 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI for Mycetoma Diagnosis in Histopathological Images: The MICCAI 2024 Challenge
Dec 25, 2025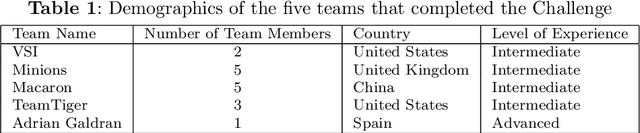
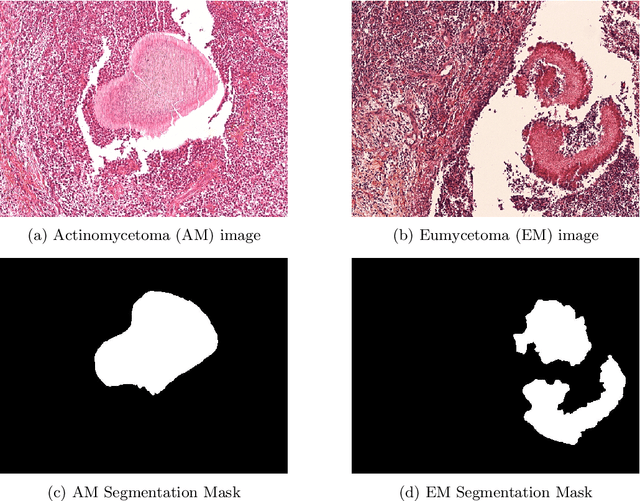
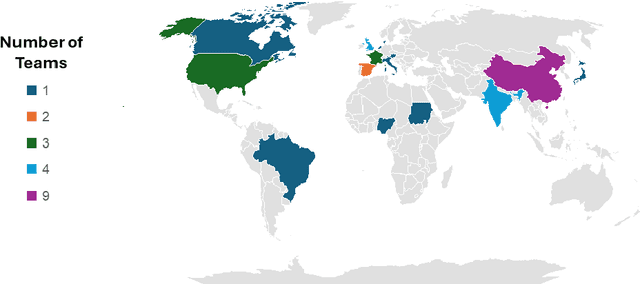

Mycetoma is a neglected tropical disease caused by fungi or bacteria leading to severe tissue damage and disabilities. It affects poor and rural communities and presents medical challenges and socioeconomic burdens on patients and healthcare systems in endemic regions worldwide. Mycetoma diagnosis is a major challenge in mycetoma management, particularly in low-resource settings where expert pathologists are limited. To address this challenge, this paper presents an overview of the Mycetoma MicroImage: Detect and Classify Challenge (mAIcetoma) which was organized to advance mycetoma diagnosis through AI solutions. mAIcetoma focused on developing automated models for segmenting mycetoma grains and classifying mycetoma types from histopathological images. The challenge attracted the attention of several teams worldwide to participate and five finalist teams fulfilled the challenge objectives. The teams proposed various deep learning architectures for the ultimate goal of this challenge. Mycetoma database (MyData) was provided to participants as a standardized dataset to run the proposed models. Those models were evaluated using evaluation metrics. Results showed that all the models achieved high segmentation accuracy, emphasizing the necessitate of grain detection as a critical step in mycetoma diagnosis. In addition, the top-performing models show a significant performance in classifying mycetoma types.
NTIRE 2025 Image Shadow Removal Challenge Report
Jun 18, 2025



This work examines the findings of the NTIRE 2025 Shadow Removal Challenge. A total of 306 participants have registered, with 17 teams successfully submitting their solutions during the final evaluation phase. Following the last two editions, this challenge had two evaluation tracks: one focusing on reconstruction fidelity and the other on visual perception through a user study. Both tracks were evaluated with images from the WSRD+ dataset, simulating interactions between self- and cast-shadows with a large number of diverse objects, textures, and materials.
