 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Robust RAG: Do We Still Need Complex Robust Training in the Era of Powerful LLMs?
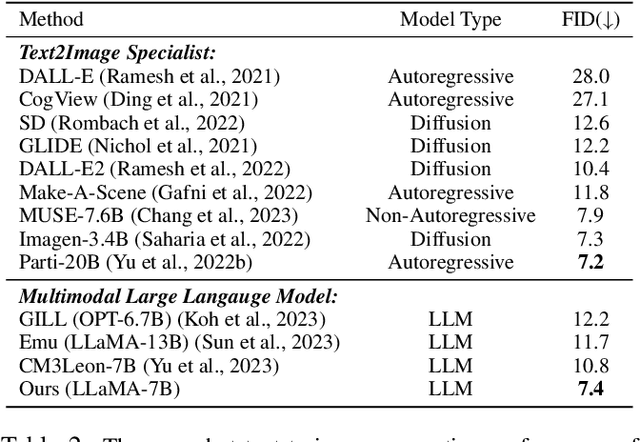
Feb 17, 2025Retrieval-augmented generation (RAG) systems often suffer from performance degradation when encountering noisy or irrelevant documents, driving researchers to develop sophisticated training strategies to enhance their robustness against such retrieval noise. However, as large language models (LLMs) continue to advance, the necessity of these complex training methods is increasingly questioned. In this paper, we systematically investigate whether complex robust training strategies remain necessary as model capacity grows. Through comprehensive experiments spanning multiple model architectures and parameter scales, we evaluate various document selection methods and adversarial training techniques across diverse datasets. Our extensive experiments consistently demonstrate that as models become more powerful, the performance gains brought by complex robust training methods drop off dramatically. We delve into the rationale and find that more powerful models inherently exhibit superior confidence calibration, better generalization across datasets (even when trained with randomly selected documents), and optimal attention mechanisms learned with simpler strategies. Our findings suggest that RAG systems can benefit from simpler architectures and training strategies as models become more powerful, enabling more scalable applications with minimal complexity.
Following the Autoregressive Nature of LLM Embeddings via Compression and Alignment
Feb 17, 2025A new trend uses LLMs as dense text encoders via contrastive learning. However, since LLM embeddings predict the probability distribution of the next token, they are inherently generative and distributive, conflicting with contrastive learning, which requires embeddings to capture full-text semantics and align via cosine similarity. This discrepancy hinders the full utilization of LLMs' pre-training capabilities, resulting in inefficient learning. In response to this issue, we propose AutoRegEmbed, a new contrastive learning method built on embedding conditional probability distributions, which integrates two core tasks: information compression and conditional distribution alignment. The information compression task encodes text into the embedding space, ensuring that the embedding vectors capture global semantics. The conditional distribution alignment task focuses on aligning text embeddings with positive samples embeddings by leveraging the conditional distribution of embeddings while simultaneously reducing the likelihood of generating negative samples from text embeddings, thereby achieving embedding alignment and uniformity. Experimental results demonstrate that our method significantly outperforms traditional contrastive learning approaches and achieves performance comparable to state-of-the-art models when using the same amount of data.
RectifID: Personalizing Rectified Flow with Anchored Classifier Guidance
May 23, 2024Customizing diffusion models to generate identity-preserving images from user-provided reference images is an intriguing new problem. The prevalent approaches typically require training on extensive domain-specific images to achieve identity preservation, which lacks flexibility across different use cases. To address this issue, we exploit classifier guidance, a training-free technique that steers diffusion models using an existing classifier, for personalized image generation. Our study shows that based on a recent rectified flow framework, the major limitation of vanilla classifier guidance in requiring a special classifier can be resolved with a simple fixed-point solution, allowing flexible personalization with off-the-shelf image discriminators. Moreover, its solving procedure proves to be stable when anchored to a reference flow trajectory, with a convergence guarantee. The derived method is implemented on rectified flow with different off-the-shelf image discriminators, delivering advantageous personalization results for human faces, live subjects, and certain objects. Code is available at https://github.com/feifeiobama/RectifID.
