 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAirNav: A Large-Scale Real-World UAV Vision-and-Language Navigation Dataset with Natural and Diverse Instructions
Jan 07, 2026Existing Unmanned Aerial Vehicle (UAV) Vision-Language Navigation (VLN) datasets face issues such as dependence on virtual environments, lack of naturalness in instructions, and limited scale. To address these challenges, we propose AirNav, a large-scale UAV VLN benchmark constructed from real urban aerial data, rather than synthetic environments, with natural and diverse instructions. Additionally, we introduce the AirVLN-R1, which combines Supervised Fine-Tuning and Reinforcement Fine-Tuning to enhance performance and generalization. The feasibility of the model is preliminarily evaluated through real-world tests. Our dataset and code are publicly available.
Interpretable Reward Model via Sparse Autoencoder
Aug 12, 2025Large language models (LLMs) have been widely deployed across numerous fields. Reinforcement Learning from Human Feedback (RLHF) leverages reward models (RMs) as proxies for human preferences to align LLM behaviors with human values, making the accuracy, reliability, and interpretability of RMs critical for effective alignment. However, traditional RMs lack interpretability, offer limited insight into the reasoning behind reward assignments, and are inflexible toward user preference shifts. While recent multidimensional RMs aim for improved interpretability, they often fail to provide feature-level attribution and require costly annotations. To overcome these limitations, we introduce the Sparse Autoencoder-enhanced Reward Model (\textbf{SARM}), a novel architecture that integrates a pretrained Sparse Autoencoder (SAE) into a reward model. SARM maps the hidden activations of LLM-based RM into an interpretable, sparse, and monosemantic feature space, from which a scalar head aggregates feature activations to produce transparent and conceptually meaningful reward scores. Empirical evaluations demonstrate that SARM facilitates direct feature-level attribution of reward assignments, allows dynamic adjustment to preference shifts, and achieves superior alignment performance compared to conventional reward models. Our code is available at https://github.com/schrieffer-z/sarm.
MM-R5: MultiModal Reasoning-Enhanced ReRanker via Reinforcement Learning for Document Retrieval
Jun 14, 2025Multimodal document retrieval systems enable information access across text, images, and layouts, benefiting various domains like document-based question answering, report analysis, and interactive content summarization. Rerankers improve retrieval precision by reordering retrieved candidates. However, current multimodal reranking methods remain underexplored, with significant room for improvement in both training strategies and overall effectiveness. Moreover, the lack of explicit reasoning makes it difficult to analyze and optimize these methods further. In this paper, We propose MM-R5, a MultiModal Reasoning-Enhanced ReRanker via Reinforcement Learning for Document Retrieval, aiming to provide a more effective and reliable solution for multimodal reranking tasks. MM-R5 is trained in two stages: supervised fine-tuning (SFT) and reinforcement learning (RL). In the SFT stage, we focus on improving instruction-following and guiding the model to generate complete and high-quality reasoning chains. To support this, we introduce a novel data construction strategy that produces rich, high-quality reasoning data. In the RL stage, we design a task-specific reward framework, including a reranking reward tailored for multimodal candidates and a composite template-based reward to further refine reasoning quality. We conduct extensive experiments on MMDocIR, a challenging public benchmark spanning multiple domains. MM-R5 achieves state-of-the-art performance on most metrics and delivers comparable results to much larger models on the remaining ones. Moreover, compared to the best retrieval-only method, MM-R5 improves recall@1 by over 4%. These results validate the effectiveness of our reasoning-enhanced training pipeline.
FlightGPT: Towards Generalizable and Interpretable UAV Vision-and-Language Navigation with Vision-Language Models
May 19, 2025Unmanned Aerial Vehicle (UAV) Vision-and-Language Navigation (VLN) is vital for applications such as disaster response, logistics delivery, and urban inspection. However, existing methods often struggle with insufficient multimodal fusion, weak generalization, and poor interpretability. To address these challenges, we propose FlightGPT, a novel UAV VLN framework built upon Vision-Language Models (VLMs) with powerful multimodal perception capabilities. We design a two-stage training pipeline: first, Supervised Fine-Tuning (SFT) using high-quality demonstrations to improve initialization and structured reasoning; then, Group Relative Policy Optimization (GRPO) algorithm, guided by a composite reward that considers goal accuracy, reasoning quality, and format compliance, to enhance generalization and adaptability. Furthermore, FlightGPT introduces a Chain-of-Thought (CoT)-based reasoning mechanism to improve decision interpretability. Extensive experiments on the city-scale dataset CityNav demonstrate that FlightGPT achieves state-of-the-art performance across all scenarios, with a 9.22\% higher success rate than the strongest baseline in unseen environments. Our implementation is publicly available.
