 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Multi-Modal Potentials for Dynamic Text-Attributed Graph Representation
Feb 27, 2025



Dynamic Text-Attributed Graphs (DyTAGs) are a novel graph paradigm that captures evolving temporal edges alongside rich textual attributes. A prior approach to representing DyTAGs leverages pre-trained language models to encode text attributes and subsequently integrates them into dynamic graph models. However, it follows edge-centric modeling, as in dynamic graph learning, which is limited in local structures and fails to exploit the unique characteristics of DyTAGs, leading to suboptimal performance. We observe that DyTAGs inherently comprise three distinct modalities-temporal, textual, and structural-often exhibiting dispersed or even orthogonal distributions, with the first two largely overlooked in existing research. Building on this insight, we propose MoMent, a model-agnostic multi-modal framework that can seamlessly integrate with dynamic graph models for structural modality learning. The core idea is to shift from edge-centric to node-centric modeling, fully leveraging three modalities for node representation. Specifically, MoMent presents non-shared node-centric encoders based on the attention mechanism to capture global temporal and semantic contexts from temporal and textual modalities, together with local structure learning, thus generating modality-specific tokens. To prevent disjoint latent space, we propose a symmetric alignment loss, an auxiliary objective that aligns temporal and textual tokens, ensuring global temporal-semantic consistency with a theoretical guarantee. Last, we design a lightweight adaptor to fuse these tokens, generating comprehensive and cohesive node representations. We theoretically demonstrate that MoMent enhances discriminative power over exclusive edge-centric modeling. Extensive experiments across seven datasets and two downstream tasks show that MoMent achieves up to 33.62% improvement against the baseline using four dynamic graph models.
UniDyG: A Unified and Effective Representation Learning Approach for Large Dynamic Graphs
Feb 23, 2025Dynamic graphs are formulated in continuous-time or discrete-time dynamic graphs. They differ in temporal granularity: Continuous-Time Dynamic Graphs (CTDGs) exhibit rapid, localized changes, while Discrete-Time Dynamic Graphs (DTDGs) show gradual, global updates. This difference leads to isolated developments in representation learning for each type. To advance representation learning, recent research attempts to design a unified model capable of handling both CTDGs and DTDGs. However, it typically focuses on local dynamic propagation for temporal structure learning in the time domain, failing to accurately capture the structural evolution associated with each temporal granularity. In addition, existing works-whether specific or unified-often overlook the issue of temporal noise, compromising the model robustness and effectiveness. To better model both types of dynamic graphs, we propose UniDyG, a unified and effective representation learning approach, which scales to large dynamic graphs. We first propose a novel Fourier Graph Attention (FGAT) mechanism that can model local and global structural correlations based on recent neighbors and complex-number selective aggregation, while theoretically ensuring consistent representations of dynamic graphs over time. Based on approximation theory, we demonstrate that FGAT is well-suited to capture the underlying structures in CTDGs and DTDGs. We further enhance FGAT to resist temporal noise by designing an energy-gated unit, which adaptively filters out high-frequency noise according to the energy. Last, we leverage our FGAT mechanisms for temporal structure learning and employ the frequency-enhanced linear function for node-level dynamic updates, facilitating the generation of high-quality temporal embeddings. Extensive experiments show that our UniDyG achieves an average improvement of 14.4% over sixteen baselines across nine dynamic graphs.
