 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Rollout Editing for Reducing Overthinking in RL-Trained Reasoning Models
Jun 16, 2026Long-form chain-of-thought reasoning can improve LLM performance on complex tasks, but models often continue generating unnecessary reasoning after a correct answer has emerged. We refer to this behavior as overthinking. We study this phenomenon from the perspective of GRPO-style reinforcement learning (RL) post-training, framing it as a training-time credit-assignment problem rather than merely a decoding-time stopping problem. In rollouts sampled at the onset of GRPO training, we observe that successful trajectories can exhibit a slightly higher degree of overthinking than unsuccessful trajectories for the same prompts. This early imbalance provides a starting point for an undesirable feedback loop: because GRPO assigns sequence-level credit, it cannot distinguish the solution-reaching prefix from the unnecessary continuation that lengthens a successful trajectory. Both receive positive update signal, allowing the initial imbalance to grow into more severe overthinking during training. To address this issue, we introduce Dynamic Rollout Editing (DRE), a training-time intervention for successful trajectories that continue thinking after answer emergence. DRE preserves the accepted verified prefix, edits the remaining thinking, and prefers the edited trajectory within the same RL group, weakening the preference signal for unnecessary thinking without penalizing the reasoning needed to reach the answer. Experiments across diverse tasks show the effectiveness of DRE.
Projecting Out the Malice: A Global Subspace Approach to LLM Detoxification
Jan 09, 2026Large language models (LLMs) exhibit exceptional performance but pose inherent risks of generating toxic content, restricting their safe deployment. While traditional methods (e.g., alignment) adjust output preferences, they fail to eliminate underlying toxic regions in parameters, leaving models vulnerable to adversarial attacks. Prior mechanistic studies characterize toxic regions as "toxic vectors" or "layer-wise subspaces", yet our analysis identifies critical limitations: i) Removed toxic vectors can be reconstructed via linear combinations of non-toxic vectors, demanding targeting of entire toxic subspace; ii) Contrastive objective over limited samples inject noise into layer-wise subspaces, hindering stable extraction. These highlight the challenge of identifying robust toxic subspace and removing them. Therefore, we propose GLOSS (GLobal tOxic Subspace Suppression), a lightweight method that mitigates toxicity by identifying and eliminating this global subspace from FFN parameters. Experiments on LLMs (e.g., Qwen3) show GLOSS achieves SOTA detoxification while preserving general capabilities without requiring large-scale retraining. WARNING: This paper contains context which is toxic in nature.
Circular Reasoning: Understanding Self-Reinforcing Loops in Large Reasoning Models
Jan 09, 2026Despite the success of test-time scaling, Large Reasoning Models (LRMs) frequently encounter repetitive loops that lead to computational waste and inference failure. In this paper, we identify a distinct failure mode termed Circular Reasoning. Unlike traditional model degeneration, this phenomenon manifests as a self-reinforcing trap where generated content acts as a logical premise for its own recurrence, compelling the reiteration of preceding text. To systematically analyze this phenomenon, we introduce LoopBench, a dataset designed to capture two distinct loop typologies: numerical loops and statement loops. Mechanistically, we characterize circular reasoning as a state collapse exhibiting distinct boundaries, where semantic repetition precedes textual repetition. We reveal that reasoning impasses trigger the loop onset, which subsequently persists as an inescapable cycle driven by a self-reinforcing V-shaped attention mechanism. Guided by these findings, we employ the Cumulative Sum (CUSUM) algorithm to capture these precursors for early loop prediction. Experiments across diverse LRMs validate its accuracy and elucidate the stability of long-chain reasoning.
Stop Spinning Wheels: Mitigating LLM Overthinking via Mining Patterns for Early Reasoning Exit
Aug 25, 2025



Large language models (LLMs) enhance complex reasoning tasks by scaling the individual thinking process. However, prior work shows that overthinking can degrade overall performance. Motivated by observed patterns in thinking length and content length, we categorize reasoning into three stages: insufficient exploration stage, compensatory reasoning stage, and reasoning convergence stage. Typically, LLMs produce correct answers in the compensatory reasoning stage, whereas reasoning convergence often triggers overthinking, causing increased resource usage or even infinite loops. Therefore, mitigating overthinking hinges on detecting the end of the compensatory reasoning stage, defined as the Reasoning Completion Point (RCP). RCP typically appears at the end of the first complete reasoning cycle and can be identified by querying the LLM sentence by sentence or monitoring the probability of an end-of-thinking token (e.g., \texttt{</think>}), though these methods lack an efficient and precise balance. To improve this, we mine more sensitive and consistent RCP patterns and develop a lightweight thresholding strategy based on heuristic rules. Experimental evaluations on benchmarks (AIME24, AIME25, GPQA-D) demonstrate that the proposed method reduces token consumption while preserving or enhancing reasoning accuracy.