Search and Refine During Think: Autonomous Retrieval-Augmented Reasoning of LLMs
May 16, 2025Large language models have demonstrated impressive reasoning capabilities but are inherently limited by their knowledge reservoir. Retrieval-augmented reasoning mitigates this limitation by allowing LLMs to query external resources, but existing methods often retrieve irrelevant or noisy information, hindering accurate reasoning. In this paper, we propose AutoRefine, a reinforcement learning post-training framework that adopts a new ``search-and-refine-during-think'' paradigm. AutoRefine introduces explicit knowledge refinement steps between successive search calls, enabling the model to iteratively filter, distill, and organize evidence before generating an answer. Furthermore, we incorporate tailored retrieval-specific rewards alongside answer correctness rewards using group relative policy optimization. Experiments on single-hop and multi-hop QA benchmarks demonstrate that AutoRefine significantly outperforms existing approaches, particularly in complex, multi-hop reasoning scenarios. Detailed analysis shows that AutoRefine issues frequent, higher-quality searches and synthesizes evidence effectively.
A Multi-Granularity Retrieval Framework for Visually-Rich Documents
May 06, 2025Retrieval-augmented generation (RAG) systems have predominantly focused on text-based retrieval, limiting their effectiveness in handling visually-rich documents that encompass text, images, tables, and charts. To bridge this gap, we propose a unified multi-granularity multimodal retrieval framework tailored for two benchmark tasks: MMDocIR and M2KR. Our approach integrates hierarchical encoding strategies, modality-aware retrieval mechanisms, and vision-language model (VLM)-based candidate filtering to effectively capture and utilize the complex interdependencies between textual and visual modalities. By leveraging off-the-shelf vision-language models and implementing a training-free hybrid retrieval strategy, our framework demonstrates robust performance without the need for task-specific fine-tuning. Experimental evaluations reveal that incorporating layout-aware search and VLM-based candidate verification significantly enhances retrieval accuracy, achieving a top performance score of 65.56. This work underscores the potential of scalable and reproducible solutions in advancing multimodal document retrieval systems.
A Multi-Granularity Multimodal Retrieval Framework for Multimodal Document Tasks
May 01, 2025Retrieval-augmented generation (RAG) systems have predominantly focused on text-based retrieval, limiting their effectiveness in handling visually-rich documents that encompass text, images, tables, and charts. To bridge this gap, we propose a unified multi-granularity multimodal retrieval framework tailored for two benchmark tasks: MMDocIR and M2KR. Our approach integrates hierarchical encoding strategies, modality-aware retrieval mechanisms, and reranking modules to effectively capture and utilize the complex interdependencies between textual and visual modalities. By leveraging off-the-shelf vision-language models and implementing a training-free hybridretrieval strategy, our framework demonstrates robust performance without the need for task-specific fine-tuning. Experimental evaluations reveal that incorporating layout-aware search and reranking modules significantly enhances retrieval accuracy, achieving a top performance score of 65.56. This work underscores the potential of scalable and reproducible solutions in advancing multimodal document retrieval systems.
Intelligent System for Automated Molecular Patent Infringement Assessment
Dec 10, 2024



Automated drug discovery offers significant potential for accelerating the development of novel therapeutics by substituting labor-intensive human workflows with machine-driven processes. However, a critical bottleneck persists in the inability of current automated frameworks to assess whether newly designed molecules infringe upon existing patents, posing significant legal and financial risks. We introduce PatentFinder, a novel tool-enhanced and multi-agent framework that accurately and comprehensively evaluates small molecules for patent infringement. It incorporates both heuristic and model-based tools tailored for decomposed subtasks, featuring: MarkushParser, which is capable of optical chemical structure recognition of molecular and Markush structures, and MarkushMatcher, which enhances large language models' ability to extract substituent groups from molecules accurately. On our benchmark dataset MolPatent-240, PatentFinder outperforms baseline approaches that rely solely on large language models, demonstrating a 13.8\% increase in F1-score and a 12\% rise in accuracy. Experimental results demonstrate that PatentFinder mitigates label bias to produce balanced predictions and autonomously generates detailed, interpretable patent infringement reports. This work not only addresses a pivotal challenge in automated drug discovery but also demonstrates the potential of decomposing complex scientific tasks into manageable subtasks for specialized, tool-augmented agents.
