 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
EMMA: Your Text-to-Image Diffusion Model Can Secretly Accept Multi-Modal Prompts
Jun 13, 2024Recent advancements in image generation have enabled the creation of high-quality images from text conditions. However, when facing multi-modal conditions, such as text combined with reference appearances, existing methods struggle to balance multiple conditions effectively, typically showing a preference for one modality over others. To address this challenge, we introduce EMMA, a novel image generation model accepting multi-modal prompts built upon the state-of-the-art text-to-image (T2I) diffusion model, ELLA. EMMA seamlessly incorporates additional modalities alongside text to guide image generation through an innovative Multi-modal Feature Connector design, which effectively integrates textual and supplementary modal information using a special attention mechanism. By freezing all parameters in the original T2I diffusion model and only adjusting some additional layers, we reveal an interesting finding that the pre-trained T2I diffusion model can secretly accept multi-modal prompts. This interesting property facilitates easy adaptation to different existing frameworks, making EMMA a flexible and effective tool for producing personalized and context-aware images and even videos. Additionally, we introduce a strategy to assemble learned EMMA modules to produce images conditioned on multiple modalities simultaneously, eliminating the need for additional training with mixed multi-modal prompts. Extensive experiments demonstrate the effectiveness of EMMA in maintaining high fidelity and detail in generated images, showcasing its potential as a robust solution for advanced multi-modal conditional image generation tasks.
Dual-Perspective Knowledge Enrichment for Semi-Supervised 3D Object Detection
Jan 10, 2024



Semi-supervised 3D object detection is a promising yet under-explored direction to reduce data annotation costs, especially for cluttered indoor scenes. A few prior works, such as SESS and 3DIoUMatch, attempt to solve this task by utilizing a teacher model to generate pseudo-labels for unlabeled samples. However, the availability of unlabeled samples in the 3D domain is relatively limited compared to its 2D counterpart due to the greater effort required to collect 3D data. Moreover, the loose consistency regularization in SESS and restricted pseudo-label selection strategy in 3DIoUMatch lead to either low-quality supervision or a limited amount of pseudo labels. To address these issues, we present a novel Dual-Perspective Knowledge Enrichment approach named DPKE for semi-supervised 3D object detection. Our DPKE enriches the knowledge of limited training data, particularly unlabeled data, from two perspectives: data-perspective and feature-perspective. Specifically, from the data-perspective, we propose a class-probabilistic data augmentation method that augments the input data with additional instances based on the varying distribution of class probabilities. Our DPKE achieves feature-perspective knowledge enrichment by designing a geometry-aware feature matching method that regularizes feature-level similarity between object proposals from the student and teacher models. Extensive experiments on the two benchmark datasets demonstrate that our DPKE achieves superior performance over existing state-of-the-art approaches under various label ratio conditions. The source code will be made available to the public.
AppAgent: Multimodal Agents as Smartphone Users
Dec 22, 2023



