 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgerStar2-Agent: Agentic Reasoning Technical Report
Aug 28, 2025We introduce rStar2-Agent, a 14B math reasoning model trained with agentic reinforcement learning to achieve frontier-level performance. Beyond current long CoT, the model demonstrates advanced cognitive behaviors, such as thinking carefully before using Python coding tools and reflecting on code execution feedback to autonomously explore, verify, and refine intermediate steps in complex problem-solving. This capability is enabled through three key innovations that makes agentic RL effective at scale: (i) an efficient RL infrastructure with a reliable Python code environment that supports high-throughput execution and mitigates the high rollout costs, enabling training on limited GPU resources (64 MI300X GPUs); (ii) GRPO-RoC, an agentic RL algorithm with a Resample-on-Correct rollout strategy that addresses the inherent environment noises from coding tools, allowing the model to reason more effectively in a code environment; (iii) An efficient agent training recipe that starts with non-reasoning SFT and progresses through multi-RL stages, yielding advanced cognitive abilities with minimal compute cost. To this end, rStar2-Agent boosts a pre-trained 14B model to state of the art in only 510 RL steps within one week, achieving average pass@1 scores of 80.6% on AIME24 and 69.8% on AIME25, surpassing DeepSeek-R1 (671B) with significantly shorter responses. Beyond mathematics, rStar2-Agent-14B also demonstrates strong generalization to alignment, scientific reasoning, and agentic tool-use tasks. Code and training recipes are available at https://github.com/microsoft/rStar.
rStar-Coder: Scaling Competitive Code Reasoning with a Large-Scale Verified Dataset
May 27, 2025Advancing code reasoning in large language models (LLMs) is fundamentally limited by the scarcity of high-difficulty datasets, especially those with verifiable input-output test cases necessary for rigorous solution validation at scale. We introduce rStar-Coder, which significantly improves LLM code reasoning capabilities by constructing a large-scale, verified dataset of 418K competition-level code problems, 580K long-reasoning solutions along with rich test cases of varying difficulty. This is achieved through three core contributions: (1) we curate competitive programming code problems and oracle solutions to synthesize new, solvable problems; (2) we introduce a reliable input-output test case synthesis pipeline that decouples the generation into a three-step input generation method and a mutual verification mechanism for effective output labeling; (3) we augment problems with high-quality, test-case-verified long-reasoning solutions. Extensive experiments on Qwen models (1.5B-14B) across various code reasoning benchmarks demonstrate the superiority of rStar-Coder dataset, achieving leading performance comparable to frontier reasoning LLMs with much smaller model sizes. On LiveCodeBench, rStar-Coder improves Qwen2.5-7B from 17.4% to an impressive 57.3%, and Qwen2.5-14B from 23.3% to 62.5%, surpassing o3-mini (low) by3.1%. On the more challenging USA Computing Olympiad, our 7B model achieves an average pass@1 accuracy of 16.15%, outperforming the frontier-level QWQ-32B. Code and the dataset will be released at https://github.com/microsoft/rStar.
Phi-4-Mini Technical Report: Compact yet Powerful Multimodal Language Models via Mixture-of-LoRAs
Mar 03, 2025



We introduce Phi-4-Mini and Phi-4-Multimodal, compact yet highly capable language and multimodal models. Phi-4-Mini is a 3.8-billion-parameter language model trained on high-quality web and synthetic data, significantly outperforming recent open-source models of similar size and matching the performance of models twice its size on math and coding tasks requiring complex reasoning. This achievement is driven by a carefully curated synthetic data recipe emphasizing high-quality math and coding datasets. Compared to its predecessor, Phi-3.5-Mini, Phi-4-Mini features an expanded vocabulary size of 200K tokens to better support multilingual applications, as well as group query attention for more efficient long-sequence generation. Phi-4-Multimodal is a multimodal model that integrates text, vision, and speech/audio input modalities into a single model. Its novel modality extension approach leverages LoRA adapters and modality-specific routers to allow multiple inference modes combining various modalities without interference. For example, it now ranks first in the OpenASR leaderboard to date, although the LoRA component of the speech/audio modality has just 460 million parameters. Phi-4-Multimodal supports scenarios involving (vision + language), (vision + speech), and (speech/audio) inputs, outperforming larger vision-language and speech-language models on a wide range of tasks. Additionally, we experiment to further train Phi-4-Mini to enhance its reasoning capabilities. Despite its compact 3.8-billion-parameter size, this experimental version achieves reasoning performance on par with or surpassing significantly larger models, including DeepSeek-R1-Distill-Qwen-7B and DeepSeek-R1-Distill-Llama-8B.