BASIC: Semi-supervised Multi-organ Segmentation with Balanced Subclass Regularization and Semantic-conflict Penalty
Jan 07, 2025



Semi-supervised learning (SSL) has shown notable potential in relieving the heavy demand of dense prediction tasks on large-scale well-annotated datasets, especially for the challenging multi-organ segmentation (MoS). However, the prevailing class-imbalance problem in MoS caused by the substantial variations in organ size exacerbates the learning difficulty of the SSL network. To address this issue, in this paper, we propose an innovative semi-supervised network with BAlanced Subclass regularIzation and semantic-Conflict penalty mechanism (BASIC) to effectively learn the unbiased knowledge for semi-supervised MoS. Concretely, we construct a novel auxiliary subclass segmentation (SCS) task based on priorly generated balanced subclasses, thus deeply excavating the unbiased information for the main MoS task with the fashion of multi-task learning. Additionally, based on a mean teacher framework, we elaborately design a balanced subclass regularization to utilize the teacher predictions of SCS task to supervise the student predictions of MoS task, thus effectively transferring unbiased knowledge to the MoS subnetwork and alleviating the influence of the class-imbalance problem. Considering the similar semantic information inside the subclasses and their corresponding original classes (i.e., parent classes), we devise a semantic-conflict penalty mechanism to give heavier punishments to the conflicting SCS predictions with wrong parent classes and provide a more accurate constraint to the MoS predictions. Extensive experiments conducted on two publicly available datasets, i.e., the WORD dataset and the MICCAI FLARE 2022 dataset, have verified the superior performance of our proposed BASIC compared to other state-of-the-art methods.
Post-hoc Interpretability Illumination for Scientific Interaction Discovery
Dec 20, 2024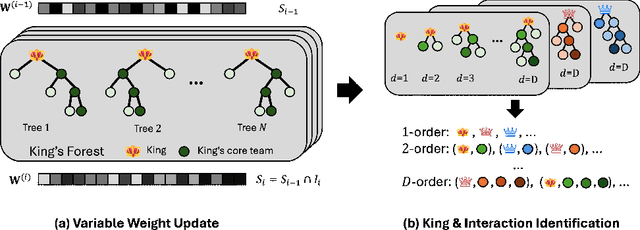

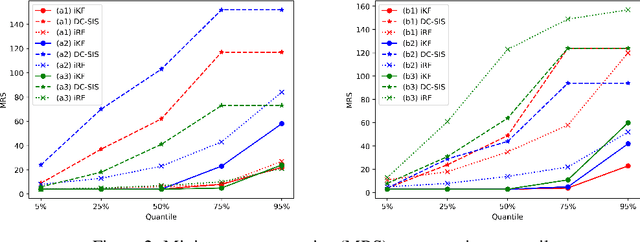
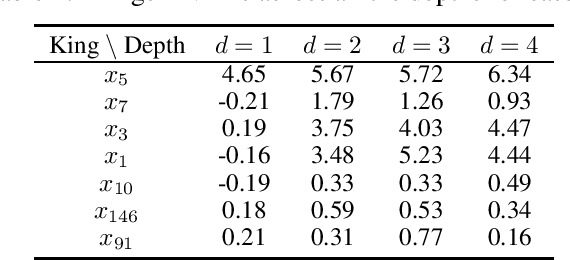
Model interpretability and explainability have garnered substantial attention in recent years, particularly in decision-making applications. However, existing interpretability tools often fall short in delivering satisfactory performance due to limited capabilities or efficiency issues. To address these challenges, we propose a novel post-hoc method: Iterative Kings' Forests (iKF), designed to uncover complex multi-order interactions among variables. iKF iteratively selects the next most important variable, the "King", and constructs King's Forests by placing it at the root node of each tree to identify variables that interact with the "King". It then generates ranked short lists of important variables and interactions of varying orders. Additionally, iKF provides inference metrics to analyze the patterns of the selected interactions and classify them into one of three interaction types: Accompanied Interaction, Synergistic Interaction, and Hierarchical Interaction. Extensive experiments demonstrate the strong interpretive power of our proposed iKF, highlighting its great potential for explainable modeling and scientific discovery across diverse scientific fields.