Recent advancements in large language models (LLMs) have led to the creation of intelligent agents capable of performing complex tasks. This paper introduces a novel LLM-based multimodal agent framework designed to operate smartphone applications. Our framework enables the agent to operate smartphone applications through a simplified action space, mimicking human-like interactions such as tapping and swiping. This novel approach bypasses the need for system back-end access, thereby broadening its applicability across diverse apps. Central to our agent's functionality is its innovative learning method. The agent learns to navigate and use new apps either through autonomous exploration or by observing human demonstrations. This process generates a knowledge base that the agent refers to for executing complex tasks across different applications. To demonstrate the practicality of our agent, we conducted extensive testing over 50 tasks in 10 different applications, including social media, email, maps, shopping, and sophisticated image editing tools. The results affirm our agent's proficiency in handling a diverse array of high-level tasks.
ICD-LM: Configuring Vision-Language In-Context Demonstrations by Language Modeling
Dec 22, 2023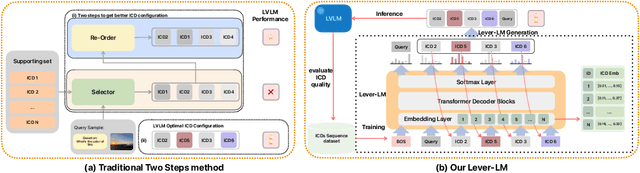
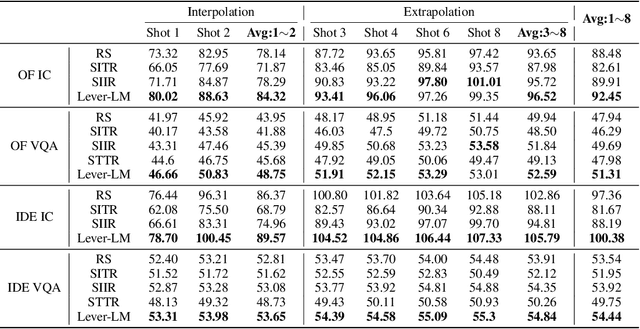
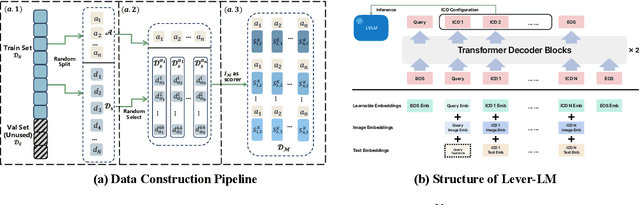
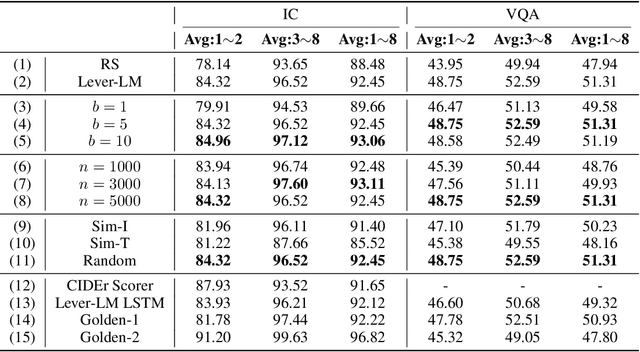
This paper studies how to configure powerful In-Context Demonstration (ICD) sequences for a Large Vision-Language Model (LVLM) to solve Vision-Language tasks through In-Context Learning (ICL). After observing that configuring an ICD sequence is a mirror process of composing a sentence, i.e., just as a sentence can be composed word by word via a Language Model, an ICD sequence can also be configured one by one. Consequently, we introduce an ICD Language Model (ICD-LM) specifically designed to generate effective ICD sequences. This involves creating a dataset of hand-crafted ICD sequences for various query samples and using it to train the ICD-LM. Our approach, diverging from traditional methods in NLP that select and order ICDs separately, enables to simultaneously learn how to select and order ICDs, enhancing the effect of the sequences. Moreover, during data construction, we use the LVLM intended for ICL implementation to validate the strength of each ICD sequence, resulting in a model-specific dataset and the ICD-LM trained by this dataset is also model-specific. We validate our methodology through experiments in Visual Question Answering and Image Captioning, confirming the viability of using a Language Model for ICD configuration. Our comprehensive ablation studies further explore the impact of various dataset construction and ICD-LM development settings on the outcomes. The code is given in https://github.com/ForJadeForest/ICD-LM.
ChartLlama: A Multimodal LLM for Chart Understanding and Generation
Nov 27, 2023



Multi-modal large language models have demonstrated impressive performances on most vision-language tasks. However, the model generally lacks the understanding capabilities for specific domain data, particularly when it comes to interpreting chart figures. This is mainly due to the lack of relevant multi-modal instruction tuning datasets. In this article, we create a high-quality instruction-tuning dataset leveraging GPT-4. We develop a multi-step data generation process in which different steps are responsible for generating tabular data, creating chart figures, and designing instruction tuning data separately. Our method's flexibility enables us to generate diverse, high-quality instruction-tuning data consistently and efficiently while maintaining a low resource expenditure. Additionally, it allows us to incorporate a wider variety of chart and task types not yet featured in existing datasets. Next, we introduce ChartLlama, a multi-modal large language model that we've trained using our created dataset. ChartLlama outperforms all prior methods in ChartQA, Chart-to-text, and Chart-extraction evaluation benchmarks. Additionally, ChartLlama significantly improves upon the baseline in our specially compiled chart dataset, which includes new chart and task types. The results of ChartLlama confirm the value and huge potential of our proposed data generation method in enhancing chart comprehension.
Prompt-aligned Gradient for Prompt Tuning
May 30, 2022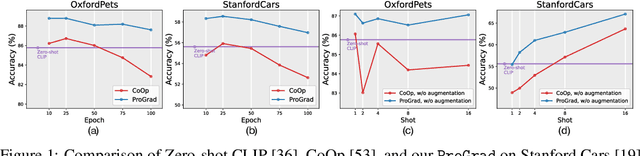
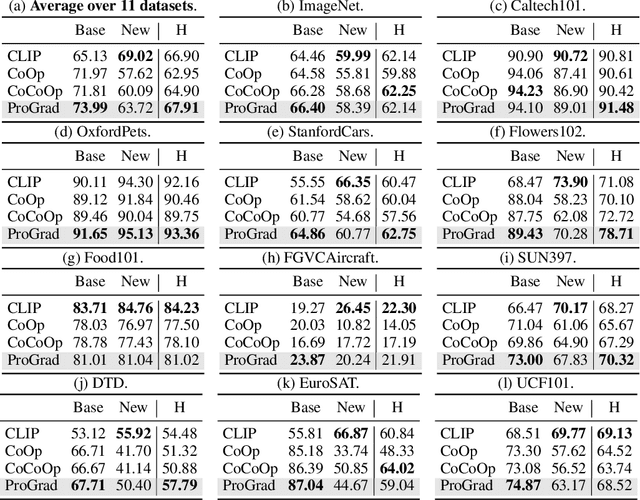