SciLitLLM: How to Adapt LLMs for Scientific Literature Understanding
Aug 30, 2024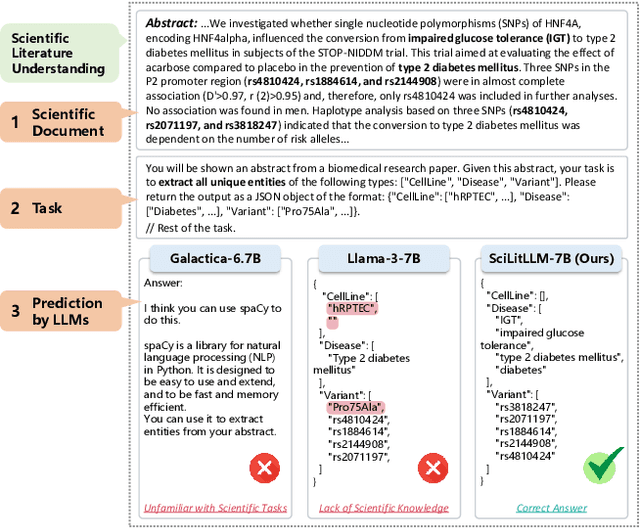
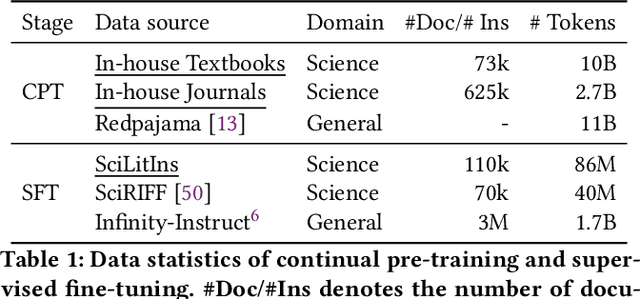
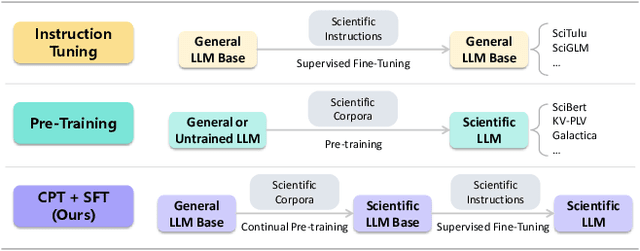
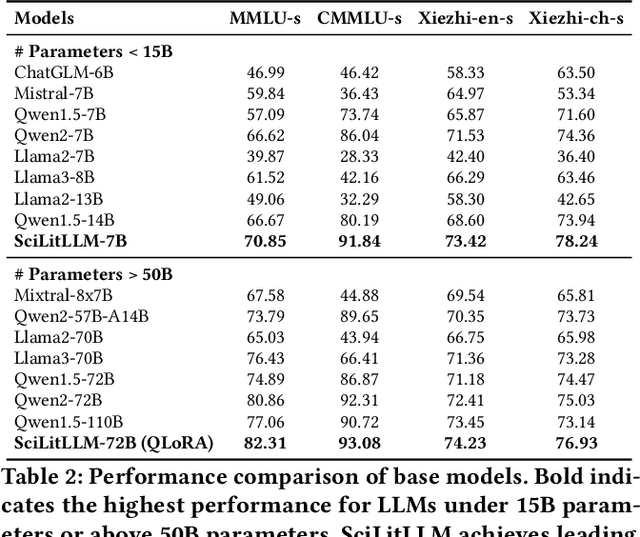
Scientific literature understanding is crucial for extracting targeted information and garnering insights, thereby significantly advancing scientific discovery. Despite the remarkable success of Large Language Models (LLMs), they face challenges in scientific literature understanding, primarily due to (1) a lack of scientific knowledge and (2) unfamiliarity with specialized scientific tasks. To develop an LLM specialized in scientific literature understanding, we propose a hybrid strategy that integrates continual pre-training (CPT) and supervised fine-tuning (SFT), to simultaneously infuse scientific domain knowledge and enhance instruction-following capabilities for domain-specific tasks.cIn this process, we identify two key challenges: (1) constructing high-quality CPT corpora, and (2) generating diverse SFT instructions. We address these challenges through a meticulous pipeline, including PDF text extraction, parsing content error correction, quality filtering, and synthetic instruction creation. Applying this strategy, we present a suite of LLMs: SciLitLLM, specialized in scientific literature understanding. These models demonstrate promising performance on scientific literature understanding benchmarks. Our contributions are threefold: (1) We present an effective framework that integrates CPT and SFT to adapt LLMs to scientific literature understanding, which can also be easily adapted to other domains. (2) We propose an LLM-based synthesis method to generate diverse and high-quality scientific instructions, resulting in a new instruction set -- SciLitIns -- for supervised fine-tuning in less-represented scientific domains. (3) SciLitLLM achieves promising performance improvements on scientific literature understanding benchmarks.