Harder Tasks Need More Experts: Dynamic Routing in MoE Models
Mar 12, 2024In this paper, we introduce a novel dynamic expert selection framework for Mixture of Experts (MoE) models, aiming to enhance computational efficiency and model performance by adjusting the number of activated experts based on input difficulty. Unlike traditional MoE approaches that rely on fixed Top-K routing, which activates a predetermined number of experts regardless of the input's complexity, our method dynamically selects experts based on the confidence level in expert selection for each input. This allows for a more efficient utilization of computational resources, activating more experts for complex tasks requiring advanced reasoning and fewer for simpler tasks. Through extensive evaluations, our dynamic routing method demonstrates substantial improvements over conventional Top-2 routing across various benchmarks, achieving an average improvement of 0.7% with less than 90% activated parameters. Further analysis shows our model dispatches more experts to tasks requiring complex reasoning skills, like BBH, confirming its ability to dynamically allocate computational resources in alignment with the input's complexity. Our findings also highlight a variation in the number of experts needed across different layers of the transformer model, offering insights into the potential for designing heterogeneous MoE frameworks. The code and models are available at https://github.com/ZhenweiAn/Dynamic_MoE.
Probing Multimodal Large Language Models for Global and Local Semantic Representation
Feb 27, 2024



The success of large language models has inspired researchers to transfer their exceptional representing ability to other modalities. Several recent works leverage image-caption alignment datasets to train multimodal large language models (MLLMs), which achieve state-of-the-art performance on image-to-text tasks. However, there are very few studies exploring whether MLLMs truly understand the complete image information, i.e., global information, or if they can only capture some local object information. In this study, we find that the intermediate layers of models can encode more global semantic information, whose representation vectors perform better on visual-language entailment tasks, rather than the topmost layers. We further probe models for local semantic representation through object detection tasks. And we draw a conclusion that the topmost layers may excessively focus on local information, leading to a diminished ability to encode global information.
Video-LaVIT: Unified Video-Language Pre-training with Decoupled Visual-Motional Tokenization
Feb 06, 2024



In light of recent advances in multimodal Large Language Models (LLMs), there is increasing attention to scaling them from image-text data to more informative real-world videos. Compared to static images, video poses unique challenges for effective large-scale pre-training due to the modeling of its spatiotemporal dynamics. In this paper, we address such limitations in video-language pre-training with an efficient video decomposition that represents each video as keyframes and temporal motions. These are then adapted to an LLM using