NTIRE 2025 Challenge on HR Depth from Images of Specular and Transparent Surfaces
Jun 06, 2025This paper reports on the NTIRE 2025 challenge on HR Depth From images of Specular and Transparent surfaces, held in conjunction with the New Trends in Image Restoration and Enhancement (NTIRE) workshop at CVPR 2025. This challenge aims to advance the research on depth estimation, specifically to address two of the main open issues in the field: high-resolution and non-Lambertian surfaces. The challenge proposes two tracks on stereo and single-image depth estimation, attracting about 177 registered participants. In the final testing stage, 4 and 4 participating teams submitted their models and fact sheets for the two tracks.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
NTIRE 2025 Challenge on Image Super-Resolution ($\times$4): Methods and Results
Apr 20, 2025This paper presents the NTIRE 2025 image super-resolution ($\times$4) challenge, one of the associated competitions of the 10th NTIRE Workshop at CVPR 2025. The challenge aims to recover high-resolution (HR) images from low-resolution (LR) counterparts generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective network designs or solutions that achieve state-of-the-art SR performance. To reflect the dual objectives of image SR research, the challenge includes two sub-tracks: (1) a restoration track, emphasizes pixel-wise accuracy and ranks submissions based on PSNR; (2) a perceptual track, focuses on visual realism and ranks results by a perceptual score. A total of 286 participants registered for the competition, with 25 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, the main results, and methods of each team. The challenge serves as a benchmark to advance the state of the art and foster progress in image SR.
NTIRE 2025 Challenge on Event-Based Image Deblurring: Methods and Results
Apr 16, 2025This paper presents an overview of NTIRE 2025 the First Challenge on Event-Based Image Deblurring, detailing the proposed methodologies and corresponding results. The primary goal of the challenge is to design an event-based method that achieves high-quality image deblurring, with performance quantitatively assessed using Peak Signal-to-Noise Ratio (PSNR). Notably, there are no restrictions on computational complexity or model size. The task focuses on leveraging both events and images as inputs for single-image deblurring. A total of 199 participants registered, among whom 15 teams successfully submitted valid results, offering valuable insights into the current state of event-based image deblurring. We anticipate that this challenge will drive further advancements in event-based vision research.
Audio-Language Models for Audio-Centric Tasks: A survey
Jan 25, 2025



Audio-Language Models (ALMs), which are trained on audio-text data, focus on the processing, understanding, and reasoning of sounds. Unlike traditional supervised learning approaches learning from predefined labels, ALMs utilize natural language as a supervision signal, which is more suitable for describing complex real-world audio recordings. ALMs demonstrate strong zero-shot capabilities and can be flexibly adapted to diverse downstream tasks. These strengths not only enhance the accuracy and generalization of audio processing tasks but also promote the development of models that more closely resemble human auditory perception and comprehension. Recent advances in ALMs have positioned them at the forefront of computer audition research, inspiring a surge of efforts to advance ALM technologies. Despite rapid progress in the field of ALMs, there is still a notable lack of systematic surveys that comprehensively organize and analyze developments. In this paper, we present a comprehensive review of ALMs with a focus on general audio tasks, aiming to fill this gap by providing a structured and holistic overview of ALMs. Specifically, we cover: (1) the background of computer audition and audio-language models; (2) the foundational aspects of ALMs, including prevalent network architectures, training objectives, and evaluation methods; (3) foundational pre-training and audio-language pre-training approaches; (4) task-specific fine-tuning, multi-task tuning and agent systems for downstream applications; (5) datasets and benchmarks; and (6) current challenges and future directions. Our review provides a clear technical roadmap for researchers to understand the development and future trends of existing technologies, offering valuable references for implementation in real-world scenarios.
AudioCIL: A Python Toolbox for Audio Class-Incremental Learning with Multiple Scenes
Dec 16, 2024Deep learning, with its robust aotomatic feature extraction capabilities, has demonstrated significant success in audio signal processing. Typically, these methods rely on static, pre-collected large-scale datasets for training, performing well on a fixed number of classes. However, the real world is characterized by constant change, with new audio classes emerging from streaming or temporary availability due to privacy. This dynamic nature of audio environments necessitates models that can incrementally learn new knowledge for new classes without discarding existing information. Introducing incremental learning to the field of audio signal processing, i.e., Audio Class-Incremental Learning (AuCIL), is a meaningful endeavor. We propose such a toolbox named AudioCIL to align audio signal processing algorithms with real-world scenarios and strengthen research in audio class-incremental learning.