Uni-SMART: Universal Science Multimodal Analysis and Research Transformer
Mar 15, 2024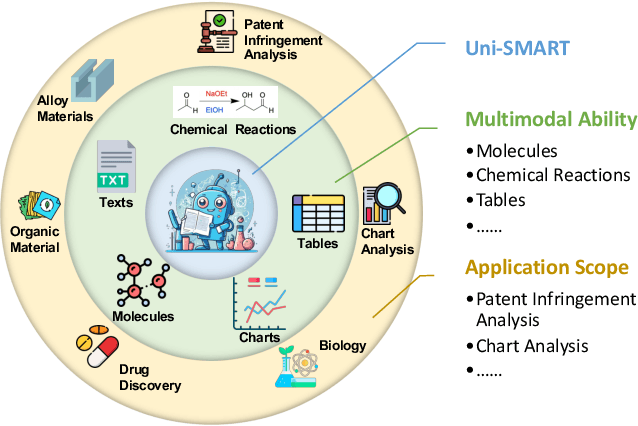
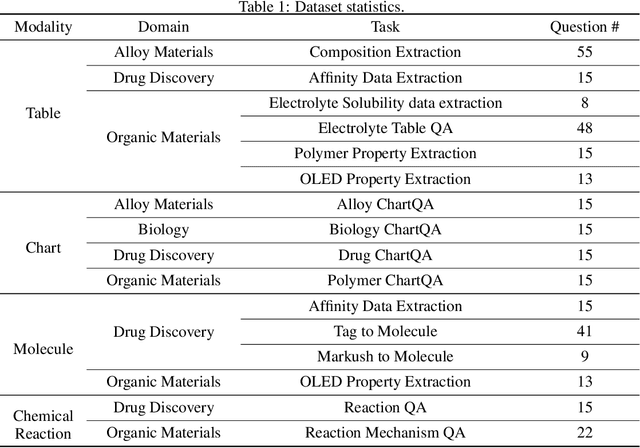
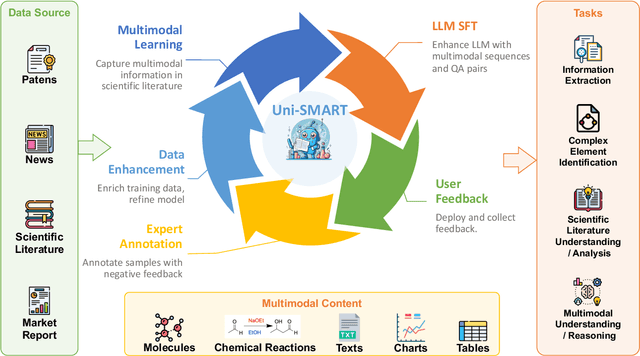
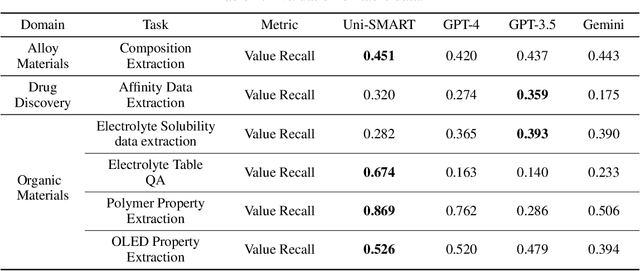
In scientific research and its application, scientific literature analysis is crucial as it allows researchers to build on the work of others. However, the fast growth of scientific knowledge has led to a massive increase in scholarly articles, making in-depth literature analysis increasingly challenging and time-consuming. The emergence of Large Language Models (LLMs) has offered a new way to address this challenge. Known for their strong abilities in summarizing texts, LLMs are seen as a potential tool to improve the analysis of scientific literature. However, existing LLMs have their own limits. Scientific literature often includes a wide range of multimodal elements, such as molecular structure, tables, and charts, which are hard for text-focused LLMs to understand and analyze. This issue points to the urgent need for new solutions that can fully understand and analyze multimodal content in scientific literature. To answer this demand, we present Uni-SMART (Universal Science Multimodal Analysis and Research Transformer), an innovative model designed for in-depth understanding of multimodal scientific literature. Through rigorous quantitative evaluation across several domains, Uni-SMART demonstrates superior performance over leading text-focused LLMs. Furthermore, our exploration extends to practical applications, including patent infringement detection and nuanced analysis of charts. These applications not only highlight Uni-SMART's adaptability but also its potential to revolutionize how we interact with scientific literature.