S3PET: Semi-supervised Standard-dose PET Image Reconstruction via Dose-aware Token Swap
Jul 30, 2024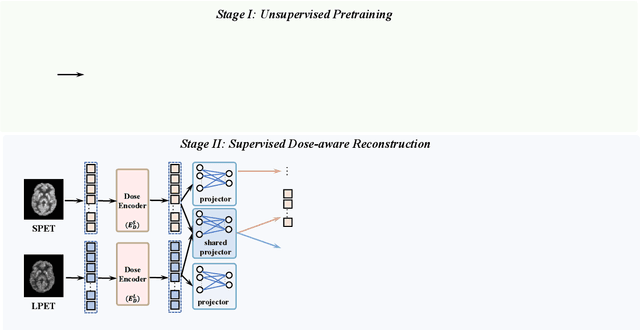
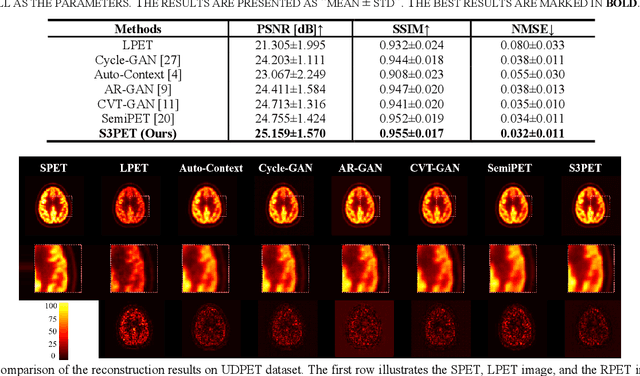
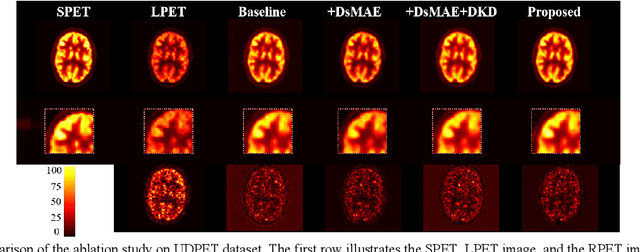

To acquire high-quality positron emission tomography (PET) images while reducing the radiation tracer dose, numerous efforts have been devoted to reconstructing standard-dose PET (SPET) images from low-dose PET (LPET). However, the success of current fully-supervised approaches relies on abundant paired LPET and SPET images, which are often unavailable in clinic. Moreover, these methods often mix the dose-invariant content with dose level-related dose-specific details during reconstruction, resulting in distorted images. To alleviate these problems, in this paper, we propose a two-stage Semi-Supervised SPET reconstruction framework, namely S3PET, to accommodate the training of abundant unpaired and limited paired SPET and LPET images. Our S3PET involves an un-supervised pre-training stage (Stage I) to extract representations from unpaired images, and a supervised dose-aware reconstruction stage (Stage II) to achieve LPET-to-SPET reconstruction by transferring the dose-specific knowledge between paired images. Specifically, in stage I, two independent dose-specific masked autoencoders (DsMAEs) are adopted to comprehensively understand the unpaired SPET and LPET images. Then, in Stage II, the pre-trained DsMAEs are further finetuned using paired images. To prevent distortions in both content and details, we introduce two elaborate modules, i.e., a dose knowledge decouple module to disentangle the respective dose-specific and dose-invariant knowledge of LPET and SPET, and a dose-specific knowledge learning module to transfer the dose-specific information from SPET to LPET, thereby achieving high-quality SPET reconstruction from LPET images. Experiments on two datasets demonstrate that our S3PET achieves state-of-the-art performance quantitatively and qualitatively.