Distilling the Implicit Multi-Branch Structure in LLMs' Reasoning via Reinforcement Learning
May 22, 2025Distilling reasoning paths from teacher to student models via supervised fine-tuning (SFT) provides a shortcut for improving the reasoning ability of smaller Large Language Models (LLMs). However, the reasoning paths generated by teacher models often reflect only surface-level traces of their underlying authentic reasoning. Insights from cognitive neuroscience suggest that authentic reasoning involves a complex interweaving between meta-reasoning (which selects appropriate sub-problems from multiple candidates) and solving (which addresses the sub-problem). This implies authentic reasoning has an implicit multi-branch structure. Supervised fine-tuning collapses this rich structure into a flat sequence of token prediction in the teacher's reasoning path, preventing effective distillation of this structure to students. To address this limitation, we propose RLKD, a reinforcement learning (RL)-based distillation framework guided by a novel Generative Structure Reward Model (GSRM). Our GSRM converts reasoning paths into multiple meta-reasoning-solving steps and computes rewards to measure structural alignment between student and teacher reasoning. RLKD combines this reward with RL, enabling student LLMs to internalize the teacher's implicit multi-branch reasoning structure rather than merely mimicking fixed output paths. Experiments show RLKD surpasses standard SFT-RL pipelines even when trained on 0.1% of data under an RL-only regime, unlocking greater student reasoning potential than SFT-based distillation.
FlightGPT: Towards Generalizable and Interpretable UAV Vision-and-Language Navigation with Vision-Language Models
May 19, 2025Unmanned Aerial Vehicle (UAV) Vision-and-Language Navigation (VLN) is vital for applications such as disaster response, logistics delivery, and urban inspection. However, existing methods often struggle with insufficient multimodal fusion, weak generalization, and poor interpretability. To address these challenges, we propose FlightGPT, a novel UAV VLN framework built upon Vision-Language Models (VLMs) with powerful multimodal perception capabilities. We design a two-stage training pipeline: first, Supervised Fine-Tuning (SFT) using high-quality demonstrations to improve initialization and structured reasoning; then, Group Relative Policy Optimization (GRPO) algorithm, guided by a composite reward that considers goal accuracy, reasoning quality, and format compliance, to enhance generalization and adaptability. Furthermore, FlightGPT introduces a Chain-of-Thought (CoT)-based reasoning mechanism to improve decision interpretability. Extensive experiments on the city-scale dataset CityNav demonstrate that FlightGPT achieves state-of-the-art performance across all scenarios, with a 9.22\% higher success rate than the strongest baseline in unseen environments. Our implementation is publicly available.
Following the Autoregressive Nature of LLM Embeddings via Compression and Alignment
Feb 17, 2025A new trend uses LLMs as dense text encoders via contrastive learning. However, since LLM embeddings predict the probability distribution of the next token, they are inherently generative and distributive, conflicting with contrastive learning, which requires embeddings to capture full-text semantics and align via cosine similarity. This discrepancy hinders the full utilization of LLMs' pre-training capabilities, resulting in inefficient learning. In response to this issue, we propose AutoRegEmbed, a new contrastive learning method built on embedding conditional probability distributions, which integrates two core tasks: information compression and conditional distribution alignment. The information compression task encodes text into the embedding space, ensuring that the embedding vectors capture global semantics. The conditional distribution alignment task focuses on aligning text embeddings with positive samples embeddings by leveraging the conditional distribution of embeddings while simultaneously reducing the likelihood of generating negative samples from text embeddings, thereby achieving embedding alignment and uniformity. Experimental results demonstrate that our method significantly outperforms traditional contrastive learning approaches and achieves performance comparable to state-of-the-art models when using the same amount of data.