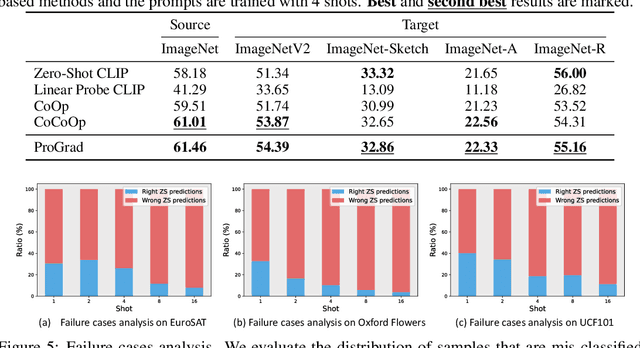
Thanks to the large pre-trained vision-language models (VLMs) like CLIP, we can craft a zero-shot classifier by "prompt", e.g., the confidence score of an image being "[CLASS]" can be obtained by using the VLM provided similarity measure between the image and the prompt sentence "a photo of a [CLASS]". Therefore, prompt shows a great potential for fast adaptation of VLMs to downstream tasks if we fine-tune the prompt-based similarity measure. However, we find a common failure that improper fine-tuning may not only undermine the prompt's inherent prediction for the task-related classes, but also for other classes in the VLM vocabulary. Existing methods still address this problem by using traditional anti-overfitting techniques such as early stopping and data augmentation, which lack a principled solution specific to prompt. We present Prompt-aligned Gradient, dubbed ProGrad, to prevent prompt tuning from forgetting the the general knowledge learned from VLMs. In particular, ProGrad only updates the prompt whose gradient is aligned (or non-conflicting) to the "general direction", which is represented as the gradient of the KL loss of the pre-defined prompt prediction. Extensive experiments demonstrate the stronger few-shot generalization ability of ProGrad over state-of-the-art prompt tuning methods. Codes are available at https://github.com/BeierZhu/Prompt-align.
Fast AdvProp
Apr 21, 2022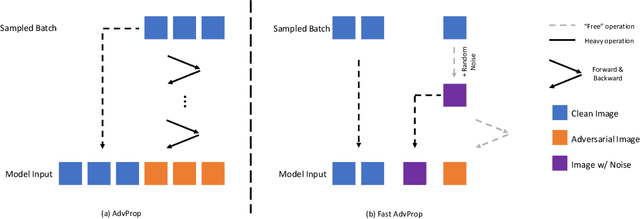


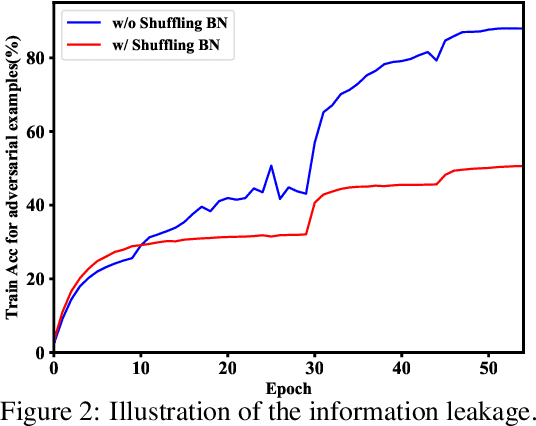
Adversarial Propagation (AdvProp) is an effective way to improve recognition models, leveraging adversarial examples. Nonetheless, AdvProp suffers from the extremely slow training speed, mainly because: a) extra forward and backward passes are required for generating adversarial examples; b) both original samples and their adversarial counterparts are used for training (i.e., 2$\times$ data). In this paper, we introduce Fast AdvProp, which aggressively revamps AdvProp's costly training components, rendering the method nearly as cheap as the vanilla training. Specifically, our modifications in Fast AdvProp are guided by the hypothesis that disentangled learning with adversarial examples is the key for performance improvements, while other training recipes (e.g., paired clean and adversarial training samples, multi-step adversarial attackers) could be largely simplified. Our empirical results show that, compared to the vanilla training baseline, Fast AdvProp is able to further model performance on a spectrum of visual benchmarks, without incurring extra training cost. Additionally, our ablations find Fast AdvProp scales better if larger models are used, is compatible with existing data augmentation methods (i.e., Mixup and CutMix), and can be easily adapted to other recognition tasks like object detection. The code is available here: https://github.com/meijieru/fast_advprop.