 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBalancing Image Compression and Generation with Bootstrapped Tokenization
Jun 04, 2026Despite progress in image tokenization, standard methods encode redundant information by mixing all granularities within each token, thus redundancy persists between tokens. The mix of information of different granularity also complicates the training of generators. This paper introduces SelfBootTok, a method that resolves this by cleanly decomposing information into global and local token groups. Through self-bootstrapped learning, the model predicts local details exclusively from global tokens, shifting the burden of visual details from the generator to the tokenizer. Consequently, our generator is far more efficient, requiring only global tokens and reducing computation by approximately 40%, while delivering superior reconstruction and generation. Moreover, this paradigm scales elegantly: by leveraging more data or parameters to self-supervise local representation learning, SelfBootTok achieves a new state-of-the-art gFID score of 1.56 using only 64 tokens.
GOPAgen: Motion-Aware and Efficient Agentic Long-Video Understanding with Structural Memory and Hierarchical Reasoning
Jun 03, 2026Despite significant progress in agentic long video understanding, existing methods still lack detailed motion comprehension coupled with an efficient memory architecture. In this paper, we propose GOPAgen, a novel approach that first integrates video codec into the video understanding framework via a meticulously designed motion agent trained on Groups of Pictures (GOPs) from video codec. We further develop a GOP tree reasoning algorithm, which is naturally aligned with video codec and enhances the model's ability to understand local detailed motions in videos. Additionally, we carefully design a structural memory mechanism that integrates local motion information with detailed captions in structural pages, and propose an efficient coarse-to-fine zoom-in algorithm to fully exploit the structural memory. Furthermore, we incorporate a motion vector database into the framework to enable efficient retrieval of motion vectors at different granularities. Overall, our method achieves superior Video Question Answering (VQA) performance on various video understanding benchmarks, including MotionBench and Egoschema, thereby demonstrating the superiority of our proposed framework.
RectifID: Personalizing Rectified Flow with Anchored Classifier Guidance
May 23, 2024Customizing diffusion models to generate identity-preserving images from user-provided reference images is an intriguing new problem. The prevalent approaches typically require training on extensive domain-specific images to achieve identity preservation, which lacks flexibility across different use cases. To address this issue, we exploit classifier guidance, a training-free technique that steers diffusion models using an existing classifier, for personalized image generation. Our study shows that based on a recent rectified flow framework, the major limitation of vanilla classifier guidance in requiring a special classifier can be resolved with a simple fixed-point solution, allowing flexible personalization with off-the-shelf image discriminators. Moreover, its solving procedure proves to be stable when anchored to a reference flow trajectory, with a convergence guarantee. The derived method is implemented on rectified flow with different off-the-shelf image discriminators, delivering advantageous personalization results for human faces, live subjects, and certain objects. Code is available at https://github.com/feifeiobama/RectifID.
Fourier Test-time Adaptation with Multi-level Consistency for Robust Classification
Jun 05, 2023



Deep classifiers may encounter significant performance degradation when processing unseen testing data from varying centers, vendors, and protocols. Ensuring the robustness of deep models against these domain shifts is crucial for their widespread clinical application. In this study, we propose a novel approach called Fourier Test-time Adaptation (FTTA), which employs a dual-adaptation design to integrate input and model tuning, thereby jointly improving the model robustness. The main idea of FTTA is to build a reliable multi-level consistency measurement of paired inputs for achieving self-correction of prediction. Our contribution is two-fold. First, we encourage consistency in global features and local attention maps between the two transformed images of the same input. Here, the transformation refers to Fourier-based input adaptation, which can transfer one unseen image into source style to reduce the domain gap. Furthermore, we leverage style-interpolated images to enhance the global and local features with learnable parameters, which can smooth the consistency measurement and accelerate convergence. Second, we introduce a regularization technique that utilizes style interpolation consistency in the frequency space to encourage self-consistency in the logit space of the model output. This regularization provides strong self-supervised signals for robustness enhancement. FTTA was extensively validated on three large classification datasets with different modalities and organs. Experimental results show that FTTA is general and outperforms other strong state-of-the-art methods.
Segment Anything Model for Medical Images?
