 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepUniUSTransformer: Towards A Universal UltraSound Model with Prompted Guidance
Jun 03, 2024Ultrasound is a widely used imaging modality in clinical practice due to its low cost, portability, and safety. Current research in general AI for healthcare focuses on large language models and general segmentation models, with insufficient attention to solutions addressing both disease prediction and tissue segmentation. In this study, we propose a novel universal framework for ultrasound, namely DeepUniUSTransformer, which is a promptable model accommodating multiple clinical task. The universality of this model is derived from its versatility across various aspects. It proficiently manages any ultrasound nature, any anatomical position, any input type and excelling not only in segmentation tasks but also in computer-aided diagnosis tasks. We introduce a novel module that incorporates this information as a prompt and seamlessly embedding it within the model's learning process. To train and validate our proposed model, we curated a comprehensive ultrasound dataset from publicly accessible sources, encompassing up to 7 distinct anatomical positions with over 9.7K annotations. Experimental results demonstrate that our model surpasses both a model trained on a single dataset and an ablated version of the network lacking prompt guidance. We will continuously expand the dataset and optimize the task specific prompting mechanism towards the universality in medical ultrasound. Model weights, datasets, and code will be open source to the public.
FetusMapV2: Enhanced Fetal Pose Estimation in 3D Ultrasound
Oct 30, 2023Fetal pose estimation in 3D ultrasound (US) involves identifying a set of associated fetal anatomical landmarks. Its primary objective is to provide comprehensive information about the fetus through landmark connections, thus benefiting various critical applications, such as biometric measurements, plane localization, and fetal movement monitoring. However, accurately estimating the 3D fetal pose in US volume has several challenges, including poor image quality, limited GPU memory for tackling high dimensional data, symmetrical or ambiguous anatomical structures, and considerable variations in fetal poses. In this study, we propose a novel 3D fetal pose estimation framework (called FetusMapV2) to overcome the above challenges. Our contribution is three-fold. First, we propose a heuristic scheme that explores the complementary network structure-unconstrained and activation-unreserved GPU memory management approaches, which can enlarge the input image resolution for better results under limited GPU memory. Second, we design a novel Pair Loss to mitigate confusion caused by symmetrical and similar anatomical structures. It separates the hidden classification task from the landmark localization task and thus progressively eases model learning. Last, we propose a shape priors-based self-supervised learning by selecting the relatively stable landmarks to refine the pose online. Extensive experiments and diverse applications on a large-scale fetal US dataset including 1000 volumes with 22 landmarks per volume demonstrate that our method outperforms other strong competitors.
