 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoStir: Understanding Long Videos via Spatio-Temporally Structured and Intent-Aware RAG
Apr 07, 2026Scaling multimodal large language models (MLLMs) to long videos is constrained by limited context windows. While retrieval-augmented generation (RAG) is a promising remedy by organizing query-relevant visual evidence into a compact context, most existing methods (i) flatten videos into independent segments, breaking their inherent spatio-temporal structure, and (ii) depend on explicit semantic matching, which can miss cues that are implicitly relevant to the query's intent. To overcome these limitations, we propose VideoStir, a structured and intent-aware long-video RAG framework. It firstly structures a video as a spatio-temporal graph at clip level, and then performs multi-hop retrieval to aggregate evidence across distant yet contextually related events. Furthermore, it introduces an MLLM-backed intent-relevance scorer that retrieves frames based on their alignment with the query's reasoning intent. To support this capability, we curate IR-600K, a large-scale dataset tailored for learning frame-query intent alignment. Experiments show that VideoStir is competitive with state-of-the-art baselines without relying on auxiliary information, highlighting the promise of shifting long-video RAG from flattened semantic matching to structured, intent-aware reasoning. Codes and checkpoints are available at Github.
OmniLottie: Generating Vector Animations via Parameterized Lottie Tokens
Mar 02, 2026OmniLottie is a versatile framework that generates high quality vector animations from multi-modal instructions. For flexible motion and visual content control, we focus on Lottie, a light weight JSON formatting for both shapes and animation behaviors representation. However, the raw Lottie JSON files contain extensive invariant structural metadata and formatting tokens, posing significant challenges for learning vector animation generation. Therefore, we introduce a well designed Lottie tokenizer that transforms JSON files into structured sequences of commands and parameters representing shapes, animation functions and control parameters. Such tokenizer enables us to build OmniLottie upon pretrained vision language models to follow multi-modal interleaved instructions and generate high quality vector animations. To further advance research in vector animation generation, we curate MMLottie-2M, a large scale dataset of professionally designed vector animations paired with textual and visual annotations. With extensive experiments, we validate that OmniLottie can produce vivid and semantically aligned vector animations that adhere closely to multi modal human instructions.
ContextNav: Towards Agentic Multimodal In-Context Learning
Oct 06, 2025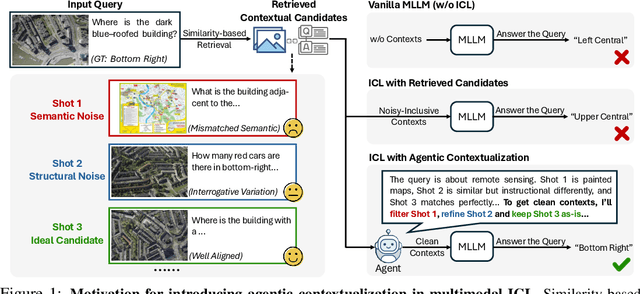
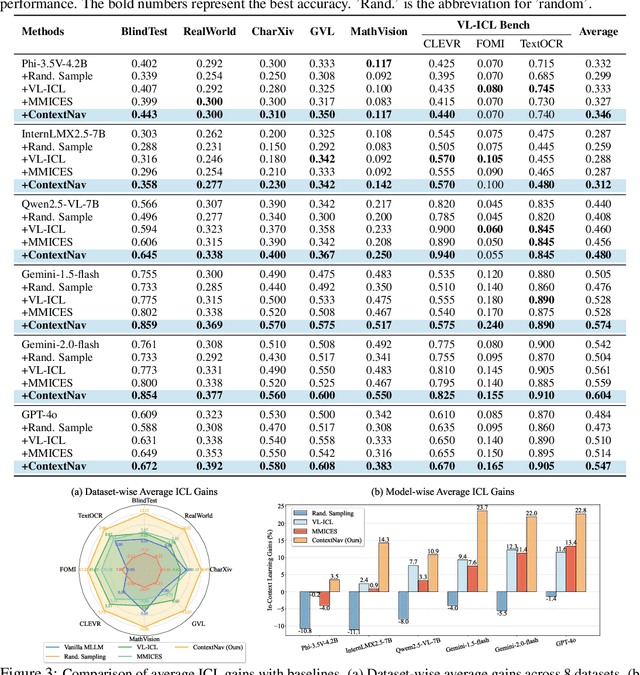
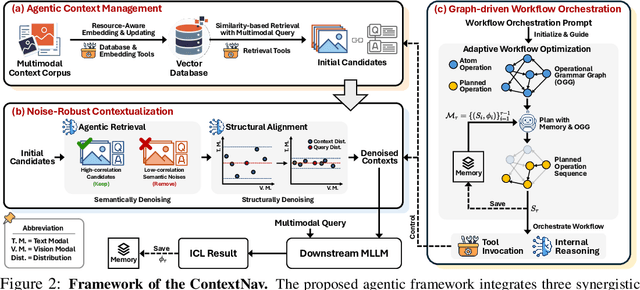
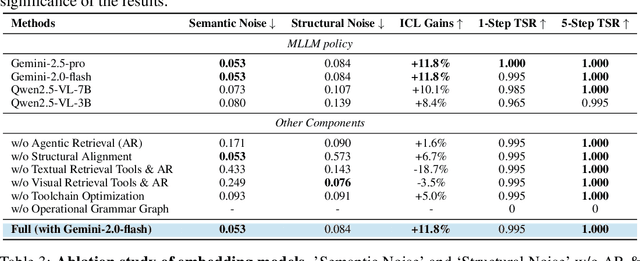
Recent advances demonstrate that multimodal large language models (MLLMs) exhibit strong multimodal in-context learning (ICL) capabilities, enabling them to adapt to novel vision-language tasks from a few contextual examples. However, existing ICL approaches face challenges in reconciling scalability with robustness across diverse tasks and noisy contextual examples: manually selecting examples produces clean contexts but is labor-intensive and task-specific, while similarity-based retrieval improves scalability but could introduce irrelevant or structurally inconsistent samples that degrade ICL performance. To address these limitations, we propose ContextNav, the first agentic framework that integrates the scalability of automated retrieval with the quality and adaptiveness of human-like curation, enabling noise-robust and dynamically optimized contextualization for multimodal ICL. ContextNav unifies context management and noise-robust contextualization