 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGym-V: A Unified Vision Environment System for Agentic Vision Research
Mar 17, 2026As agentic systems increasingly rely on reinforcement learning from verifiable rewards, standardized ``gym'' infrastructure has become essential for rapid iteration, reproducibility, and fair comparison. Vision agents lack such infrastructure, limiting systematic study of what drives their learning and where current models fall short. We introduce \textbf{Gym-V}, a unified platform of 179 procedurally generated visual environments across 10 domains with controllable difficulty, enabling controlled experiments that were previously infeasible across fragmented toolkits. Using it, we find that observation scaffolding is more decisive for training success than the choice of RL algorithm, with captions and game rules determining whether learning succeeds at all. Cross-domain transfer experiments further show that training on diverse task categories generalizes broadly while narrow training can cause negative transfer, with multi-turn interaction amplifying all of these effects. Gym-V is released as a convenient foundation for training environments and evaluation toolkits, aiming to accelerate future research on agentic VLMs.
SRUM: Fine-Grained Self-Rewarding for Unified Multimodal Models
Oct 14, 2025Recently, remarkable progress has been made in Unified Multimodal Models (UMMs), which integrate vision-language generation and understanding capabilities within a single framework. However, a significant gap exists where a model's strong visual understanding often fails to transfer to its visual generation. A model might correctly understand an image based on user instructions, yet be unable to generate a faithful image from text prompts. This phenomenon directly raises a compelling question: Can a model achieve self-improvement by using its understanding module to reward its generation module? To bridge this gap and achieve self-improvement, we introduce SRUM, a self-rewarding post-training framework that can be directly applied to existing UMMs of various designs. SRUM creates a feedback loop where the model's own understanding module acts as an internal ``evaluator'', providing corrective signals to improve its generation module, without requiring additional human-labeled data. To ensure this feedback is comprehensive, we designed a global-local dual reward system. To tackle the inherent structural complexity of images, this system offers multi-scale guidance: a \textbf{global reward} ensures the correctness of the overall visual semantics and layout, while a \textbf{local reward} refines fine-grained, object-level fidelity. SRUM leads to powerful capabilities and shows strong generalization, boosting performance on T2I-CompBench from 82.18 to \textbf{88.37} and on T2I-ReasonBench from 43.82 to \textbf{46.75}. Overall, our work establishes a powerful new paradigm for enabling a UMMs' understanding module to guide and enhance its own generation via self-rewarding.
ViStoryBench: Comprehensive Benchmark Suite for Story Visualization
May 30, 2025Story visualization, which aims to generate a sequence of visually coherent images aligning with a given narrative and reference images, has seen significant progress with recent advancements in generative models. To further enhance the performance of story visualization frameworks in real-world scenarios, we introduce a comprehensive evaluation benchmark, ViStoryBench. We collect a diverse dataset encompassing various story types and artistic styles, ensuring models are evaluated across multiple dimensions such as different plots (e.g., comedy, horror) and visual aesthetics (e.g., anime, 3D renderings). ViStoryBench is carefully curated to balance narrative structures and visual elements, featuring stories with single and multiple protagonists to test models' ability to maintain character consistency. Additionally, it includes complex plots and intricate world-building to challenge models in generating accurate visuals. To ensure comprehensive comparisons, our benchmark incorporates a wide range of evaluation metrics assessing critical aspects. This structured and multifaceted framework enables researchers to thoroughly identify both the strengths and weaknesses of different models, fostering targeted improvements.