FFPN: Fourier Feature Pyramid Network for Ultrasound Image Segmentation
Aug 26, 2023
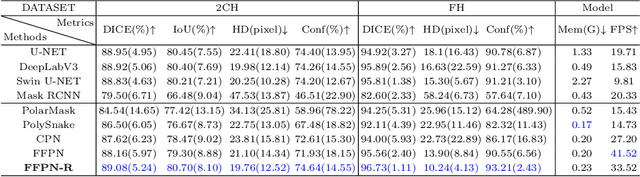
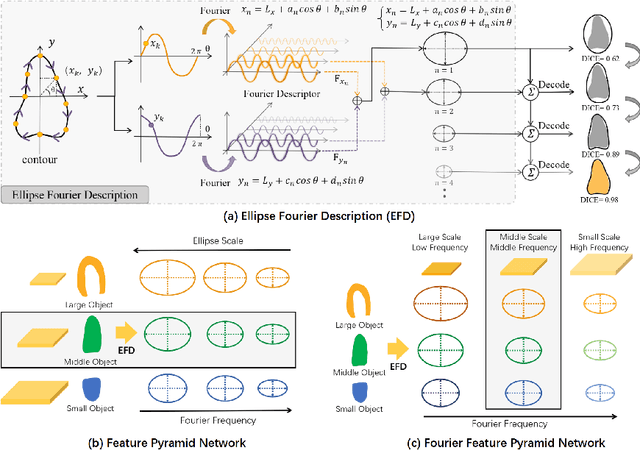
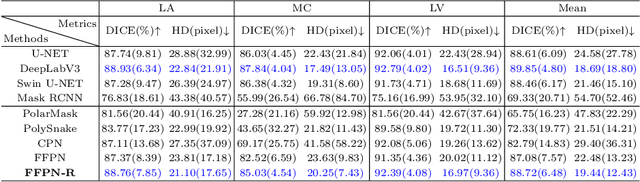
Ultrasound (US) image segmentation is an active research area that requires real-time and highly accurate analysis in many scenarios. The detect-to-segment (DTS) frameworks have been recently proposed to balance accuracy and efficiency. However, existing approaches may suffer from inadequate contour encoding or fail to effectively leverage the encoded results. In this paper, we introduce a novel Fourier-anchor-based DTS framework called Fourier Feature Pyramid Network (FFPN) to address the aforementioned issues. The contributions of this paper are two fold. First, the FFPN utilizes Fourier Descriptors to adequately encode contours. Specifically, it maps Fourier series with similar amplitudes and frequencies into the same layer of the feature map, thereby effectively utilizing the encoded Fourier information. Second, we propose a Contour Sampling Refinement (CSR) module based on the contour proposals and refined features produced by the FFPN. This module extracts rich features around the predicted contours to further capture detailed information and refine the contours. Extensive experimental results on three large and challenging datasets demonstrate that our method outperforms other DTS methods in terms of accuracy and efficiency. Furthermore, our framework can generalize well to other detection or segmentation tasks.
Multi-IMU with Online Self-Consistency for Freehand 3D Ultrasound Reconstruction
Jul 19, 2023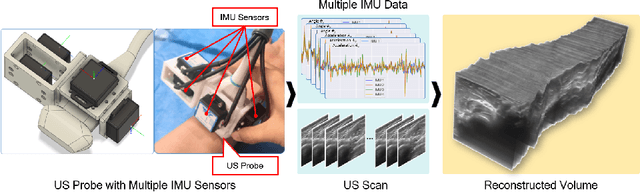
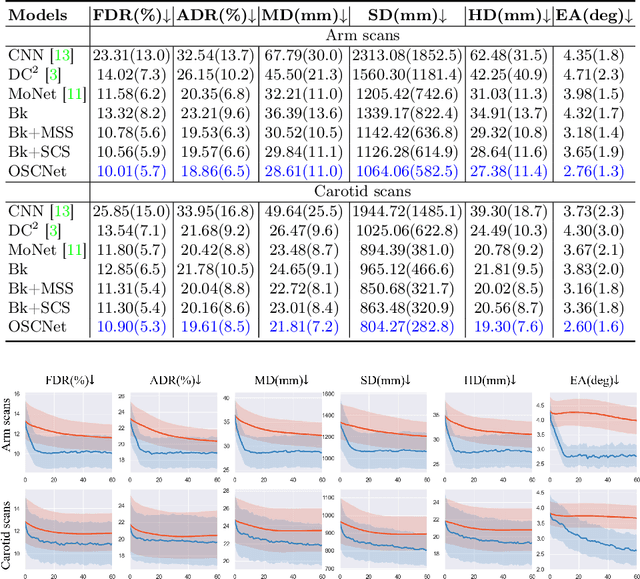
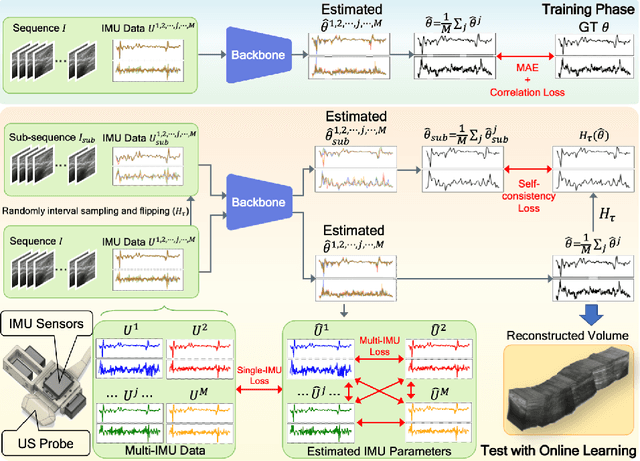
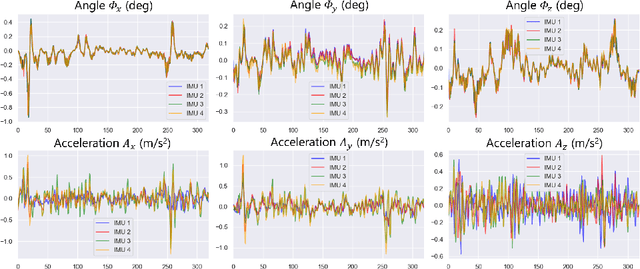
Ultrasound (US) imaging is a popular tool in clinical diagnosis, offering safety, repeatability, and real-time capabilities. Freehand 3D US is a technique that provides a deeper understanding of scanned regions without increasing complexity. However, estimating elevation displacement and accumulation error remains challenging, making it difficult to infer the relative position using images alone. The addition of external lightweight sensors has been proposed to enhance reconstruction performance without adding complexity, which has been shown to be beneficial. We propose a novel online self-consistency network (OSCNet) using multiple inertial measurement units (IMUs) to improve reconstruction performance. OSCNet utilizes a modal-level self-supervised strategy to fuse multiple IMU information and reduce differences between reconstruction results obtained from each IMU data. Additionally, a sequence-level self-consistency strategy is proposed to improve the hierarchical consistency of prediction results among the scanning sequence and its sub-sequences. Experiments on large-scale arm and carotid datasets with multiple scanning tactics demonstrate that our OSCNet outperforms previous methods, achieving state-of-the-art reconstruction performance.
Fourier Test-time Adaptation with Multi-level Consistency for Robust Classification
Jun 05, 2023