within a closed-loop workflow driven by graph-based orchestration. Specifically, it builds a resource-aware multimodal embedding pipeline, maintains a retrievable vector database, and applies agentic retrieval and structural alignment to construct noise-resilient contexts. An Operational Grammar Graph (OGG) further supports adaptive workflow planning and optimization, enabling the agent to refine its operational strategies based on downstream ICL feedback. Experimental results demonstrate that ContextNav achieves state-of-the-art performance across various datasets, underscoring the promise of agentic workflows for advancing scalable and robust contextualization in multimodal ICL.
VistaWise: Building Cost-Effective Agent with Cross-Modal Knowledge Graph for Minecraft
Aug 26, 2025Large language models (LLMs) have shown significant promise in embodied decision-making tasks within virtual open-world environments. Nonetheless, their performance is hindered by the absence of domain-specific knowledge. Methods that finetune on large-scale domain-specific data entail prohibitive development costs. This paper introduces VistaWise, a cost-effective agent framework that integrates cross-modal domain knowledge and finetunes a dedicated object detection model for visual analysis. It reduces the requirement for domain-specific training data from millions of samples to a few hundred. VistaWise integrates visual information and textual dependencies into a cross-modal knowledge graph (KG), enabling a comprehensive and accurate understanding of multimodal environments. We also equip the agent with a retrieval-based pooling strategy to extract task-related information from the KG, and a desktop-level skill library to support direct operation of the Minecraft desktop client via mouse and keyboard inputs. Experimental results demonstrate that VistaWise achieves state-of-the-art performance across various open-world tasks, highlighting its effectiveness in reducing development costs while enhancing agent performance.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
DP-IQA: Utilizing Diffusion Prior for Blind Image Quality Assessment in the Wild
Jun 03, 2024

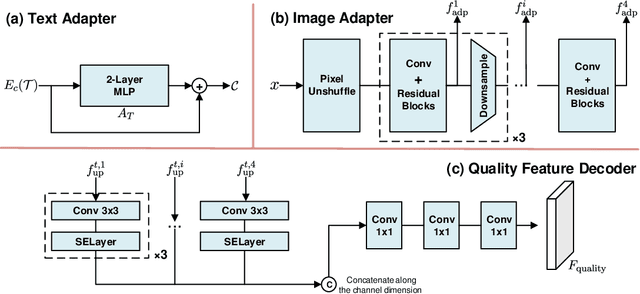

Image quality assessment (IQA) plays a critical role in selecting high-quality images and guiding compression and enhancement methods in a series of applications. The blind IQA, which assesses the quality of in-the-wild images containing complex authentic distortions without reference images, poses greater challenges. Existing methods are limited to modeling a uniform distribution with local patches and are bothered by the gap between low and high-level visions (caused by widely adopted pre-trained classification networks). In this paper, we propose a novel IQA method called diffusion priors-based IQA (DP-IQA), which leverages the prior knowledge from the pre-trained diffusion model with its excellent powers to bridge semantic gaps in the perception of the visual quality of images. Specifically, we use pre-trained stable diffusion as the backbone, extract multi-level features from the denoising U-Net during the upsampling process at a specified timestep, and decode them to estimate the image quality score. The text and image adapters are adopted to mitigate the domain gap for downstream tasks and correct the information loss caused by the variational autoencoder bottleneck. Finally, we distill the knowledge in the above model into a CNN-based student model, significantly reducing the parameter to enhance applicability, with the student model performing similarly or even better than the teacher model surprisingly. Experimental results demonstrate that our DP-IQA achieves state-of-the-art results on various in-the-wild datasets with better generalization capability, which shows the superiority of our method in global modeling and utilizing the hierarchical feature clues of diffusion for evaluating image quality.