well-designed tokenizers that discretize visual and temporal information as a few tokens, thus enabling unified generative pre-training of videos, images, and text. At inference, the generated tokens from the LLM are carefully recovered to the original continuous pixel space to create various video content. Our proposed framework is both capable of comprehending and generating image and video content, as demonstrated by its competitive performance across 13 multimodal benchmarks in image and video understanding and generation. Our code and models will be available at https://video-lavit.github.io.
A Step Closer to Comprehensive Answers: Constrained Multi-Stage Question Decomposition with Large Language Models
Nov 13, 2023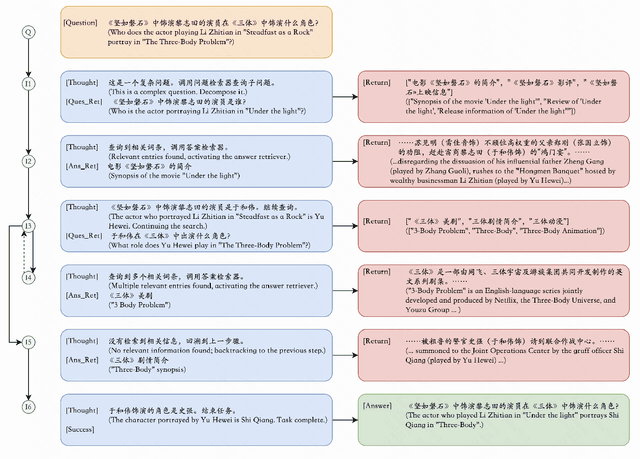
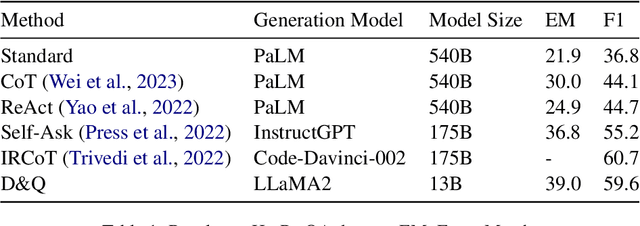
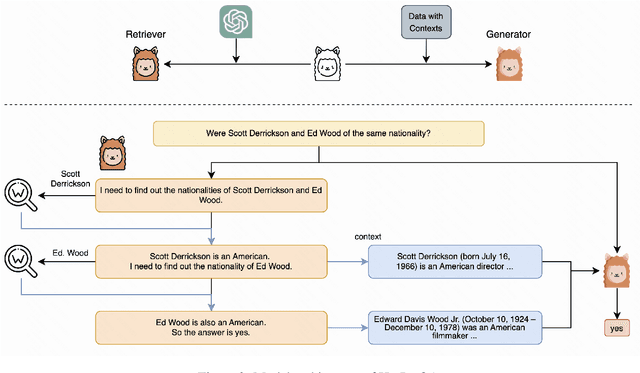

While large language models exhibit remarkable performance in the Question Answering task, they are susceptible to hallucinations. Challenges arise when these models grapple with understanding multi-hop relations in complex questions or lack the necessary knowledge for a comprehensive response. To address this issue, we introduce the "Decompose-and-Query" framework (D&Q). This framework guides the model to think and utilize external knowledge similar to ReAct, while also restricting its thinking to reliable information, effectively mitigating the risk of hallucinations. Experiments confirm the effectiveness of D&Q: On our ChitChatQA dataset, D&Q does not lose to ChatGPT in 67% of cases; on the HotPotQA question-only setting, D&Q achieved an F1 score of 59.6%. Our code is available at https://github.com/alkaidpku/DQ-ToolQA.
Unified Language-Vision Pretraining in LLM with Dynamic Discrete Visual Tokenization
Sep 29, 2023
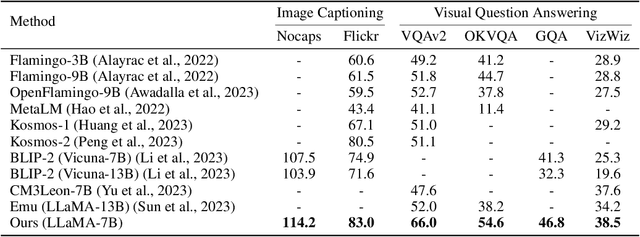

Recently, the remarkable advance of the Large Language Model (LLM) has inspired researchers to transfer its extraordinary reasoning capability to both vision and language data. However, the prevailing approaches primarily regard the visual input as a prompt and focus exclusively on optimizing the text generation process conditioned upon vision content by a frozen LLM. Such an inequitable treatment of vision and language heavily constrains the model's potential. In this paper, we break through this limitation by representing both vision and language in a unified form. Specifically, we introduce a well-designed visual tokenizer to translate the non-linguistic image into a sequence of discrete tokens like a foreign language that LLM can read. The resulting visual tokens encompass high-level semantics worthy of a word and also support dynamic sequence length varying from the image. Coped with this tokenizer, the presented foundation model called LaVIT can handle both image and text indiscriminately under the same generative learning paradigm. This unification empowers LaVIT to serve as an impressive generalist interface to understand and generate multi-modal content simultaneously. Extensive experiments further showcase that it outperforms the existing models by a large margin on massive vision-language tasks. Our code and models will be available at https://github.com/jy0205/LaVIT.