Learning with Alignments: Tackling the Inter- and Intra-domain Shifts for Cross-multidomain Facial Expression Recognition
Jul 08, 2024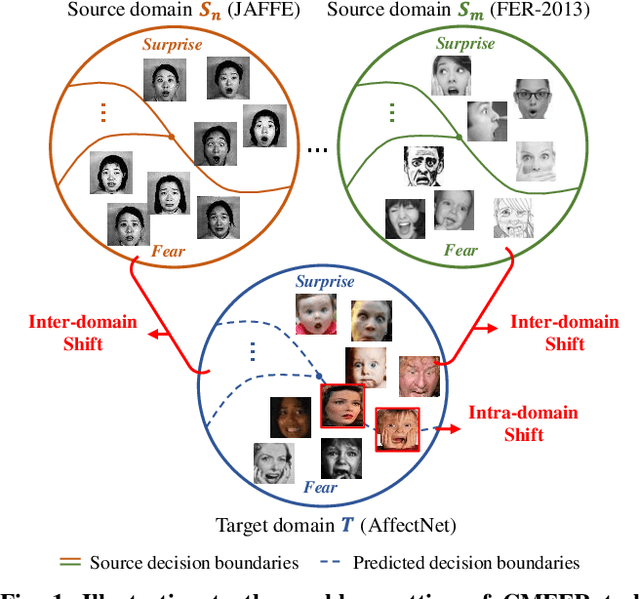

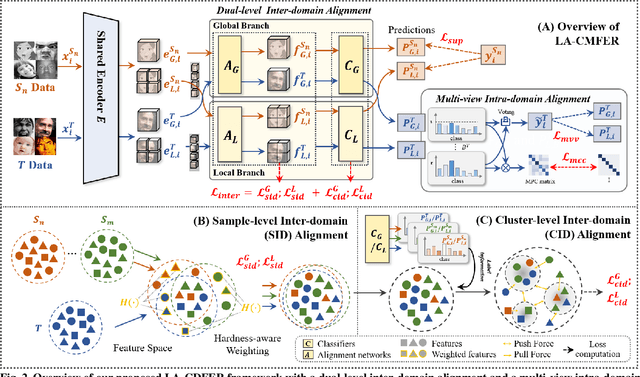
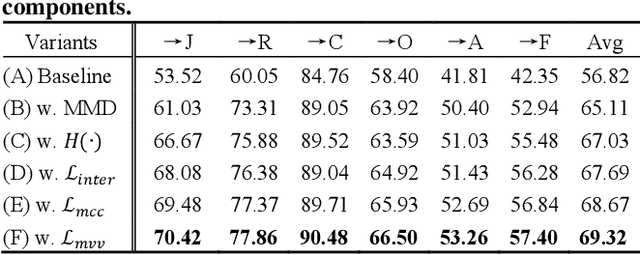
Facial Expression Recognition (FER) holds significant importance in human-computer interactions. Existing cross-domain FER methods often transfer knowledge solely from a single labeled source domain to an unlabeled target domain, neglecting the comprehensive information across multiple sources. Nevertheless, cross-multidomain FER (CMFER) is very challenging for (i) the inherent inter-domain shifts across multiple domains and (ii) the intra-domain shifts stemming from the ambiguous expressions and low inter-class distinctions. In this paper, we propose a novel Learning with Alignments CMFER framework, named LA-CMFER, to handle both inter- and intra-domain shifts. Specifically, LA-CMFER is constructed with a global branch and a local branch to extract features from the full images and local subtle expressions, respectively. Based on this, LA-CMFER presents a dual-level inter-domain alignment method to force the model to prioritize hard-to-align samples in knowledge transfer at a sample level while gradually generating a well-clustered feature space with the guidance of class attributes at a cluster level, thus narrowing the inter-domain shifts. To address the intra-domain shifts, LA-CMFER introduces a multi-view intra-domain alignment method with a multi-view clustering consistency constraint where a prediction similarity matrix is built to pursue consistency between the global and local views, thus refining pseudo labels and eliminating latent noise. Extensive experiments on six benchmark datasets have validated the superiority of our LA-CMFER.