LongRoPE2: Near-Lossless LLM Context Window Scaling
Feb 27, 2025



LongRoPE2 is a novel approach that extends the effective context window of pre-trained large language models (LLMs) to the target length, while preserving the performance on the original shorter context window. This is achieved by three contributions: (1) a hypothesis that insufficient training in higher RoPE dimensions contributes to the persistent out-of-distribution (OOD) issues observed in existing methods; (2) an effective RoPE rescaling algorithm that adopts evolutionary search guided by "needle-driven" perplexity to address the insufficient training problem; (3) a mixed context window training approach that fine-tunes model weights to adopt rescaled RoPE for long-context sequences while preserving the short-context performance with the original RoPE. Extensive experiments on LLaMA3-8B and Phi3-mini-3.8B across various benchmarks validate the hypothesis and demonstrate the effectiveness of LongRoPE2. Remarkably, LongRoPE2 extends LLaMA3-8B to achieve a 128K effective context length while retaining over 98.5% of short-context performance, using only 10B tokens -- 80x fewer than Meta's approach, which fails to reach the target effective context length. Code will be available at https://github.com/microsoft/LongRoPE.
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
Jan 08, 2025



We present rStar-Math to demonstrate that small language models (SLMs) can rival or even surpass the math reasoning capability of OpenAI o1, without distillation from superior models. rStar-Math achieves this by exercising "deep thinking" through Monte Carlo Tree Search (MCTS), where a math policy SLM performs test-time search guided by an SLM-based process reward model. rStar-Math introduces three innovations to tackle the challenges in training the two SLMs: (1) a novel code-augmented CoT data sythesis method, which performs extensive MCTS rollouts to generate step-by-step verified reasoning trajectories used to train the policy SLM; (2) a novel process reward model training method that avoids na\"ive step-level score annotation, yielding a more effective process preference model (PPM); (3) a self-evolution recipe in which the policy SLM and PPM are built from scratch and iteratively evolved to improve reasoning capabilities. Through 4 rounds of self-evolution with millions of synthesized solutions for 747k math problems, rStar-Math boosts SLMs' math reasoning to state-of-the-art levels. On the MATH benchmark, it improves Qwen2.5-Math-7B from 58.8% to 90.0% and Phi3-mini-3.8B from 41.4% to 86.4%, surpassing o1-preview by +4.5% and +0.9%. On the USA Math Olympiad (AIME), rStar-Math solves an average of 53.3% (8/15) of problems, ranking among the top 20% the brightest high school math students. Code and data will be available at https://github.com/microsoft/rStar.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Apr 23, 2024



We introduce phi-3-mini, a 3.8 billion parameter language model trained on 3.3 trillion tokens, whose overall performance, as measured by both academic benchmarks and internal testing, rivals that of models such as Mixtral 8x7B and GPT-3.5 (e.g., phi-3-mini achieves 69% on MMLU and 8.38 on MT-bench), despite being small enough to be deployed on a phone. The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format. We also provide some initial parameter-scaling results with a 7B and 14B models trained for 4.8T tokens, called phi-3-small and phi-3-medium, both significantly more capable than phi-3-mini (e.g., respectively 75% and 78% on MMLU, and 8.7 and 8.9 on MT-bench).