Relieving Universal Label Noise for Unsupervised Visible-Infrared Person Re-Identification by Inferring from Neighbors
Dec 16, 2024Unsupervised visible-infrared person re-identification (USL-VI-ReID) is of great research and practical significance yet remains challenging due to the absence of annotations. Existing approaches aim to learn modality-invariant representations in an unsupervised setting. However, these methods often encounter label noise within and across modalities due to suboptimal clustering results and considerable modality discrepancies, which impedes effective training. To address these challenges, we propose a straightforward yet effective solution for USL-VI-ReID by mitigating universal label noise using neighbor information. Specifically, we introduce the Neighbor-guided Universal Label Calibration (N-ULC) module, which replaces explicit hard pseudo labels in both homogeneous and heterogeneous spaces with soft labels derived from neighboring samples to reduce label noise. Additionally, we present the Neighbor-guided Dynamic Weighting (N-DW) module to enhance training stability by minimizing the influence of unreliable samples. Extensive experiments on the RegDB and SYSU-MM01 datasets demonstrate that our method outperforms existing USL-VI-ReID approaches, despite its simplicity. The source code is available at: https://github.com/tengxiao14/Neighbor-guided-USL-VI-ReID.
Exploring structure diversity in atomic resolution microscopy with graph neural networks
Oct 23, 2024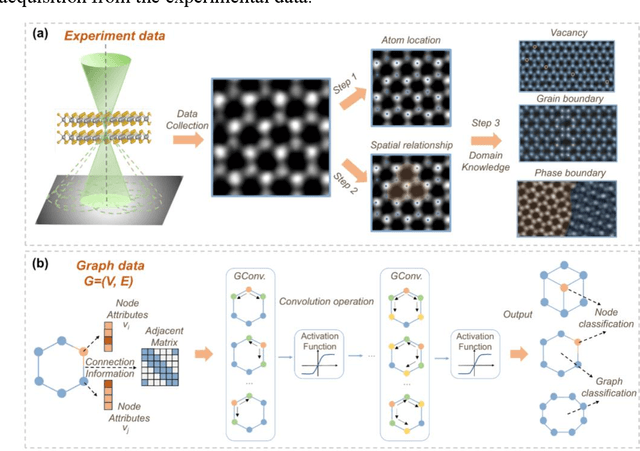
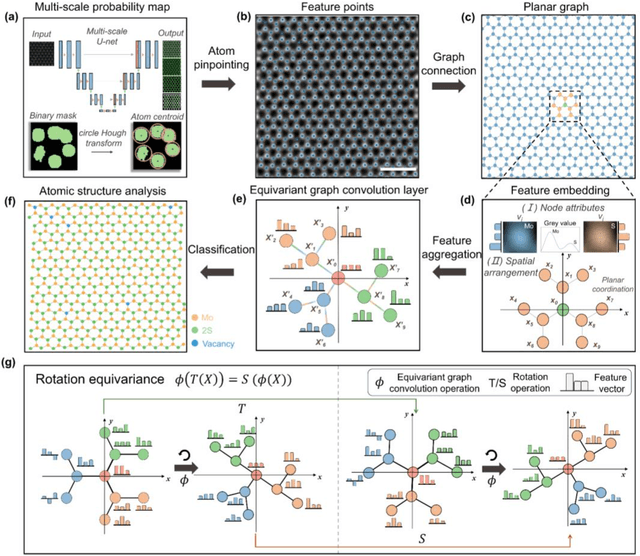