Adaptive Prompt Learning with Negative Textual Semantics and Uncertainty Modeling for Universal Multi-Source Domain Adaptation
Apr 24, 2024Universal Multi-source Domain Adaptation (UniMDA) transfers knowledge from multiple labeled source domains to an unlabeled target domain under domain shifts (different data distribution) and class shifts (unknown target classes). Existing solutions focus on excavating image features to detect unknown samples, ignoring abundant information contained in textual semantics. In this paper, we propose an Adaptive Prompt learning with Negative textual semantics and uncErtainty modeling method based on Contrastive Language-Image Pre-training (APNE-CLIP) for UniMDA classification tasks. Concretely, we utilize the CLIP with adaptive prompts to leverage textual information of class semantics and domain representations, helping the model identify unknown samples and address domain shifts. Additionally, we design a novel global instance-level alignment objective by utilizing negative textual semantics to achieve more precise image-text pair alignment. Furthermore, we propose an energy-based uncertainty modeling strategy to enlarge the margin distance between known and unknown samples. Extensive experiments demonstrate the superiority of our proposed method.
Two-Phase Multi-Dose-Level PET Image Reconstruction with Dose Level Awareness
Apr 10, 2024To obtain high-quality positron emission tomography (PET) while minimizing radiation exposure, a range of methods have been designed to reconstruct standard-dose PET (SPET) from corresponding low-dose PET (LPET) images. However, most current methods merely learn the mapping between single-dose-level LPET and SPET images, but omit the dose disparity of LPET images in clinical scenarios. In this paper, to reconstruct high-quality SPET images from multi-dose-level LPET images, we design a novel two-phase multi-dose-level PET reconstruction algorithm with dose level awareness, containing a pre-training phase and a SPET prediction phase. Specifically, the pre-training phase is devised to explore both fine-grained discriminative features and effective semantic representation. The SPET prediction phase adopts a coarse prediction network utilizing pre-learned dose level prior to generate preliminary result, and a refinement network to precisely preserve the details. Experiments on MICCAI 2022 Ultra-low Dose PET Imaging Challenge Dataset have demonstrated the superiority of our method.
Dose Prediction Driven Radiotherapy Paramters Regression via Intra- and Inter-Relation Modeling
Feb 29, 2024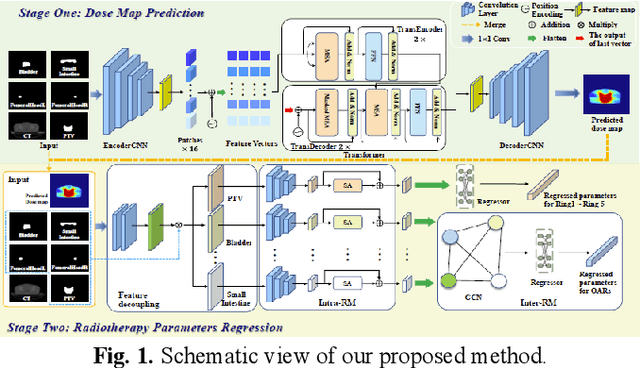
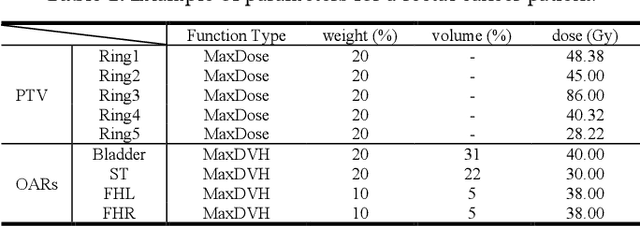
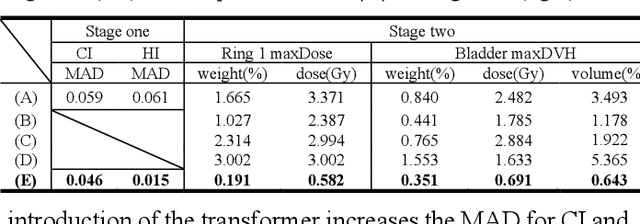

Deep learning has facilitated the automation of radiotherapy by predicting accurate dose distribution maps. However, existing methods fail to derive the desirable radiotherapy parameters that can be directly input into the treatment planning system (TPS), impeding the full automation of radiotherapy. To enable more thorough automatic radiotherapy, in this paper, we propose a novel two-stage framework to directly regress the radiotherapy parameters, including a dose map prediction stage and a radiotherapy parameters regression stage. In stage one, we combine transformer and convolutional neural network (CNN) to predict realistic dose maps with rich global and local information, providing accurate dosimetric knowledge for the subsequent parameters regression. In stage two, two elaborate modules, i.e., an intra-relation modeling (Intra-RM) module and an inter-relation modeling (Inter-RM) module, are designed to exploit the organ-specific and organ-shared features for precise parameters regression. Experimental results on a rectal cancer dataset demonstrate the effectiveness of our method.