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Feb 21, 2024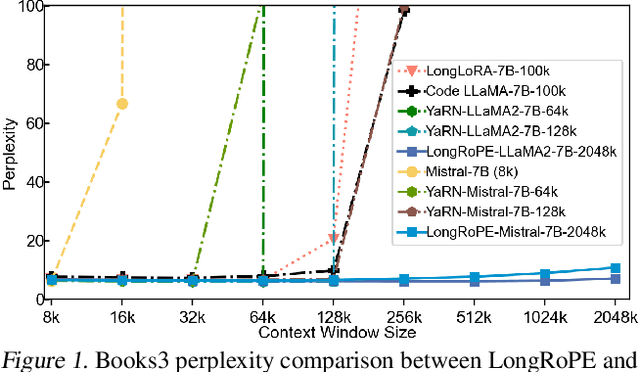
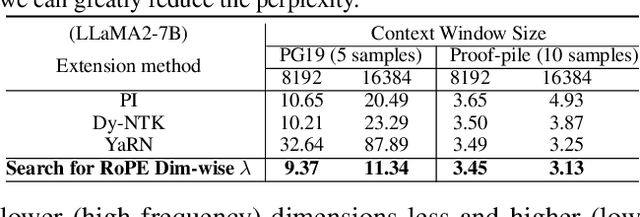
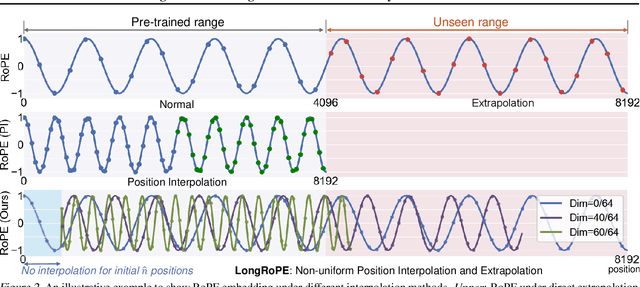

Large context window is a desirable feature in large language models (LLMs). However, due to high fine-tuning costs, scarcity of long texts, and catastrophic values introduced by new token positions, current extended context windows are limited to around 128k tokens. This paper introduces LongRoPE that, for the first time, extends the context window of pre-trained LLMs to an impressive 2048k tokens, with up to only 1k fine-tuning steps at within 256k training lengths, while maintaining performance at the original short context window. This is achieved by three key innovations: (i) we identify and exploit two forms of non-uniformities in positional interpolation through an efficient search, providing a better initialization for fine-tuning and enabling an 8x extension in non-fine-tuning scenarios; (ii) we introduce a progressive extension strategy that first fine-tunes a 256k length LLM and then conducts a second positional interpolation on the fine-tuned extended LLM to achieve a 2048k context window; (iii) we readjust LongRoPE on 8k length to recover the short context window performance. Extensive experiments on LLaMA2 and Mistral across various tasks demonstrate the effectiveness of our method. Models extended via LongRoPE retain the original architecture with minor modifications to the positional embedding, and can reuse most pre-existing optimizations.
WaveCoder: Widespread And Versatile Enhanced Instruction Tuning with Refined Data Generation
Jan 11, 2024Recent work demonstrates that, after being fine-tuned on a high-quality instruction dataset, the resulting model can obtain impressive capabilities to address a wide range of tasks. However, existing methods for instruction data generation often produce duplicate data and are not controllable enough on data quality. In this paper, we extend the generalization of instruction tuning by classifying the instruction data to 4 code-related tasks and propose a LLM-based Generator-Discriminator data process framework to generate diverse, high-quality instruction data from open source code. Hence, we introduce CodeOcean, a dataset comprising 20,000 instruction instances across 4 universal code-related tasks,which is aimed at augmenting the effectiveness of instruction tuning and improving the generalization ability of fine-tuned model. Subsequently, we present WaveCoder, a fine-tuned Code LLM with Widespread And Versatile Enhanced instruction tuning. This model is specifically designed for enhancing instruction tuning of Code Language Models (LLMs). Our experiments demonstrate that Wavecoder models outperform other open-source models in terms of generalization ability across different code-related tasks at the same level of fine-tuning scale. Moreover, Wavecoder exhibits high efficiency in previous code generation tasks. This paper thus offers a significant contribution to the field of instruction data generation and fine-tuning models, providing new insights and tools for enhancing performance in code-related tasks.