BrainVis: Exploring the Bridge between Brain and Visual Signals via Image Reconstruction
Dec 22, 2023



Analyzing and reconstructing visual stimuli from brain signals effectively advances understanding of the human visual system. However, the EEG signals are complex and contain a amount of noise. This leads to substantial limitations in existing works of visual stimuli reconstruction from EEG, such as difficulties in aligning EEG embeddings with the fine-grained semantic information and a heavy reliance on additional large self-collected dataset for training. To address these challenges, we propose a novel approach called BrainVis. Firstly, we divide the EEG signals into various units and apply a self-supervised approach on them to obtain EEG time-domain features, in an attempt to ease the training difficulty. Additionally, we also propose to utilize the frequency-domain features to enhance the EEG representations. Then, we simultaneously align EEG time-frequency embeddings with the interpolation of the coarse and fine-grained semantics in the CLIP space, to highlight the primary visual components and reduce the cross-modal alignment difficulty. Finally, we adopt the cascaded diffusion models to reconstruct images. Our proposed BrainVis outperforms state of the arts in both semantic fidelity reconstruction and generation quality. Notably, we reduce the training data scale to 10% of the previous work.
SDR-GAIN: A High Real-Time Occluded Pedestrian Pose Completion Method for Autonomous Driving
Jun 10, 2023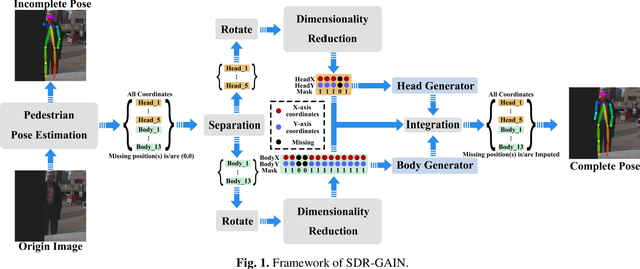
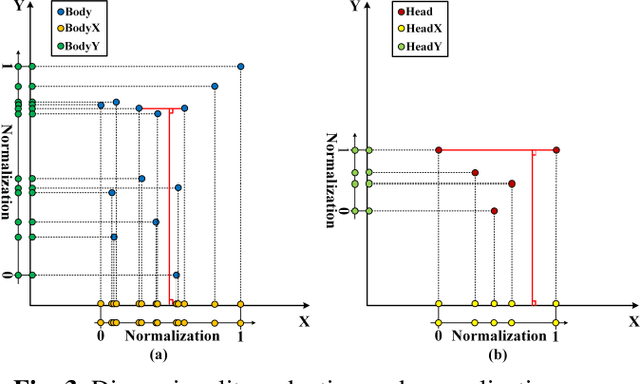
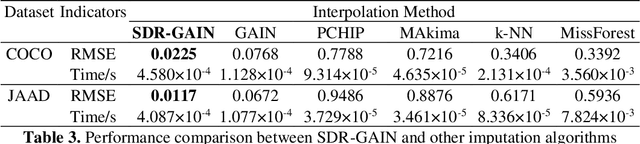
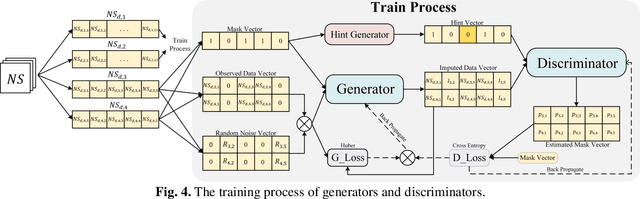
To mitigate the challenges arising from partial occlusion in human pose keypoint based pedestrian detection methods , we present a novel pedestrian pose keypoint completion method called the separation and dimensionality reduction-based generative adversarial imputation networks (SDR-GAIN). Firstly, we utilize OpenPose to estimate pedestrian poses in images. Then, we isolate the head and torso keypoints of pedestrians with incomplete keypoints due to occlusion or other factors and perform dimensionality reduction to enhance features and further unify feature distribution. Finally, we introduce two generative models based on the generative adversarial networks (GAN) framework, which incorporate Huber loss, residual structure, and L1 regularization to generate missing parts of the incomplete head and torso pose keypoints of partially occluded pedestrians, resulting in pose completion. Our experiments on MS COCO and JAAD datasets demonstrate that SDR-GAIN outperforms basic GAIN framework, interpolation methods PCHIP and MAkima, machine learning methods k-NN and MissForest in terms of pose completion task. Furthermore, the SDR-GAIN algorithm exhibits a remarkably short running time of approximately 0.4ms and boasts exceptional real-time performance. As such, it holds significant practical value in the domain of autonomous driving, wherein high system response speeds are of paramount importance. Specifically, it excels at rapidly and precisely capturing human pose key points, thus enabling an expanded range of applications for pedestrian detection tasks based on pose key points, including but not limited to pedestrian behavior recognition and prediction.