May 01, 2023



The Segment Anything Model (SAM) is the first foundation model for general image segmentation. It designed a novel promotable segmentation task, ensuring zero-shot image segmentation using the pre-trained model via two main modes including automatic everything and manual prompt. SAM has achieved impressive results on various natural image segmentation tasks. However, medical image segmentation (MIS) is more challenging due to the complex modalities, fine anatomical structures, uncertain and complex object boundaries, and wide-range object scales. Meanwhile, zero-shot and efficient MIS can well reduce the annotation time and boost the development of medical image analysis. Hence, SAM seems to be a potential tool and its performance on large medical datasets should be further validated. We collected and sorted 52 open-source datasets, and built a large medical segmentation dataset with 16 modalities, 68 objects, and 553K slices. We conducted a comprehensive analysis of different SAM testing strategies on the so-called COSMOS 553K dataset. Extensive experiments validate that SAM performs better with manual hints like points and boxes for object perception in medical images, leading to better performance in prompt mode compared to everything mode. Additionally, SAM shows remarkable performance in some specific objects and modalities, but is imperfect or even totally fails in other situations. Finally, we analyze the influence of different factors (e.g., the Fourier-based boundary complexity and size of the segmented objects) on SAM's segmentation performance. Extensive experiments validate that SAM's zero-shot segmentation capability is not sufficient to ensure its direct application to the MIS.
Missing Modality meets Meta Sampling (M3S): An Efficient Universal Approach for Multimodal Sentiment Analysis with Missing Modality
Oct 07, 2022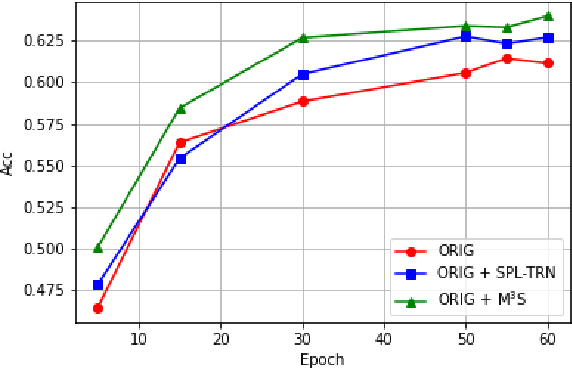
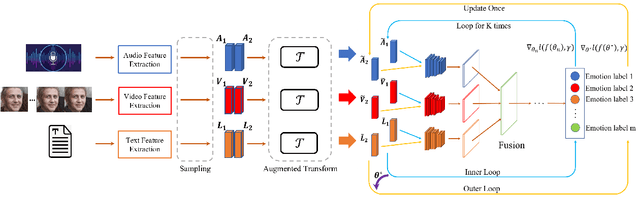
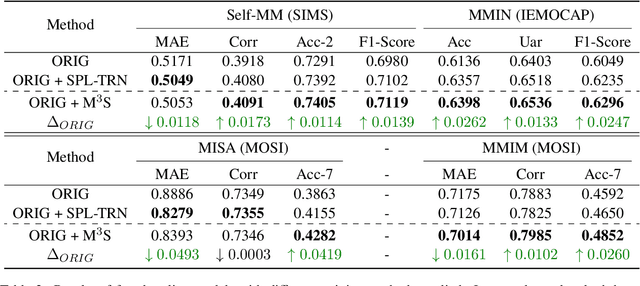
Multimodal sentiment analysis (MSA) is an important way of observing mental activities with the help of data captured from multiple modalities. However, due to the recording or transmission error, some modalities may include incomplete data. Most existing works that address missing modalities usually assume a particular modality is completely missing and seldom consider a mixture of missing across multiple modalities. In this paper, we propose a simple yet effective meta-sampling approach for multimodal sentiment analysis with missing modalities, namely Missing Modality-based Meta Sampling (M3S). To be specific, M3S formulates a missing modality sampling strategy into the modal agnostic meta-learning (MAML) framework. M3S can be treated as an efficient add-on training component on existing models and significantly improve their performances on multimodal data with a mixture of missing modalities. We conduct experiments on IEMOCAP, SIMS and CMU-MOSI datasets, and superior performance is achieved compared with recent state-of-the-art methods.