Joint Landmark and Structure Learning for Automatic Evaluation of Developmental Dysplasia of the Hip
Jun 10, 2021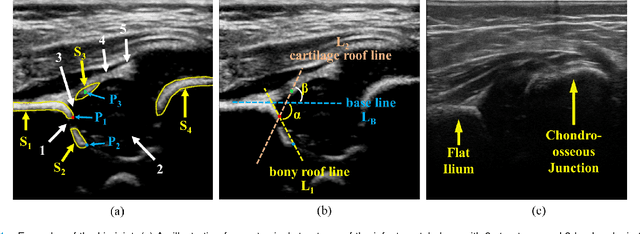
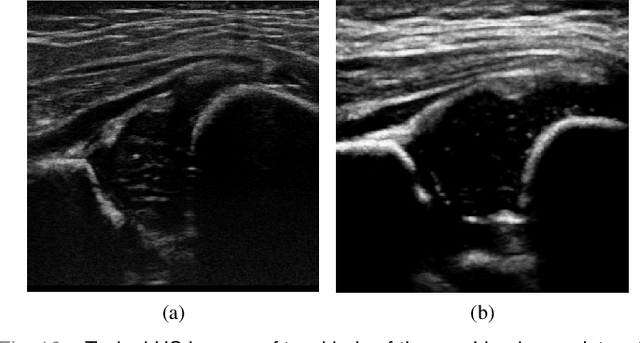
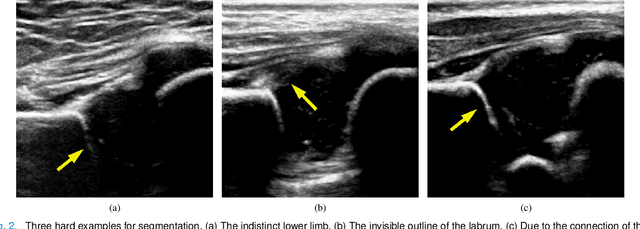
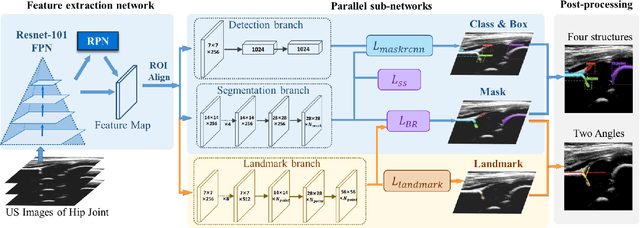
The ultrasound (US) screening of the infant hip is vital for the early diagnosis of developmental dysplasia of the hip (DDH). The US diagnosis of DDH refers to measuring alpha and beta angles that quantify hip joint development. These two angles are calculated from key anatomical landmarks and structures of the hip. However, this measurement process is not trivial for sonographers and usually requires a thorough understanding of complex anatomical structures. In this study, we propose a multi-task framework to learn the relationships among landmarks and structures jointly and automatically evaluate DDH. Our multi-task networks are equipped with three novel modules. Firstly, we adopt Mask R-CNN as the basic framework to detect and segment key anatomical structures and add one landmark detection branch to form a new multi-task framework. Secondly, we propose a novel shape similarity loss to refine the incomplete anatomical structure prediction robustly and accurately. Thirdly, we further incorporate the landmark-structure consistent prior to ensure the consistency of the bony rim estimated from the segmented structure and the detected landmark. In our experiments, 1,231 US images of the infant hip from 632 patients are collected, of which 247 images from 126 patients are tested. The average errors in alpha and beta angles are 2.221 degrees and 2.899 degrees. About 93% and 85% estimates of alpha and beta angles have errors less than 5 degrees, respectively. Experimental results demonstrate that the proposed method can accurately and robustly realize the automatic evaluation of DDH, showing great potential for clinical application.