 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeURA-Net: Uncertainty-Integrated Anomaly Perception and Restoration Attention Network for Unsupervised Anomaly Detection
Mar 24, 2026Unsupervised anomaly detection plays a pivotal role in industrial defect inspection and medical image analysis, with most methods relying on the reconstruction framework. However, these methods may suffer from over-generalization, enabling them to reconstruct anomalies well, which leads to poor detection performance. To address this issue, instead of focusing solely on normality reconstruction, we propose an innovative Uncertainty-Integrated Anomaly Perception and Restoration Attention Network (URA-Net), which explicitly restores abnormal patterns to their corresponding normality. First, unlike traditional image reconstruction methods, we utilize a pre-trained convolutional neural network to extract multi-level semantic features as the reconstruction target. To assist the URA-Net learning to restore anomalies, we introduce a novel feature-level artificial anomaly synthesis module to generate anomalous samples for training. Subsequently, a novel uncertainty-integrated anomaly perception module based on Bayesian neural networks is introduced to learn the distributions of anomalous and normal features. This facilitates the estimation of anomalous regions and ambiguous boundaries, laying the foundation for subsequent anomaly restoration. Then, we propose a novel restoration attention mechanism that leverages global normal semantic information to restore detected anomalous regions, thereby obtaining defect-free restored features. Finally, we employ residual maps between input features and restored features for anomaly detection and localization. The comprehensive experimental results on two industrial datasets, MVTec AD and BTAD, along with a medical image dataset, OCT-2017, unequivocally demonstrate the effectiveness and superiority of the proposed method.
Cognitive Mismatch in Multimodal Large Language Models for Discrete Symbol Understanding
Mar 19, 2026While Multimodal Large Language Models (MLLMs) have achieved remarkable success in interpreting natural scenes, their ability to process discrete symbols -- the fundamental building blocks of human cognition -- remains a critical open question. Unlike continuous visual data, symbols such as mathematical formulas, chemical structures, and linguistic characters require precise, deeper interpretation. This paper introduces a comprehensive benchmark to evaluate how top-tier MLLMs navigate these "discrete semantic spaces" across five domains: language, culture, mathematics, physics, and chemistry. Our investigation uncovers a counterintuitive phenomenon: models often fail at basic symbol recognition yet succeed in complex reasoning tasks, suggesting they rely on linguistic probability rather than true visual perception. By exposing this "cognitive mismatch", we highlight a significant gap in current AI capabilities: the struggle to truly perceive and understand the symbolic languages that underpin scientific discovery and abstract thought. This work offers a roadmap for developing more rigorous, human-aligned intelligent systems.
WithAnyone: Towards Controllable and ID Consistent Image Generation
Oct 16, 2025Identity-consistent generation has become an important focus in text-to-image research, with recent models achieving notable success in producing images aligned with a reference identity. Yet, the scarcity of large-scale paired datasets containing multiple images of the same individual forces most approaches to adopt reconstruction-based training. This reliance often leads to a failure mode we term copy-paste, where the model directly replicates the reference face rather than preserving identity across natural variations in pose, expression, or lighting. Such over-similarity undermines controllability and limits the expressive power of generation. To address these limitations, we (1) construct a large-scale paired dataset MultiID-2M, tailored for multi-person scenarios, providing diverse references for each identity; (2) introduce a benchmark that quantifies both copy-paste artifacts and the trade-off between identity fidelity and variation; and (3) propose a novel training paradigm with a contrastive identity loss that leverages paired data to balance fidelity with diversity. These contributions culminate in WithAnyone, a diffusion-based model that effectively mitigates copy-paste while preserving high identity similarity. Extensive qualitative and quantitative experiments demonstrate that WithAnyone significantly reduces copy-paste artifacts, improves controllability over pose and expression, and maintains strong perceptual quality. User studies further validate that our method achieves high identity fidelity while enabling expressive controllable generation.
OneIG-Bench: Omni-dimensional Nuanced Evaluation for Image Generation
Jun 09, 2025Text-to-image (T2I) models have garnered significant attention for generating high-quality images aligned with text prompts. However, rapid T2I model advancements reveal limitations in early benchmarks, lacking comprehensive evaluations, for example, the evaluation on reasoning, text rendering and style. Notably, recent state-of-the-art models, with their rich knowledge modeling capabilities, show promising results on the image generation problems requiring strong reasoning ability, yet existing evaluation systems have not adequately addressed this frontier. To systematically address these gaps, we introduce OneIG-Bench, a meticulously designed comprehensive benchmark framework for fine-grained evaluation of T2I models across multiple dimensions, including prompt-image alignment, text rendering precision, reasoning-generated content, stylization, and diversity. By structuring the evaluation, this benchmark enables in-depth analysis of model performance, helping researchers and practitioners pinpoint strengths and bottlenecks in the full pipeline of image generation. Specifically, OneIG-Bench enables flexible evaluation by allowing users to focus on a particular evaluation subset. Instead of generating images for the entire set of prompts, users can generate images only for the prompts associated with the selected dimension and complete the corresponding evaluation accordingly. Our codebase and dataset are now publicly available to facilitate reproducible evaluation studies and cross-model comparisons within the T2I research community.
Step1X-Edit: A Practical Framework for General Image Editing
Apr 24, 2025In recent years, image editing models have witnessed remarkable and rapid development. The recent unveiling of cutting-edge multimodal models such as GPT-4o and Gemini2 Flash has introduced highly promising image editing capabilities. These models demonstrate an impressive aptitude for fulfilling a vast majority of user-driven editing requirements, marking a significant advancement in the field of image manipulation. However, there is still a large gap between the open-source algorithm with these closed-source models. Thus, in this paper, we aim to release a state-of-the-art image editing model, called Step1X-Edit, which can provide comparable performance against the closed-source models like GPT-4o and Gemini2 Flash. More specifically, we adopt the Multimodal LLM to process the reference image and the user's editing instruction. A latent embedding has been extracted and integrated with a diffusion image decoder to obtain the target image. To train the model, we build a data generation pipeline to produce a high-quality dataset. For evaluation, we develop the GEdit-Bench, a novel benchmark rooted in real-world user instructions. Experimental results on GEdit-Bench demonstrate that Step1X-Edit outperforms existing open-source baselines by a substantial margin and approaches the performance of leading proprietary models, thereby making significant contributions to the field of image editing.
Dynamic Pyramid Network for Efficient Multimodal Large Language Model
Mar 26, 2025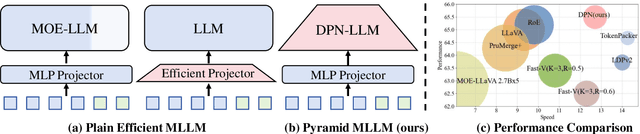