In-situ monitoring additive manufacturing process with AI edge computing
Jan 02, 2023



In-situ monitoring system can be used to monitor the quality of additive manufacturing (AM) processes. In the case of digital image correlation (DIC) based in-situ monitoring systems, high-speed cameras were used to capture images of high resolutions. This paper proposed a novel in-situ monitoring system to accelerate the process of digital images using artificial intelligence (AI) edge computing board. It built a visual transformer based video super resolution (ViTSR) network to reconstruct high resolution (HR) videos frames. Fully convolutional network (FCN) was used to simultaneously extract the geometric characteristics of molten pool and plasma arc during the AM processes. Compared with 6 state-of-the-art super resolution methods, ViTSR ranks first in terms of peak signal to noise ratio (PSNR). The PSNR of ViTSR for 4x super resolution reached 38.16 dB on test data with input size of 75 pixels x 75 pixels. Inference time of ViTSR and FCN was optimized to 50.97 ms and 67.86 ms on AI edge board after operator fusion and model pruning. The total inference time of the proposed system was 118.83 ms, which meets the requirement of real-time quality monitoring with low cost in-situ monitoring equipment during AM processes. The proposed system achieved an accuracy of 96.34% on the multi-objects extraction task and can be applied to different AM processes.
Encoding Implicit Relation Requirements for Relation Extraction: A Joint Inference Approach
Nov 09, 2018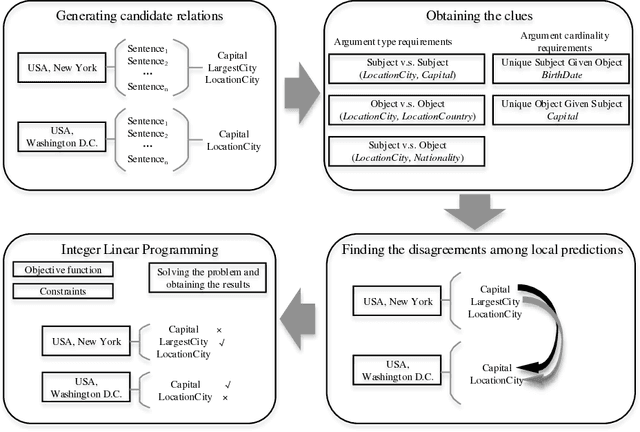
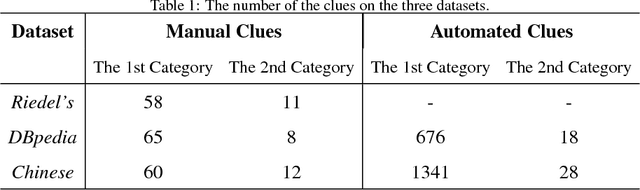
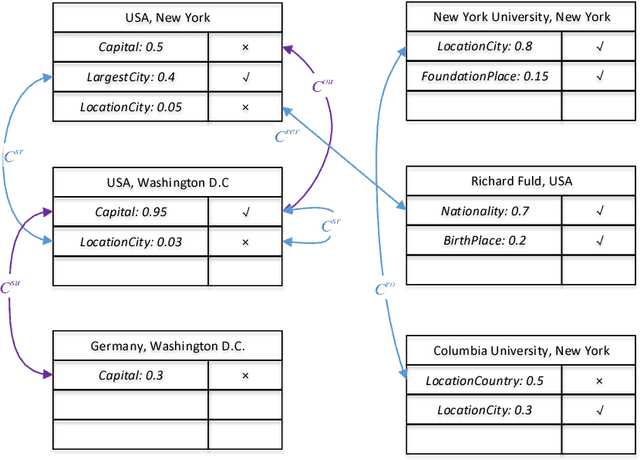

Relation extraction is the task of identifying predefined relationship between entities, and plays an essential role in information extraction, knowledge base construction, question answering and so on. Most existing relation extractors make predictions for each entity pair locally and individually, while ignoring implicit global clues available across different entity pairs and in the knowledge base, which often leads to conflicts among local predictions from different entity pairs. This paper proposes a joint inference framework that employs such global clues to resolve disagreements among local predictions. We exploit two kinds of clues to generate constraints which can capture the implicit type and cardinality requirements of a relation. Those constraints can be examined in either hard style or soft style, both of which can be effectively explored in an integer linear program formulation. Experimental results on both English and Chinese datasets show that our proposed framework can effectively utilize those two categories of global clues and resolve the disagreements among local predictions, thus improve various relation extractors when such clues are applicable to the datasets. Our experiments also indicate that the clues learnt automatically from existing knowledge bases perform comparably to or better than those refined by human.
* to appear in Artificial Intelligence