 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Efficient Index and Code Index Modulations for Spread CPM Signals in Internet of Things
Aug 14, 2025
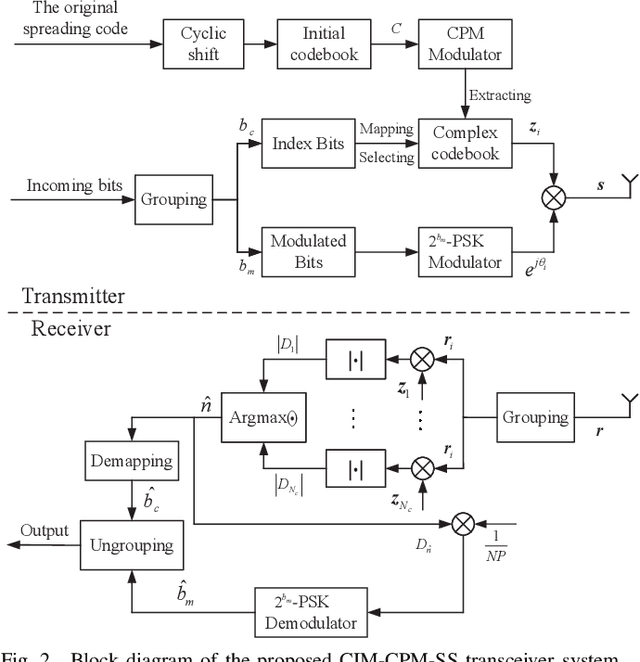


The evolution of Internet of Things technologies is driven by four key demands: ultra-low power consumption, high spectral efficiency, reduced implementation cost, and support for massive connectivity. To address these challenges, this paper proposes two novel modulation schemes that integrate continuous phase modulation (CPM) with spread spectrum (SS) techniques. We begin by establishing the quasi-orthogonality properties of CPM-SS sequences. The first scheme, termed IM-CPM-SS, employs index modulation (IM) to select spreading sequences from the CPM-SS set, thereby improving spectral efficiency while maintaining the constant-envelope property. The second scheme, referred to as CIM-CPM-SS, introduces code index modulation (CIM), which partitions the input bits such that one subset is mapped to phase-shift keying symbols and the other to CPM-SS sequence indices. Both schemes are applied to downlink non-orthogonal multiple access (NOMA) systems. We analyze their performance in terms of bit error rate (BER), spectral and energy efficiency, computational complexity, and peak-to-average power ratio characteristics under nonlinear amplifier conditions. Simulation results demonstrate that both schemes outperform conventional approaches in BER while preserving the benefits of constant-envelope, continuous-phase signaling. Furthermore, they achieve higher spectral and energy efficiency and exhibit strong resilience to nonlinear distortions in downlink NOMA scenarios.
OSS-UAgent: An Agent-based Usability Evaluation Framework for Open Source Software
May 29, 2025Usability evaluation is critical to the impact and adoption of open source software (OSS), yet traditional methods relying on human evaluators suffer from high costs and limited scalability. To address these limitations, we introduce OSS-UAgent, an automated, configurable, and interactive agent-based usability evaluation framework specifically designed for open source software. Our framework employs intelligent agents powered by large language models (LLMs) to simulate developers performing programming tasks across various experience levels (from Junior to Expert). By dynamically constructing platform-specific knowledge bases, OSS-UAgent ensures accurate and context-aware code generation. The generated code is automatically evaluated across multiple dimensions, including compliance, correctness, and readability, providing a comprehensive measure of the software's usability. Additionally, our demonstration showcases OSS-UAgent's practical application in evaluating graph analytics platforms, highlighting its effectiveness in automating usability evaluation.
OmniGeo: Towards a Multimodal Large Language Models for Geospatial Artificial Intelligence
Mar 20, 2025The rapid advancement of multimodal large language models (LLMs) has opened new frontiers in artificial intelligence, enabling the integration of diverse large-scale data types such as text, images, and spatial information. In this paper, we explore the potential of multimodal LLMs (MLLM) for geospatial artificial intelligence (GeoAI), a field that leverages spatial data to address challenges in domains including Geospatial Semantics, Health Geography, Urban Geography, Urban Perception, and Remote Sensing. We propose a MLLM (OmniGeo) tailored to geospatial applications, capable of processing and analyzing heterogeneous data sources, including satellite imagery, geospatial metadata, and textual descriptions. By combining the strengths of natural language understanding and spatial reasoning, our model enhances the ability of instruction following and the accuracy of GeoAI systems. Results demonstrate that our model outperforms task-specific models and existing LLMs on diverse geospatial tasks, effectively addressing the multimodality nature while achieving competitive results on the zero-shot geospatial tasks. Our code will be released after publication.
ProbDiffFlow: An Efficient Learning-Free Framework for Probabilistic Single-Image Optical Flow Estimation
Mar 16, 2025This paper studies optical flow estimation, a critical task in motion analysis with applications in autonomous navigation, action recognition, and film production. Traditional optical flow methods require consecutive frames, which are often unavailable due to limitations in data acquisition or real-world scene disruptions. Thus, single-frame optical flow estimation is emerging in the literature. However, existing single-frame approaches suffer from two major limitations: (1) they rely on labeled training data, making them task-specific, and (2) they produce deterministic predictions, failing to capture motion uncertainty. To overcome these challenges, we propose ProbDiffFlow, a training-free framework that estimates optical flow distributions from a single image. Instead of directly predicting motion, ProbDiffFlow follows an estimation-by-synthesis paradigm: it first generates diverse plausible future frames using a diffusion-based model, then estimates motion from these synthesized samples using a pre-trained optical flow model, and finally aggregates the results into a probabilistic flow distribution. This design eliminates the need for task-specific training while capturing multiple plausible motions. Experiments on both synthetic and real-world datasets demonstrate that ProbDiffFlow achieves superior accuracy, diversity, and efficiency, outperforming existing single-image and two-frame baselines.