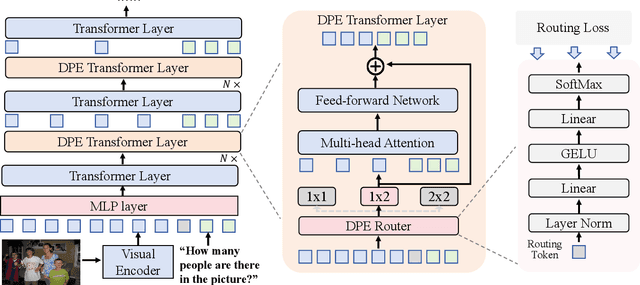

Multimodal large language models (MLLMs) have demonstrated impressive performance in various vision-language (VL) tasks, but their expensive computations still limit the real-world application. To address this issue, recent efforts aim to compress the visual features to save the computational costs of MLLMs. However, direct visual compression methods, e.g. efficient projectors, inevitably destroy the visual semantics in MLLM, especially in difficult samples. To overcome this shortcoming, we propose a novel dynamic pyramid network (DPN) for efficient MLLMs. Specifically, DPN formulates MLLM as a hierarchical structure where visual features are gradually compressed with increasing depth. In this case, even with a high compression ratio, fine-grained visual information can still be perceived in shallow layers. To maximize the benefit of DPN, we further propose an innovative Dynamic Pooling Experts (DPE) that can dynamically choose the optimal visual compression rate according to input features. With this design, harder samples will be assigned larger computations, thus preserving the model performance. To validate our approach, we conduct extensive experiments on two popular MLLMs and ten benchmarks. Experimental results show that DPN can save up to 56% average FLOPs on LLaVA while further achieving +0.74% performance gains. Besides, the generalization ability of DPN is also validated on the existing high-resolution MLLM called LLaVA-HR. Our source codes are anonymously released at https://github.com/aihao2000/DPN-LLaVA.
3CAD: A Large-Scale Real-World 3C Product Dataset for Unsupervised Anomaly
Feb 09, 2025



