 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQCFuse: Query-Aware Cache Fusion via Compressed View for Efficient RAG Serving
Jun 04, 2026Retrieval-augmented generation (RAG) improves large language model (LLM) answer quality by grounding generation in external evidence, but processing retrieved contexts makes the prefill stage a dominant serving cost. RAG cache fusion reduces this cost by reusing precomputed key-value (KV) caches for retrieved chunks and selectively recomputing tokens under the current prompt. Existing selectors, however, face a dilemma between quality and efficiency: fast query-agnostic or final-layer query-to-context selectors can miss request-relevant evidence, whereas full-view query-aware selectors require broad context and layer visibility before recomputation and therefore stall the layer-wise cache-fusion pipeline. We present QCFuse, a compressed-view query-aware selector for RAG cache fusion. QCFuse uses chunk-anchor query probing to condition user-query states on compact per-chunk anchors and critical-layer profiling to identify recomputation tokens without all-layer inspection. We implement QCFuse in SGLang and evaluate it on four open-weight LLMs across six datasets. QCFuse reaches full-prefill-level quality. At matched quality, QCFuse achieves an average prefill-time speedup of 1.7x over full prefill and 1.5x over ProphetKV, the strongest quality-preserving baseline.
Prototype-Guided Classification Sub-Task Decoupling Framework: Enhancing Generalization and Interpretability for Multivariate Time Series
May 21, 2026Time Series Classification (TSC) is a long-standing research problem that has gained increasing attention in recent years with the rapid growth of large-scale temporal data. Despite substantial progress enabled by deep learning, designing TSC models that are both accurate and interpretable remains a challenging task. Many existing approaches adopt a direct feature-to-label classification paradigm, by collapsing high-dimensional temporal embeddings into class logits via a single linear projection (often after global pooling), the paradigm conflates feature extraction and decision logic into an inseparable mapping. To address these limitations, we propose PDFTime, a prototype-guided framework that reformulates time series classification as a multi-stage decision process. Instead of direct feature-to-label mapping, PDFTime leverages learned prototypes to approximate class-conditional feature distributions in the latent space, enabling progressive discrimination through classification sub-tasks of varying granularity. To our knowledge, PDFTime is the first framework to reformulate time series classification as a decoupled, multi-stage similarity-based reasoning process, breaking the long-standing paradigm of direct, black-box feature-to-label mapping. Extensive evaluations demonstrate that PDFTime achieves state-of-the-art (SOTA) performance across UEA and UCR benchmarks. Notably, it secures the top-$1$ accuracy on 80 out of 128 datasets in the UCR archive, significantly outperforming recent strong baselines in both consistency and generalization.
Continual Learning in Large Language Models: Methods, Challenges, and Opportunities
Mar 13, 2026Continual learning (CL) has emerged as a pivotal paradigm to enable large language models (LLMs) to dynamically adapt to evolving knowledge and sequential tasks while mitigating catastrophic forgetting-a critical limitation of the static pre-training paradigm inherent to modern LLMs. This survey presents a comprehensive overview of CL methodologies tailored for LLMs, structured around three core training stages: continual pre-training, continual fine-tuning, and continual alignment.Beyond the canonical taxonomy of rehearsal-, regularization-, and architecture-based methods, we further subdivide each category by its distinct forgetting mitigation mechanisms and conduct a rigorous comparative analysis of the adaptability and critical improvements of traditional CL methods for LLMs. In doing so, we explicitly highlight core distinctions between LLM CL and traditional machine learning, particularly with respect to scale, parameter efficiency, and emergent capabilities. Our analysis covers essential evaluation metrics, including forgetting rates and knowledge transfer efficiency, along with emerging benchmarks for assessing CL performance. This survey reveals that while current methods demonstrate promising results in specific domains, fundamental challenges persist in achieving seamless knowledge integration across diverse tasks and temporal scales. This systematic review contributes to the growing body of knowledge on LLM adaptation, providing researchers and practitioners with a structured framework for understanding current achievements and future opportunities in lifelong learning for language models.
C$^{2}$TC: A Training-Free Framework for Efficient Tabular Data Condensation
Feb 25, 2026Tabular data is the primary data format in industrial relational databases, underpinning modern data analytics and decision-making. However, the increasing scale of tabular data poses significant computational and storage challenges to learning-based analytical systems. This highlights the need for data-efficient learning, which enables effective model training and generalization using substantially fewer samples. Dataset condensation (DC) has emerged as a promising data-centric paradigm that synthesizes small yet informative datasets to preserve data utility while reducing storage and training costs. However, existing DC methods are computationally intensive due to reliance on complex gradient-based optimization. Moreover, they often overlook key characteristics of tabular data, such as heterogeneous features and class imbalance. To address these limitations, we introduce C$^{2}$TC (Class-Adaptive Clustering for Tabular Condensation), the first training-free tabular dataset condensation framework that jointly optimizes class allocation and feature representation, enabling efficient and scalable condensation. Specifically, we reformulate the dataset condensation objective into a novel class-adaptive cluster allocation problem (CCAP), which eliminates costly training and integrates adaptive label allocation to handle class imbalance. To solve the NP-hard CCAP, we develop HFILS, a heuristic local search that alternates between soft allocation and class-wise clustering to efficiently obtain high-quality solutions. Moreover, a hybrid categorical feature encoding (HCFE) is proposed for semantics-preserving clustering of heterogeneous discrete attributes. Extensive experiments on 10 real-world datasets demonstrate that C$^{2}$TC improves efficiency by at least 2 orders of magnitude over state-of-the-art baselines, while achieving superior downstream performance.