Deep classifiers may encounter significant performance degradation when processing unseen testing data from varying centers, vendors, and protocols. Ensuring the robustness of deep models against these domain shifts is crucial for their widespread clinical application. In this study, we propose a novel approach called Fourier Test-time Adaptation (FTTA), which employs a dual-adaptation design to integrate input and model tuning, thereby jointly improving the model robustness. The main idea of FTTA is to build a reliable multi-level consistency measurement of paired inputs for achieving self-correction of prediction. Our contribution is two-fold. First, we encourage consistency in global features and local attention maps between the two transformed images of the same input. Here, the transformation refers to Fourier-based input adaptation, which can transfer one unseen image into source style to reduce the domain gap. Furthermore, we leverage style-interpolated images to enhance the global and local features with learnable parameters, which can smooth the consistency measurement and accelerate convergence. Second, we introduce a regularization technique that utilizes style interpolation consistency in the frequency space to encourage self-consistency in the logit space of the model output. This regularization provides strong self-supervised signals for robustness enhancement. FTTA was extensively validated on three large classification datasets with different modalities and organs. Experimental results show that FTTA is general and outperforms other strong state-of-the-art methods.
Segment Anything Model for Medical Images?
May 01, 2023



The Segment Anything Model (SAM) is the first foundation model for general image segmentation. It designed a novel promotable segmentation task, ensuring zero-shot image segmentation using the pre-trained model via two main modes including automatic everything and manual prompt. SAM has achieved impressive results on various natural image segmentation tasks. However, medical image segmentation (MIS) is more challenging due to the complex modalities, fine anatomical structures, uncertain and complex object boundaries, and wide-range object scales. Meanwhile, zero-shot and efficient MIS can well reduce the annotation time and boost the development of medical image analysis. Hence, SAM seems to be a potential tool and its performance on large medical datasets should be further validated. We collected and sorted 52 open-source datasets, and built a large medical segmentation dataset with 16 modalities, 68 objects, and 553K slices. We conducted a comprehensive analysis of different SAM testing strategies on the so-called COSMOS 553K dataset. Extensive experiments validate that SAM performs better with manual hints like points and boxes for object perception in medical images, leading to better performance in prompt mode compared to everything mode. Additionally, SAM shows remarkable performance in some specific objects and modalities, but is imperfect or even totally fails in other situations. Finally, we analyze the influence of different factors (e.g., the Fourier-based boundary complexity and size of the segmented objects) on SAM's segmentation performance. Extensive experiments validate that SAM's zero-shot segmentation capability is not sufficient to ensure its direct application to the MIS.