UnKE: Unstructured Knowledge Editing in Large Language Models
May 24, 2024



Recent knowledge editing methods have primarily focused on modifying structured knowledge in large language models, heavily relying on the assumption that structured knowledge is stored as key-value pairs locally in MLP layers or specific neurons. However, this task setting overlooks the fact that a significant portion of real-world knowledge is stored in an unstructured format, characterized by long-form content, noise, and a complex yet comprehensive nature. The "knowledge locating" and "term-driven optimization" techniques conducted from the assumption used in previous methods (e.g., MEMIT) are ill-suited for unstructured knowledge. To address these challenges, we propose a novel unstructured knowledge editing method, namely UnKE, which extends previous assumptions in the layer dimension and token dimension. Firstly, in the layer dimension, we discard the "knowledge locating" step and treat first few layers as the key, which expand knowledge storage through layers to break the "knowledge stored locally" assumption. Next, we replace "term-driven optimization" with "cause-driven optimization" across all inputted tokens in the token dimension, directly optimizing the last layer of the key generator to perform editing to generate the required key vectors. By utilizing key-value pairs at the layer level, UnKE effectively represents and edits complex and comprehensive unstructured knowledge, leveraging the potential of both the MLP and attention layers. Results on newly proposed unstructure knowledge editing dataset (UnKEBench) and traditional structured datasets demonstrate that UnKE achieves remarkable performance, surpassing strong baselines.
MLaKE: Multilingual Knowledge Editing Benchmark for Large Language Models
Apr 07, 2024



The extensive utilization of large language models (LLMs) underscores the crucial necessity for precise and contemporary knowledge embedded within their intrinsic parameters. Existing research on knowledge editing primarily concentrates on monolingual scenarios, neglecting the complexities presented by multilingual contexts and multi-hop reasoning. To address these challenges, our study introduces MLaKE (Multilingual Language Knowledge Editing), a novel benchmark comprising 4072 multi-hop and 5360 single-hop questions designed to evaluate the adaptability of knowledge editing methods across five languages: English, Chinese, Japanese, French, and German. MLaKE aggregates fact chains from Wikipedia across languages and utilizes LLMs to generate questions in both free-form and multiple-choice. We evaluate the multilingual knowledge editing generalization capabilities of existing methods on MLaKE. Existing knowledge editing methods demonstrate higher success rates in English samples compared to other languages. However, their generalization capabilities are limited in multi-language experiments. Notably, existing knowledge editing methods often show relatively high generalization for languages within the same language family compared to languages from different language families. These results underscore the imperative need for advancements in multilingual knowledge editing and we hope MLaKE can serve as a valuable resource for benchmarking and solution development.
Stable Knowledge Editing in Large Language Models
Feb 20, 2024


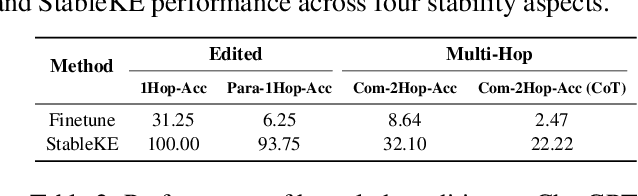
Efficient knowledge editing of large language models is crucial for replacing obsolete information or incorporating specialized knowledge on a large scale. However, previous methods implicitly assume that knowledge is localized and isolated within the model, an assumption that oversimplifies the interconnected nature of model knowledge. The premise of localization results in an incomplete knowledge editing, whereas an isolated assumption may impair both other knowledge and general abilities. It introduces instability to the performance of the knowledge editing method. To transcend these assumptions, we introduce StableKE, a method adopts a novel perspective based on knowledge augmentation rather than knowledge localization. To overcome the expense of human labeling, StableKE integrates two automated knowledge augmentation strategies: Semantic Paraphrase Enhancement strategy, which diversifies knowledge descriptions to facilitate the teaching of new information to the model, and Contextual Description Enrichment strategy, expanding the surrounding knowledge to prevent the forgetting of related information. StableKE surpasses other knowledge editing methods, demonstrating stability both edited knowledge and multi-hop knowledge, while also preserving unrelated knowledge and general abilities. Moreover, StableKE can edit knowledge on ChatGPT.