HyperJoin: LLM-augmented Hypergraph Link Prediction for Joinable Table Discovery
Jan 03, 2026As a pivotal task in data lake management, joinable table discovery has attracted widespread interest. While existing language model-based methods achieve remarkable performance by combining offline column representation learning with online ranking, their design insufficiently accounts for the underlying structural interactions: (1) offline, they directly model tables into isolated or pairwise columns, thereby struggling to capture the rich inter-table and intra-table structural information; and (2) online, they rank candidate columns based solely on query-candidate similarity, ignoring the mutual interactions among the candidates, leading to incoherent result sets. To address these limitations, we propose HyperJoin, a large language model (LLM)-augmented Hypergraph framework for Joinable table discovery. Specifically, we first construct a hypergraph to model tables using both the intra-table hyperedges and the LLM-augmented inter-table hyperedges. Consequently, the task of joinable table discovery is formulated as link prediction on this constructed hypergraph. We then design HIN, a Hierarchical Interaction Network that learns expressive column representations through bidirectional message passing over columns and hyperedges. To strengthen coherence and internal consistency in the result columns, we cast online ranking as a coherence-aware top-k column selection problem. We then introduce a reranking module that leverages a maximum spanning tree algorithm to prune noisy connections and maximize coherence. Experiments demonstrate the superiority of HyperJoin, achieving average improvements of 21.4% (Precision@15) and 17.2% (Recall@15) over the best baseline.
FADTI: Fourier and Attention Driven Diffusion for Multivariate Time Series Imputation
Dec 17, 2025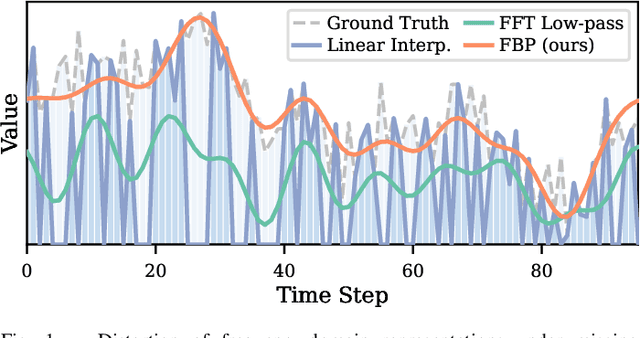
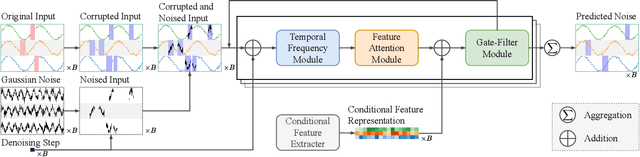

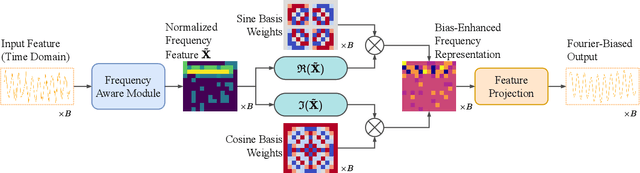
Multivariate time series imputation is fundamental in applications such as healthcare, traffic forecasting, and biological modeling, where sensor failures and irregular sampling lead to pervasive missing values. However, existing Transformer- and diffusion-based models lack explicit inductive biases and frequency awareness, limiting their generalization under structured missing patterns and distribution shifts. We propose FADTI, a diffusion-based framework that injects frequency-informed feature modulation via a learnable Fourier Bias Projection (FBP) module and combines it with temporal modeling through self-attention and gated convolution. FBP supports multiple spectral bases, enabling adaptive encoding of both stationary and non-stationary patterns. This design injects frequency-domain inductive bias into the generative imputation process. Experiments on multiple benchmarks, including a newly introduced biological time series dataset, show that FADTI consistently outperforms state-of-the-art methods, particularly under high missing rates. Code is available at https://anonymous.4open.science/r/TimeSeriesImputation-52BF
DHG-Bench: A Comprehensive Benchmark on Deep Hypergraph Learning
Aug 17, 2025Although conventional deep graph models have achieved great success in relational learning, their focus on pairwise relationships limits their capacity to learn pervasive higher-order interactions in real-world complex systems, which can be naturally modeled as hypergraphs. To tackle this, hypergraph neural networks (HNNs), the dominant approach in deep hypergraph learning (DHGL), has garnered substantial attention in recent years. Despite the proposal of numerous HNN methods, there is no comprehensive benchmark for HNNs, which creates a great obstacle to understanding the progress of DHGL in several aspects: (i) insufficient coverage of datasets, algorithms, and tasks; (ii) a narrow evaluation of algorithm performance; and (iii) inconsistent dataset usage, preprocessing, and experimental setups that hinder comparability. To fill the gap, we introduce DHG-Bench, the first comprehensive benchmark for DHGL. Specifically, DHG-Bench integrates 20 diverse datasets spanning node-, edge-, and graph-level tasks, along with 16 state-of-the-art HNN algorithms, under consistent data processing and experimental protocols. Our benchmark systematically investigates the characteristics of HNNs in terms of four dimensions: effectiveness, efficiency, robustness, and fairness. Further, to facilitate reproducible research, we have developed an easy-to-use library for training and evaluating different HNN methods. Extensive experiments conducted with DHG-Bench reveal both the strengths and inherent limitations of existing algorithms, offering valuable insights and directions for future research. The code is publicly available at: https://github.com/Coco-Hut/DHG-Bench.
