sparse, causing the behavior sparsity problem. Moreover, it is difficult for user to jump out of their specific historical behaviors for possible interest exploration, namely weak generalization problem. We propose a new approach Graph Intention Network (GIN) based on co-occurrence commodity graph to mine user intention. By adopting multi-layered graph diffusion, GIN enriches user behaviors to solve the behavior sparsity problem. By introducing co-occurrence relationship of commodities to explore the potential preferences, the weak generalization problem is also alleviated. To the best of our knowledge, the GIN method is the first to introduce graph learning for user intention mining in CTR prediction and propose end-to-end joint training of graph learning and CTR prediction tasks in sponsored search. At present, GIN has achieved excellent offline results on the real-world data of the e-commerce platform outperforming existing deep learning models, and has been running stable tests online and achieved significant CTR improvements.
MSNet: A Multilevel Instance Segmentation Network for Natural Disaster Damage Assessment in Aerial Videos
Jun 30, 2020


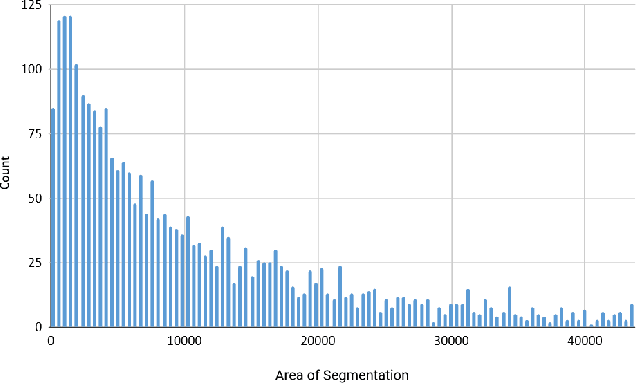
In this paper, we study the problem of efficiently assessing building damage after natural disasters like hurricanes, floods or fires, through aerial video analysis. We make two main contributions. The first contribution is a new dataset, consisting of user-generated aerial videos from social media with annotations of instance-level building damage masks. This provides the first benchmark for quantitative evaluation of models to assess building damage using aerial videos. The second contribution is a new model, namely MSNet, which contains novel region proposal network designs and an unsupervised score refinement network for confidence score calibration in both bounding box and mask branches. We show that our model achieves state-of-the-art results compared to previous methods in our dataset. We will release our data, models and code.
EENMF: An End-to-End Neural Matching Framework for E-Commerce Sponsored Search
Dec 09, 2018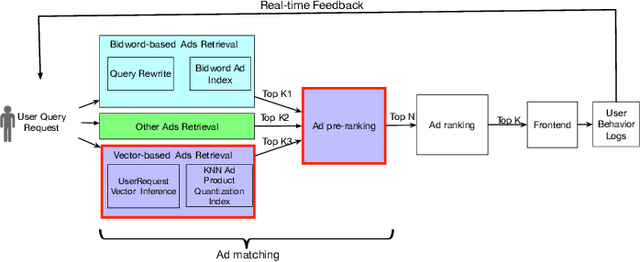
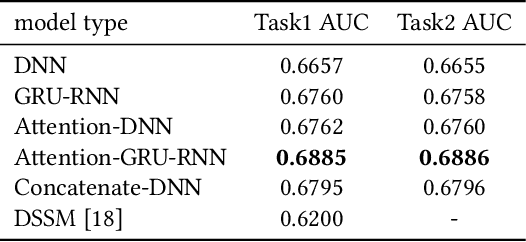
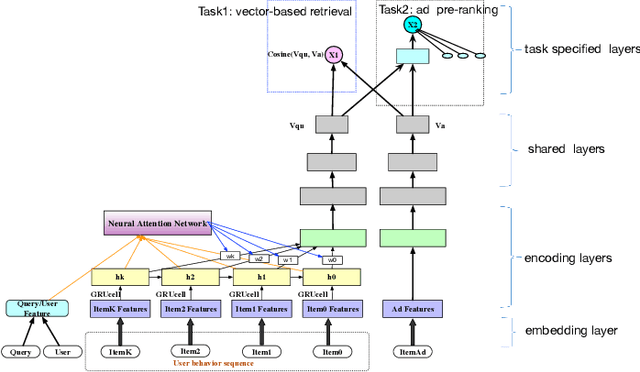
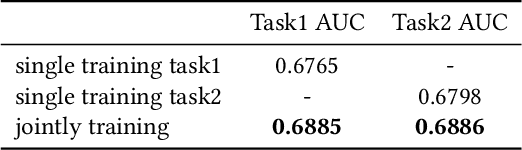
E-commerce sponsored search contributes an important part of revenue for the e-commerce company. In consideration of effectiveness and efficiency, a large-scale sponsored search system commonly adopts a multi-stage architecture. We name these stages as ad retrieval, ad pre-ranking and ad ranking. Ad retrieval and ad pre-ranking are collectively referred to as ad matching in this paper. We propose an end-to-end neural matching framework (EENMF) to model two tasks---vector-based ad retrieval and neural networks based ad pre-ranking. Under the deep matching framework, vector-based ad retrieval harnesses user recent behavior sequence to retrieve relevant ad candidates without the constraint of keyword bidding. Simultaneously, the deep model is employed to perform the global pre-ranking of ad candidates from multiple retrieval paths effectively and efficiently. Besides, the proposed model tries to optimize the pointwise cross-entropy loss which is consistent with the objective of predict models in the ranking stage. We conduct extensive evaluation to validate the performance of the proposed framework. In the real traffic of a large-scale e-commerce sponsored search, the proposed approach significantly outperforms the baseline.