VideoREPA: Learning Physics for Video Generation through Relational Alignment with Foundation Models
May 29, 2025Recent advancements in text-to-video (T2V) diffusion models have enabled high-fidelity and realistic video synthesis. However, current T2V models often struggle to generate physically plausible content due to their limited inherent ability to accurately understand physics. We found that while the representations within T2V models possess some capacity for physics understanding, they lag significantly behind those from recent video self-supervised learning methods. To this end, we propose a novel framework called VideoREPA, which distills physics understanding capability from video understanding foundation models into T2V models by aligning token-level relations. This closes the physics understanding gap and enable more physics-plausible generation. Specifically, we introduce the Token Relation Distillation (TRD) loss, leveraging spatio-temporal alignment to provide soft guidance suitable for finetuning powerful pre-trained T2V models, a critical departure from prior representation alignment (REPA) methods. To our knowledge, VideoREPA is the first REPA method designed for finetuning T2V models and specifically for injecting physical knowledge. Empirical evaluations show that VideoREPA substantially enhances the physics commonsense of baseline method, CogVideoX, achieving significant improvement on relevant benchmarks and demonstrating a strong capacity for generating videos consistent with intuitive physics. More video results are available at https://videorepa.github.io/.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
LangBridge: Interpreting Image as a Combination of Language Embeddings
Mar 26, 2025



Recent years have witnessed remarkable advances in Large Vision-Language Models (LVLMs), which have achieved human-level performance across various complex vision-language tasks. Following LLaVA's paradigm, mainstream LVLMs typically employ a shallow MLP for visual-language alignment through a two-stage training process: pretraining for cross-modal alignment followed by instruction tuning. While this approach has proven effective, the underlying mechanisms of how MLPs bridge the modality gap remain poorly understood. Although some research has explored how LLMs process transformed visual tokens, few studies have investigated the fundamental alignment mechanism. Furthermore, the MLP adapter requires retraining whenever switching LLM backbones. To address these limitations, we first investigate the working principles of MLP adapters and discover that they learn to project visual embeddings into subspaces spanned by corresponding text embeddings progressively. Based on this insight, we propose LangBridge, a novel adapter that explicitly maps visual tokens to linear combinations of LLM vocabulary embeddings. This innovative design enables pretraining-free adapter transfer across different LLMs while maintaining performance. Our experimental results demonstrate that a LangBridge adapter pre-trained on Qwen2-0.5B can be directly applied to larger models such as LLaMA3-8B or Qwen2.5-14B while maintaining competitive performance. Overall, LangBridge enables interpretable vision-language alignment by grounding visual representations in LLM vocab embedding, while its plug-and-play design ensures efficient reuse across multiple LLMs with nearly no performance degradation. See our project page at https://jiaqiliao77.github.io/LangBridge.github.io/
ImageGen-CoT: Enhancing Text-to-Image In-context Learning with Chain-of-Thought Reasoning
Mar 25, 2025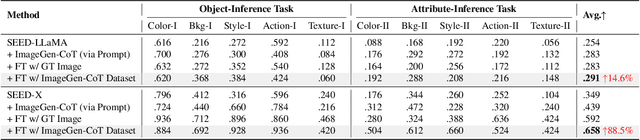



In this work, we study the problem of Text-to-Image In-Context Learning (T2I-ICL). While Unified Multimodal LLMs (MLLMs) have advanced rapidly in recent years, they struggle with contextual reasoning in T2I-ICL scenarios. To address this limitation, we propose a novel framework that incorporates a thought process called ImageGen-CoT prior to image generation. To avoid generating unstructured ineffective reasoning steps, we develop an automatic pipeline to curate a high-quality ImageGen-CoT dataset. We then fine-tune MLLMs using this dataset to enhance their contextual reasoning capabilities. To further enhance performance, we explore test-time scale-up strategies and propose a novel hybrid scaling approach. This approach first generates multiple ImageGen-CoT chains and then produces multiple images for each chain via sampling. Extensive experiments demonstrate the effectiveness of our proposed method. Notably, fine-tuning with the ImageGen-CoT dataset leads to a substantial 80\% performance gain for SEED-X on T2I-ICL tasks. See our project page at https://ImageGen-CoT.github.io/. Code and model weights will be open-sourced.