OSS-UAgent: An Agent-based Usability Evaluation Framework for Open Source Software
May 29, 2025Usability evaluation is critical to the impact and adoption of open source software (OSS), yet traditional methods relying on human evaluators suffer from high costs and limited scalability. To address these limitations, we introduce OSS-UAgent, an automated, configurable, and interactive agent-based usability evaluation framework specifically designed for open source software. Our framework employs intelligent agents powered by large language models (LLMs) to simulate developers performing programming tasks across various experience levels (from Junior to Expert). By dynamically constructing platform-specific knowledge bases, OSS-UAgent ensures accurate and context-aware code generation. The generated code is automatically evaluated across multiple dimensions, including compliance, correctness, and readability, providing a comprehensive measure of the software's usability. Additionally, our demonstration showcases OSS-UAgent's practical application in evaluating graph analytics platforms, highlighting its effectiveness in automating usability evaluation.
ProbDiffFlow: An Efficient Learning-Free Framework for Probabilistic Single-Image Optical Flow Estimation
Mar 16, 2025This paper studies optical flow estimation, a critical task in motion analysis with applications in autonomous navigation, action recognition, and film production. Traditional optical flow methods require consecutive frames, which are often unavailable due to limitations in data acquisition or real-world scene disruptions. Thus, single-frame optical flow estimation is emerging in the literature. However, existing single-frame approaches suffer from two major limitations: (1) they rely on labeled training data, making them task-specific, and (2) they produce deterministic predictions, failing to capture motion uncertainty. To overcome these challenges, we propose ProbDiffFlow, a training-free framework that estimates optical flow distributions from a single image. Instead of directly predicting motion, ProbDiffFlow follows an estimation-by-synthesis paradigm: it first generates diverse plausible future frames using a diffusion-based model, then estimates motion from these synthesized samples using a pre-trained optical flow model, and finally aggregates the results into a probabilistic flow distribution. This design eliminates the need for task-specific training while capturing multiple plausible motions. Experiments on both synthetic and real-world datasets demonstrate that ProbDiffFlow achieves superior accuracy, diversity, and efficiency, outperforming existing single-image and two-frame baselines.
Unlocking Multi-Modal Potentials for Dynamic Text-Attributed Graph Representation
Feb 27, 2025



Dynamic Text-Attributed Graphs (DyTAGs) are a novel graph paradigm that captures evolving temporal edges alongside rich textual attributes. A prior approach to representing DyTAGs leverages pre-trained language models to encode text attributes and subsequently integrates them into dynamic graph models. However, it follows edge-centric modeling, as in dynamic graph learning, which is limited in local structures and fails to exploit the unique characteristics of DyTAGs, leading to suboptimal performance. We observe that DyTAGs inherently comprise three distinct modalities-temporal, textual, and structural-often exhibiting dispersed or even orthogonal distributions, with the first two largely overlooked in existing research. Building on this insight, we propose MoMent, a model-agnostic multi-modal framework that can seamlessly integrate with dynamic graph models for structural modality learning. The core idea is to shift from edge-centric to node-centric modeling, fully leveraging three modalities for node representation. Specifically, MoMent presents non-shared node-centric encoders based on the attention mechanism to capture global temporal and semantic contexts from temporal and textual modalities, together with local structure learning, thus generating modality-specific tokens. To prevent disjoint latent space, we propose a symmetric alignment loss, an auxiliary objective that aligns temporal and textual tokens, ensuring global temporal-semantic consistency with a theoretical guarantee. Last, we design a lightweight adaptor to fuse these tokens, generating comprehensive and cohesive node representations. We theoretically demonstrate that MoMent enhances discriminative power over exclusive edge-centric modeling. Extensive experiments across seven datasets and two downstream tasks show that MoMent achieves up to 33.62% improvement against the baseline using four dynamic graph models.