Online Reflective Learning for Robust Medical Image Segmentation
Jul 01, 2022
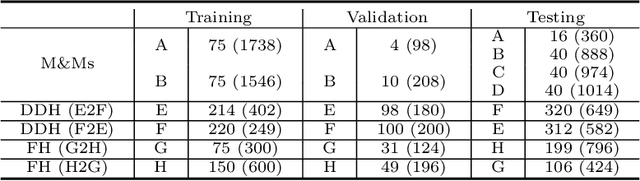
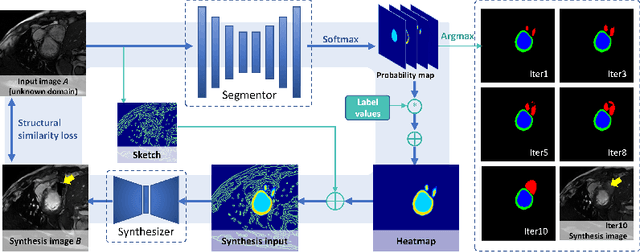
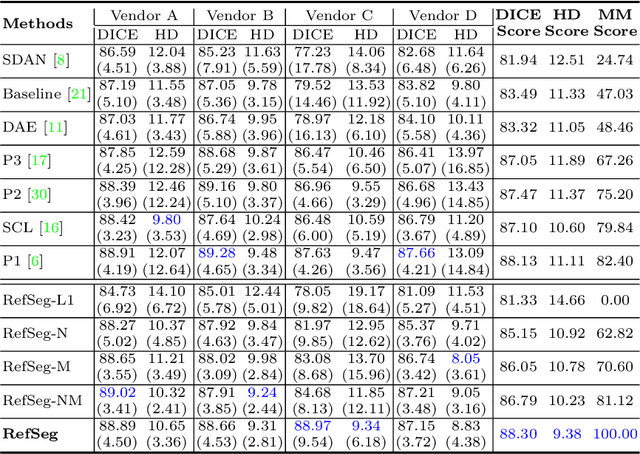
Deep segmentation models often face the failure risks when the testing image presents unseen distributions. Improving model robustness against these risks is crucial for the large-scale clinical application of deep models. In this study, inspired by human learning cycle, we propose a novel online reflective learning framework (RefSeg) to improve segmentation robustness. Based on the reflection-on-action conception, our RefSeg firstly drives the deep model to take action to obtain semantic segmentation. Then, RefSeg triggers the model to reflect itself. Because making deep models realize their segmentation failures during testing is challenging, RefSeg synthesizes a realistic proxy image from the semantic mask to help deep models build intuitive and effective reflections. This proxy translates and emphasizes the segmentation flaws. By maximizing the structural similarity between the raw input and the proxy, the reflection-on-action loop is closed with segmentation robustness improved. RefSeg runs in the testing phase and is general for segmentation models. Extensive validation on three medical image segmentation tasks with a public cardiac MR dataset and two in-house large ultrasound datasets show that our RefSeg remarkably improves model robustness and reports state-of-the-art performance over strong competitors.
Weakly-supervised High-fidelity Ultrasound Video Synthesis with Feature Decoupling
Jul 01, 2022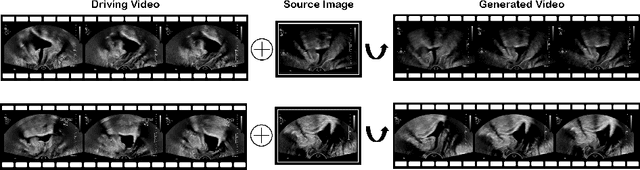
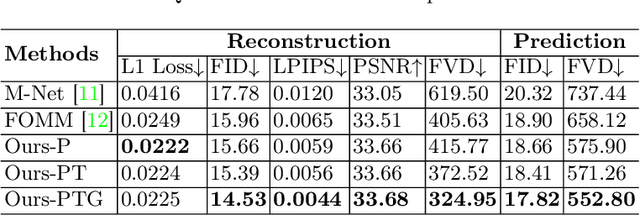
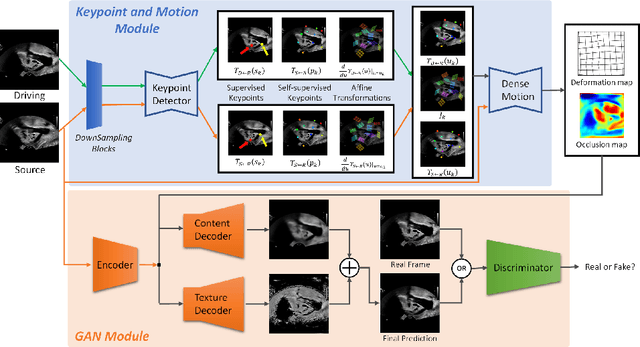

Ultrasound (US) is widely used for its advantages of real-time imaging, radiation-free and portability. In clinical practice, analysis and diagnosis often rely on US sequences rather than a single image to obtain dynamic anatomical information. This is challenging for novices to learn because practicing with adequate videos from patients is clinically unpractical. In this paper, we propose a novel framework to synthesize high-fidelity US videos. Specifically, the synthesis videos are generated by animating source content images based on the motion of given driving videos. Our highlights are three-fold. First, leveraging the advantages of self- and fully-supervised learning, our proposed system is trained in weakly-supervised manner for