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Feb 21, 2024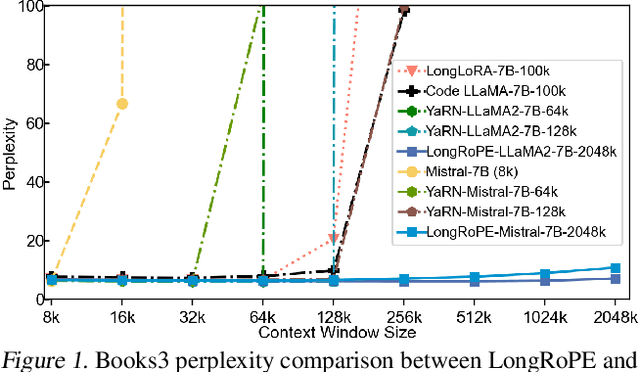
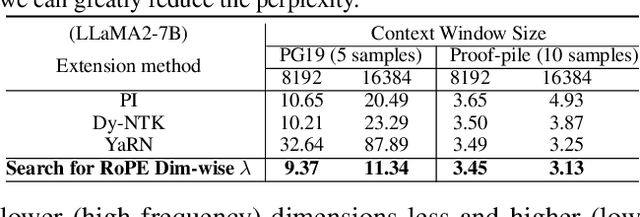
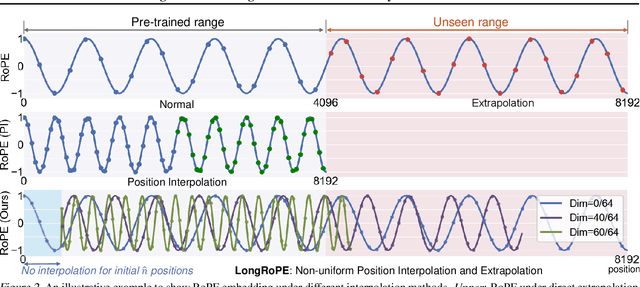

Large context window is a desirable feature in large language models (LLMs). However, due to high fine-tuning costs, scarcity of long texts, and catastrophic values introduced by new token positions, current extended context windows are limited to around 128k tokens. This paper introduces LongRoPE that, for the first time, extends the context window of pre-trained LLMs to an impressive 2048k tokens, with up to only 1k fine-tuning steps at within 256k training lengths, while maintaining performance at the original short context window. This is achieved by three key innovations: (i) we identify and exploit two forms of non-uniformities in positional interpolation through an efficient search, providing a better initialization for fine-tuning and enabling an 8x extension in non-fine-tuning scenarios; (ii) we introduce a progressive extension strategy that first fine-tunes a 256k length LLM and then conducts a second positional interpolation on the fine-tuned extended LLM to achieve a 2048k context window; (iii) we readjust LongRoPE on 8k length to recover the short context window performance. Extensive experiments on LLaMA2 and Mistral across various tasks demonstrate the effectiveness of our method. Models extended via LongRoPE retain the original architecture with minor modifications to the positional embedding, and can reuse most pre-existing optimizations.