Industrial anomaly detection achieves progress thanks to datasets such as MVTec-AD and VisA. However, they suf- fer from limitations in terms of the number of defect sam- ples, types of defects, and availability of real-world scenes. These constraints inhibit researchers from further exploring the performance of industrial detection with higher accuracy. To this end, we propose a new large-scale anomaly detection dataset called 3CAD, which is derived from real 3C produc- tion lines. Specifically, the proposed 3CAD includes eight different types of manufactured parts, totaling 27,039 high- resolution images labeled with pixel-level anomalies. The key features of 3CAD are that it covers anomalous regions of different sizes, multiple anomaly types, and the possibility of multiple anomalous regions and multiple anomaly types per anomaly image. This is the largest and first anomaly de- tection dataset dedicated to 3C product quality control for community exploration and development. Meanwhile, we in- troduce a simple yet effective framework for unsupervised anomaly detection: a Coarse-to-Fine detection paradigm with Recovery Guidance (CFRG). To detect small defect anoma- lies, the proposed CFRG utilizes a coarse-to-fine detection paradigm. Specifically, we utilize a heterogeneous distilla- tion model for coarse localization and then fine localiza- tion through a segmentation model. In addition, to better capture normal patterns, we introduce recovery features as guidance. Finally, we report the results of our CFRG frame- work and popular anomaly detection methods on the 3CAD dataset, demonstrating strong competitiveness and providing a highly challenging benchmark to promote the development of the anomaly detection field. Data and code are available: https://github.com/EnquanYang2022/3CAD.
InstantIR: Blind Image Restoration with Instant Generative Reference
Oct 09, 2024



Handling test-time unknown degradation is the major challenge in Blind Image Restoration (BIR), necessitating high model generalization. An effective strategy is to incorporate prior knowledge, either from human input or generative model. In this paper, we introduce Instant-reference Image Restoration (InstantIR), a novel diffusion-based BIR method which dynamically adjusts generation condition during inference. We first extract a compact representation of the input via a pre-trained vision encoder. At each generation step, this representation is used to decode current diffusion latent and instantiate it in the generative prior. The degraded image is then encoded with this reference, providing robust generation condition. We observe the variance of generative references fluctuate with degradation intensity, which we further leverage as an indicator for developing a sampling algorithm adaptive to input quality. Extensive experiments demonstrate InstantIR achieves state-of-the-art performance and offering outstanding visual quality. Through modulating generative references with textual description, InstantIR can restore extreme degradation and additionally feature creative restoration.
CSGO: Content-Style Composition in Text-to-Image Generation
Sep 04, 2024

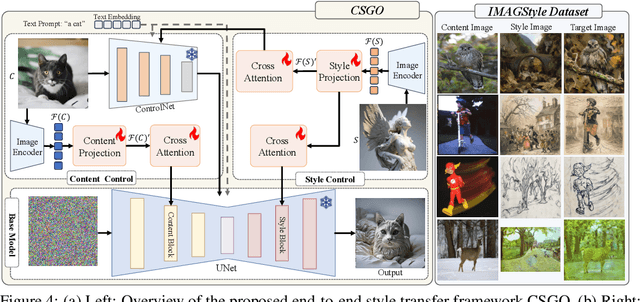
The diffusion model has shown exceptional capabilities in controlled image generation, which has further fueled interest in image style transfer. Existing works mainly focus on training free-based methods (e.g., image inversion) due to the scarcity of specific data. In this study, we present a data construction pipeline for content-style-stylized image triplets that generates and automatically cleanses stylized data triplets. Based on this pipeline, we construct a dataset IMAGStyle, the first large-scale style transfer dataset containing 210k image triplets, available for the community to explore and research. Equipped with IMAGStyle, we propose CSGO, a style transfer model based on end-to-end training, which explicitly decouples content and style features employing independent feature injection. The unified CSGO implements image-driven style transfer, text-driven stylized synthesis, and text editing-driven stylized synthesis. Extensive experiments demonstrate the effectiveness of our approach in enhancing style control capabilities in image generation. Additional visualization and access to the source code can be located on the project page: \url{https://csgo-gen.github.io/}.
EXCGEC: A Benchmark of Edit-wise Explainable Chinese Grammatical Error Correction
Jul 01, 2024



Existing studies explore the explainability of Grammatical Error Correction (GEC) in a limited scenario, where they ignore the interaction between corrections and explanations. To bridge the gap, this paper introduces the task of EXplainable GEC (EXGEC), which focuses on the integral role of both correction and explanation tasks. To facilitate the task, we propose EXCGEC, a tailored benchmark for Chinese EXGEC consisting of 8,216 explanation-augmented samples featuring the design of hybrid edit-wise explanations. We benchmark several series of LLMs in multiple settings, covering post-explaining and pre-explaining. To promote the development of the task, we introduce a comprehensive suite of automatic metrics and conduct human evaluation experiments to demonstrate the human consistency of the automatic metrics for free-text explanations. All the codes and data will be released after the review.