keypoint detection. These keypoints then provide vital information for handling complex high dynamic motions in US videos. Second, we decouple content and texture learning using the dual decoders to effectively reduce the model learning difficulty. Last, we adopt the adversarial training strategy with GAN losses for further improving the sharpness of the generated videos, narrowing the gap between real and synthesis videos. We validate our method on a large in-house pelvic dataset with high dynamic motion. Extensive evaluation metrics and user study prove the effectiveness of our proposed method.
Fine-grained Correlation Loss for Regression
Jul 01, 2022
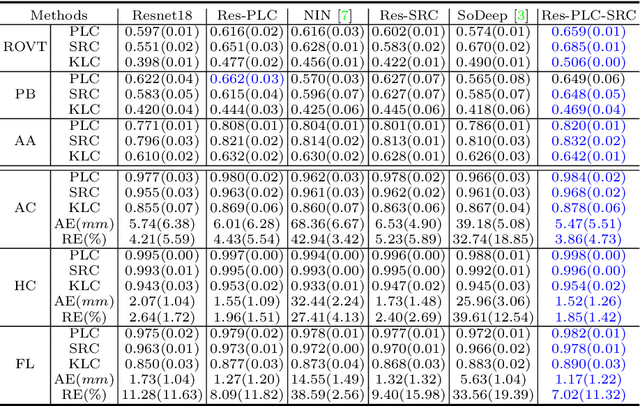
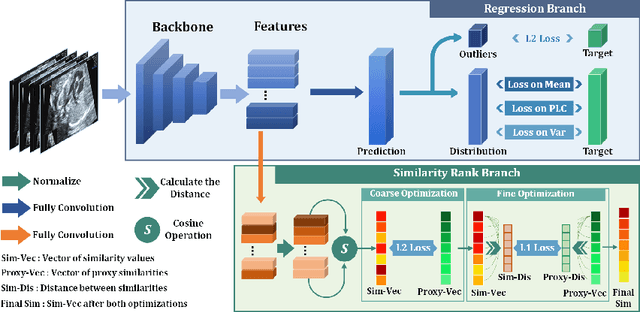
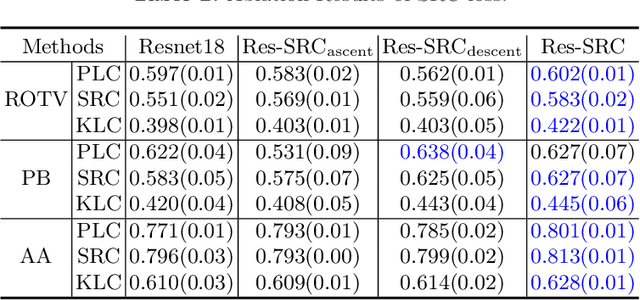
Regression learning is classic and fundamental for medical image analysis. It provides the continuous mapping for many critical applications, like the attribute estimation, object detection, segmentation and non-rigid registration. However, previous studies mainly took the case-wise criteria, like the mean square errors, as the optimization objectives. They ignored the very important population-wise correlation criterion, which is exactly the final evaluation metric in many tasks. In this work, we propose to revisit the classic regression tasks with novel investigations on directly optimizing the fine-grained correlation losses. We mainly explore two complementary correlation indexes as learnable losses: Pearson linear correlation (PLC) and Spearman rank correlation (SRC). The contributions of this paper are two folds. First, for the PLC on global level, we propose a strategy to make it robust against the outliers and regularize the key distribution factors. These efforts significantly stabilize the learning and magnify the efficacy of PLC. Second, for the SRC on local level, we propose a coarse-to-fine scheme to ease the learning of the exact ranking order among samples. Specifically, we convert the learning for the ranking of samples into the learning of similarity relationships among samples. We extensively validate our method on two typical ultrasound image regression tasks, including the image quality assessment and bio-metric measurement. Experiments prove that, with the fine-grained guidance in directly optimizing the correlation, the regression performances are significantly improved. Our proposed correlation losses are general and can be extended to more important applications.