WISE: A World Knowledge-Informed Semantic Evaluation for Text-to-Image Generation
Mar 10, 2025Text-to-Image (T2I) models are capable of generating high-quality artistic creations and visual content. However, existing research and evaluation standards predominantly focus on image realism and shallow text-image alignment, lacking a comprehensive assessment of complex semantic understanding and world knowledge integration in text to image generation. To address this challenge, we propose $\textbf{WISE}$, the first benchmark specifically designed for $\textbf{W}$orld Knowledge-$\textbf{I}$nformed $\textbf{S}$emantic $\textbf{E}$valuation. WISE moves beyond simple word-pixel mapping by challenging models with 1000 meticulously crafted prompts across 25 sub-domains in cultural common sense, spatio-temporal reasoning, and natural science. To overcome the limitations of traditional CLIP metric, we introduce $\textbf{WiScore}$, a novel quantitative metric for assessing knowledge-image alignment. Through comprehensive testing of 20 models (10 dedicated T2I models and 10 unified multimodal models) using 1,000 structured prompts spanning 25 subdomains, our findings reveal significant limitations in their ability to effectively integrate and apply world knowledge during image generation, highlighting critical pathways for enhancing knowledge incorporation and application in next-generation T2I models. Code and data are available at https://github.com/PKU-YuanGroup/WISE.
AutoFeedback: An LLM-based Framework for Efficient and Accurate API Request Generation
Oct 09, 2024



Large Language Models (LLMs) leverage external tools primarily through generating the API request to enhance task completion efficiency. The accuracy of API request generation significantly determines the capability of LLMs to accomplish tasks. Due to the inherent hallucinations within the LLM, it is difficult to efficiently and accurately generate the correct API request. Current research uses prompt-based feedback to facilitate the LLM-based API request generation. However, existing methods lack factual information and are insufficiently detailed. To address these issues, we propose AutoFeedback, an LLM-based framework for efficient and accurate API request generation, with a Static Scanning Component (SSC) and a Dynamic Analysis Component (DAC). SSC incorporates errors detected in the API requests as pseudo-facts into the feedback, enriching the factual information. DAC retrieves information from API documentation, enhancing the level of detail in feedback. Based on this two components, Autofeedback implementes two feedback loops during the process of generating API requests by the LLM. Extensive experiments demonstrate that it significantly improves accuracy of API request generation and reduces the interaction cost. AutoFeedback achieves an accuracy of 100.00\% on a real-world API dataset and reduces the cost of interaction with GPT-3.5 Turbo by 23.44\%, and GPT-4 Turbo by 11.85\%.
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Oct 07, 2024Text-to-video (T2V) models like Sora have made significant strides in visualizing complex prompts, which is increasingly viewed as a promising path towards constructing the universal world simulator. Cognitive psychologists believe that the foundation for achieving this goal is the ability to understand intuitive physics. However, the capacity of these models to accurately represent intuitive physics remains largely unexplored. To bridge this gap, we introduce PhyGenBench, a comprehensive \textbf{Phy}sics \textbf{Gen}eration \textbf{Ben}chmark designed to evaluate physical commonsense correctness in T2V generation. PhyGenBench comprises 160 carefully crafted prompts across 27 distinct physical laws, spanning four fundamental domains, which could comprehensively assesses models' understanding of physical commonsense. Alongside PhyGenBench, we propose a novel evaluation framework called PhyGenEval. This framework employs a hierarchical evaluation structure utilizing appropriate advanced vision-language models and large language models to assess physical commonsense. Through PhyGenBench and PhyGenEval, we can conduct large-scale automated assessments of T2V models' understanding of physical commonsense, which align closely with human feedback. Our evaluation results and in-depth analysis demonstrate that current models struggle to generate videos that comply with physical commonsense. Moreover, simply scaling up models or employing prompt engineering techniques is insufficient to fully address the challenges presented by PhyGenBench (e.g., dynamic scenarios). We hope this study will inspire the community to prioritize the learning of physical commonsense in these models beyond entertainment applications. We will release the data and codes at https://github.com/OpenGVLab/PhyGenBench