 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2021 Depth Guided Image Relighting Challenge
Apr 27, 2021



Image relighting is attracting increasing interest due to its various applications. From a research perspective, image relighting can be exploited to conduct both image normalization for domain adaptation, and also for data augmentation. It also has multiple direct uses for photo montage and aesthetic enhancement. In this paper, we review the NTIRE 2021 depth guided image relighting challenge. We rely on the VIDIT dataset for each of our two challenge tracks, including depth information. The first track is on one-to-one relighting where the goal is to transform the illumination setup of an input image (color temperature and light source position) to the target illumination setup. In the second track, the any-to-any relighting challenge, the objective is to transform the illumination settings of the input image to match those of another guide image, similar to style transfer. In both tracks, participants were given depth information about the captured scenes. We had nearly 250 registered participants, leading to 18 confirmed team submissions in the final competition stage. The competitions, methods, and final results are presented in this paper.
* Code and data available on https://github.com/majedelhelou/VIDIT
AIM 2020: Scene Relighting and Illumination Estimation Challenge
Sep 27, 2020

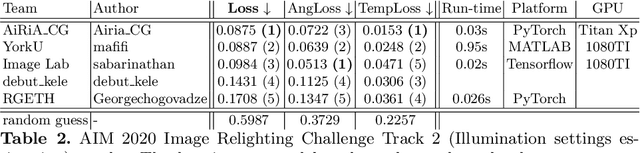

We review the AIM 2020 challenge on virtual image relighting and illumination estimation. This paper presents the novel VIDIT dataset used in the challenge and the different proposed solutions and final evaluation results over the 3 challenge tracks. The first track considered one-to-one relighting; the objective was to relight an input photo of a scene with a different color temperature and illuminant orientation (i.e., light source position). The goal of the second track was to estimate illumination settings, namely the color temperature and orientation, from a given image. Lastly, the third track dealt with any-to-any relighting, thus a generalization of the first track. The target color temperature and orientation, rather than being pre-determined, are instead given by a guide image. Participants were allowed to make use of their track 1 and 2 solutions for track 3. The tracks had 94, 52, and 56 registered participants, respectively, leading to 20 confirmed submissions in the final competition stage.
VIDIT: Virtual Image Dataset for Illumination Transfer
May 13, 2020
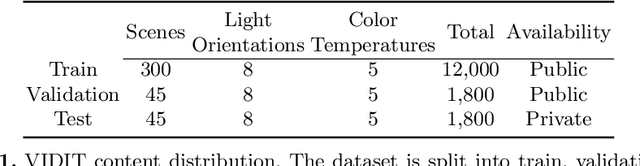


Deep image relighting is gaining more interest lately, as it allows photo enhancement through illumination-specific retouching without human effort. Aside from aesthetic enhancement and photo montage, image relighting is valuable for domain adaptation, whether to augment datasets for training or to normalize input test data. Accurate relighting is, however, very challenging for various reasons, such as the difficulty in removing and recasting shadows and the modeling of different surfaces. We present a novel dataset, the Virtual Image Dataset for Illumination Transfer (VIDIT), in an effort to create a reference evaluation benchmark and to push forward the development of illumination manipulation methods. Virtual datasets are not only an important step towards achieving real-image performance but have also proven capable of improving training even when real datasets are possible to acquire and available. VIDIT contains 300 virtual scenes used for training, where every scene is captured 40 times in total: from 8 equally-spaced azimuthal angles, each lit with 5 different illuminants.
Divergence-Based Adaptive Extreme Video Completion
Apr 14, 2020



Extreme image or video completion, where, for instance, we only retain 1% of pixels in random locations, allows for very cheap sampling in terms of the required pre-processing. The consequence is, however, a reconstruction that is challenging for humans and inpainting algorithms alike. We propose an extension of a state-of-the-art extreme image completion algorithm to extreme video completion. We analyze a color-motion estimation approach based on color KL-divergence that is suitable for extremely sparse scenarios. Our algorithm leverages the estimate to adapt between its spatial and temporal filtering when reconstructing the sparse randomly-sampled video. We validate our results on 50 publicly-available videos using reconstruction PSNR and mean opinion scores.
Stochastic Frequency Masking to Improve Super-Resolution and Denoising Networks
Mar 16, 2020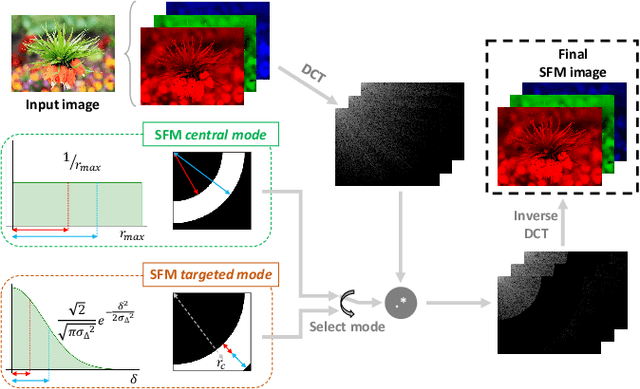