Sketch guided and progressive growing GAN for realistic and editable ultrasound image synthesis
Apr 19, 2022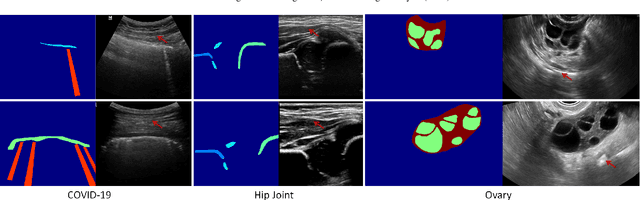
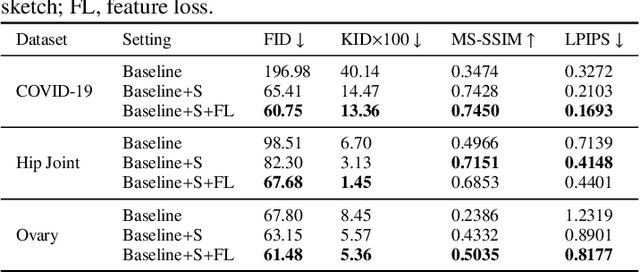
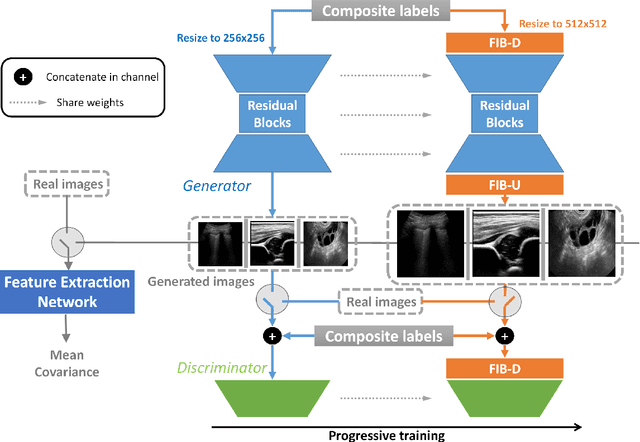

Ultrasound (US) imaging is widely used for anatomical structure inspection in clinical diagnosis. The training of new sonographers and deep learning based algorithms for US image analysis usually requires a large amount of data. However, obtaining and labeling large-scale US imaging data are not easy tasks, especially for diseases with low incidence. Realistic US image synthesis can alleviate this problem to a great extent. In this paper, we propose a generative adversarial network (GAN) based image synthesis framework. Our main contributions include: 1) we present the first work that can synthesize realistic B-mode US images with high-resolution and customized texture editing features; 2) to enhance structural details of generated images, we propose to introduce auxiliary sketch guidance into a conditional GAN. We superpose the edge sketch onto the object mask and use the composite mask as the network input; 3) to generate high-resolution US images, we adopt a progressive training strategy to gradually generate high-resolution images from low-resolution images. In addition, a feature loss is proposed to minimize the difference of high-level features between the generated and real images, which further improves the quality of generated images; 4) the proposed US image synthesis method is quite universal and can also be generalized to the US images of other anatomical structures besides the three ones tested in our study (lung, hip joint, and ovary); 5) extensive experiments on three large US image datasets are conducted to validate our method. Ablation studies, customized texture editing, user studies, and segmentation tests demonstrate promising results of our method in synthesizing realistic US images.