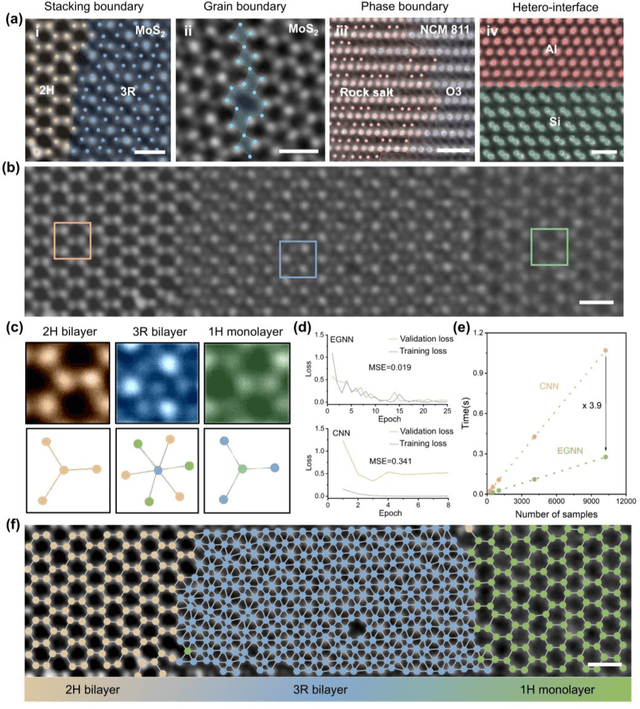
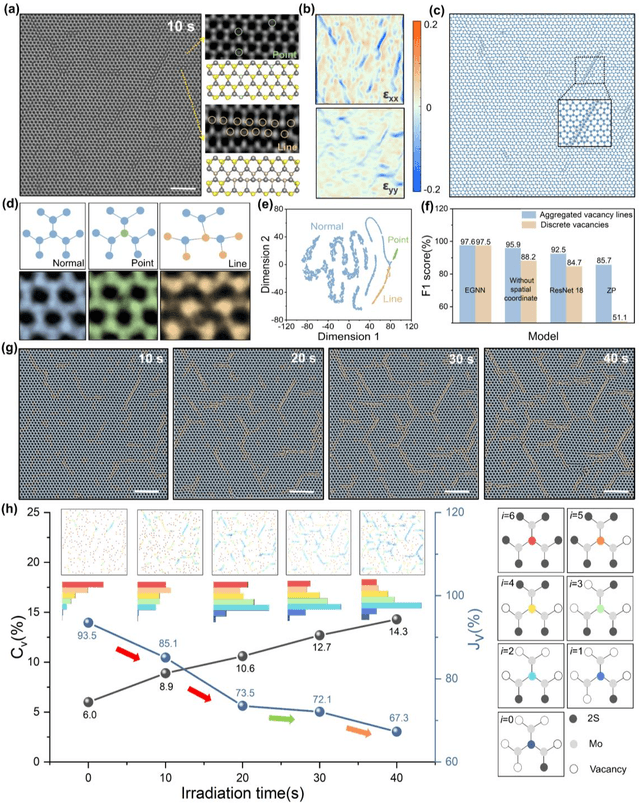
The emergence of deep learning (DL) has provided great opportunities for the high-throughput analysis of atomic-resolution micrographs. However, the DL models trained by image patches in fixed size generally lack efficiency and flexibility when processing micrographs containing diversified atomic configurations. Herein, inspired by the similarity between the atomic structures and graphs, we describe a few-shot learning framework based on an equivariant graph neural network (EGNN) to analyze a library of atomic structures (e.g., vacancies, phases, grain boundaries, doping, etc.), showing significantly promoted robustness and three orders of magnitude reduced computing parameters compared to the image-driven DL models, which is especially evident for those aggregated vacancy lines with flexible lattice distortion. Besides, the intuitiveness of graphs enables quantitative and straightforward extraction of the atomic-scale structural features in batches, thus statistically unveiling the self-assembly dynamics of vacancy lines under electron beam irradiation. A versatile model toolkit is established by integrating EGNN sub-models for single structure recognition to process images involving varied configurations in the form of a task chain, leading to the discovery of novel doping configurations with superior electrocatalytic properties for hydrogen evolution reactions. This work provides a powerful tool to explore structure diversity in a fast, accurate, and intelligent manner.