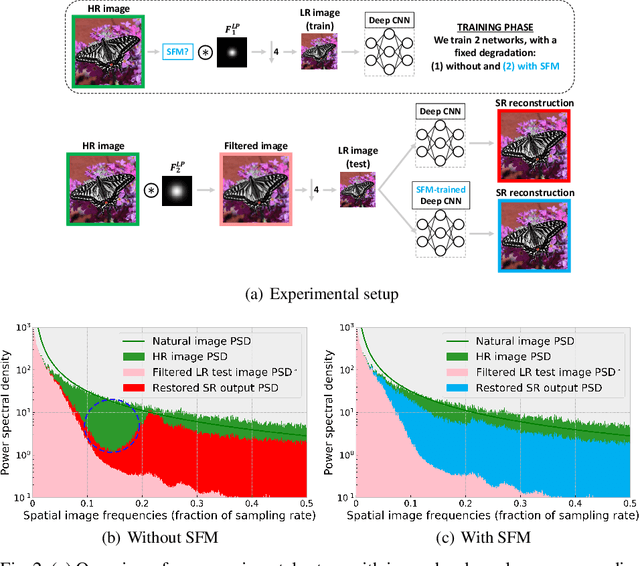
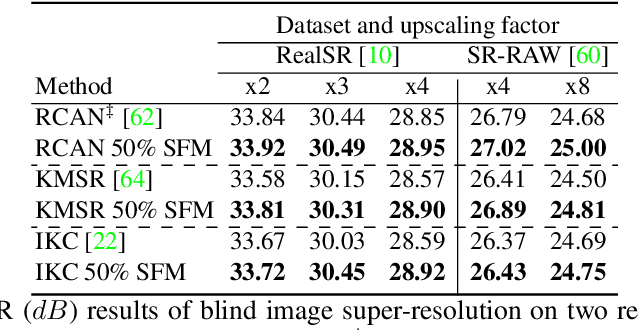
Super-resolution and denoising are ill-posed yet fundamental image restoration tasks. In blind settings, the degradation kernel or the noise level are unknown. This makes restoration even more challenging, notably for learning-based methods, as they tend to overfit to the degradation seen during training. We present an analysis, in the frequency domain, of degradation-kernel overfitting in super-resolution and introduce a conditional learning perspective that extends to both super-resolution and denoising. Building on our formulation, we propose a stochastic frequency masking of images used in training to regularize the networks and address the overfitting problem. Our technique improves state-of-the-art methods on blind super-resolution with different synthetic kernels, real super-resolution, blind Gaussian denoising, and real-image denoising.
W2S: A Joint Denoising and Super-Resolution Dataset
Mar 12, 2020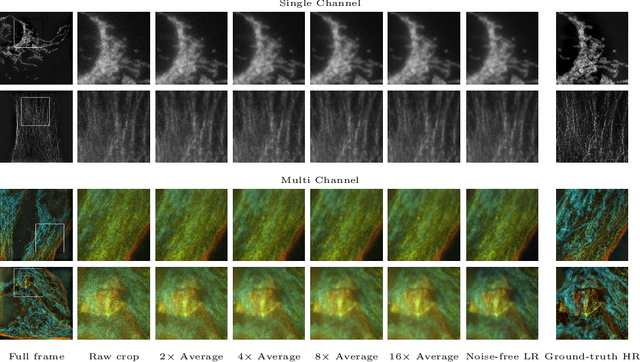
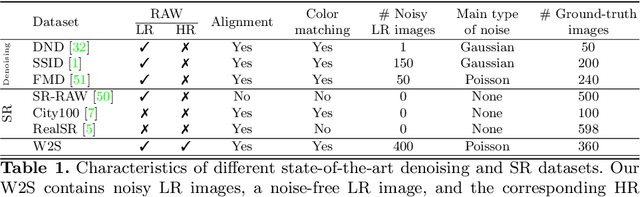

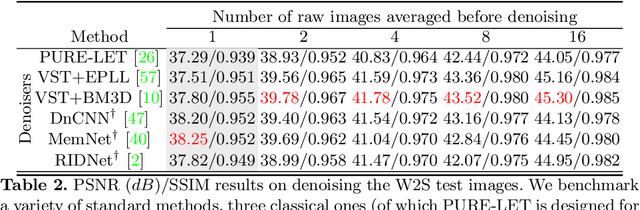
Denoising and super-resolution (SR) are fundamental tasks in imaging. These two restoration tasks are well covered in the literature, however, only separately. Given a noisy low-resolution (LR) input image, it is yet unclear what the best approach would be in order to obtain a noise-free high-resolution (HR) image. In order to study joint denoising and super-resolution (JDSR), a dataset containing pairs of noisy LR images and the corresponding HR images is fundamental. We propose such a novel JDSR dataset, Wieldfield2SIM (W2S), acquired using microscopy equipment and techniques. W2S is comprised of 144,000 real fluorescence microscopy images, used to form a total of 360 sets of images. A set is comprised of noisy LR images with different noise levels, a noise-free LR image, and a corresponding high-quality HR image. W2S allows us to benchmark the combinations of 6 denoising methods and 6 SR methods. We show that state-of-the-art SR networks perform very poorly on noisy inputs, with a loss reaching 14dB relative to noise-free inputs. Our evaluation also shows that applying the best denoiser in terms of reconstruction error followed by the best SR method does not yield the best result. The best denoising PSNR can, for instance, come at the expense of a loss in high frequencies, which is detrimental for SR methods. We lastly demonstrate that a light-weight SR network with a novel texture loss, trained specifically for JDSR, outperforms any combination of state-of-the-art deep denoising and SR networks.
Drone Shadow Tracking
May 20, 2019
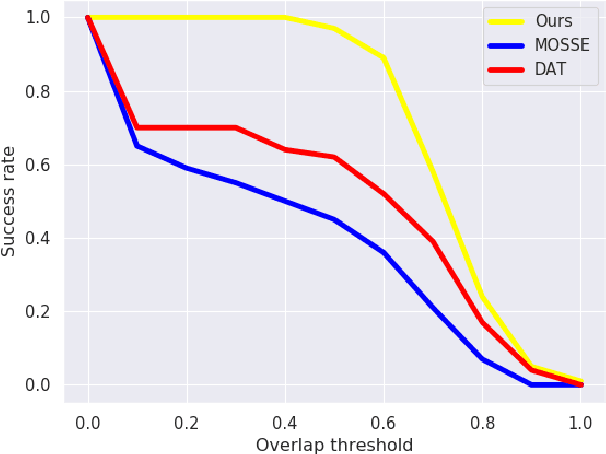
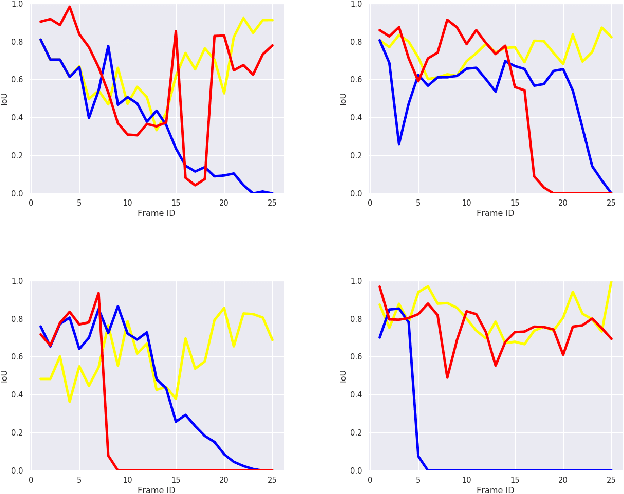

Aerial videos taken by a drone not too far above the surface may contain the drone's shadow projected on the scene. This deteriorates the aesthetic quality of videos. With the presence of other shadows, shadow removal cannot be directly applied, and the shadow of the drone must be tracked. Tracking a drone's shadow in a video is, however, challenging. The varying size, shape, change of orientation and drone altitude pose difficulties. The shadow can also easily disappear over dark areas. However, a shadow has specific properties that can be leveraged, besides its geometric shape. In this paper, we incorporate knowledge of the shadow's physical properties, in the form of shadow detection masks, into a correlation-based tracking algorithm. We capture a test set of aerial videos taken with different settings and compare our results to those of a state-of-the-art tracking algorithm.
Deep Residual Network for Joint Demosaicing and Super-Resolution
Feb 19, 2018
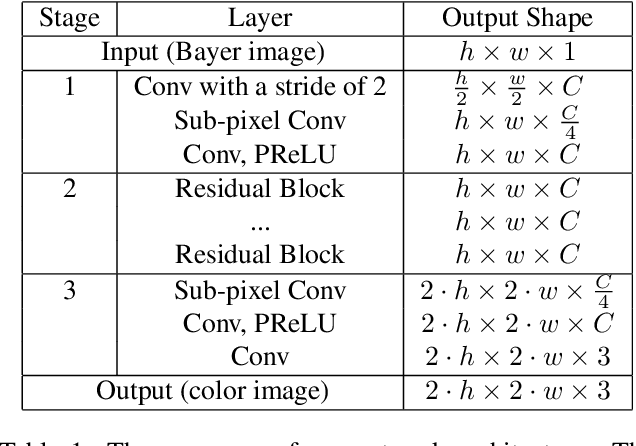


In digital photography, two image restoration tasks have been studied extensively and resolved independently: demosaicing and super-resolution. Both these tasks are related to resolution limitations of the camera. Performing super-resolution on a demosaiced images simply exacerbates the artifacts introduced by demosaicing. In this paper, we show that such accumulation of errors can be easily averted by jointly performing demosaicing and super-resolution. To this end, we propose a deep residual network for learning an end-to-end mapping between Bayer images and high-resolution images. By training on high-quality samples, our deep residual demosaicing and super-resolution network is able to recover high-quality super-resolved images from low-resolution Bayer mosaics in a single step without producing the artifacts common to such processing when the two operations are done separately. We perform extensive experiments to show that our deep residual network achieves demosaiced and super-resolved images that are superior to the state-of-the-art both qualitatively and in terms of PSNR and SSIM metrics.