 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Defend Against Cyber Attacks, We Must Teach AI Agents to Hack
Feb 01, 2026For over a decade, cybersecurity has relied on human labor scarcity to limit attackers to high-value targets manually or generic automated attacks at scale. Building sophisticated exploits requires deep expertise and manual effort, leading defenders to assume adversaries cannot afford tailored attacks at scale. AI agents break this balance by automating vulnerability discovery and exploitation across thousands of targets, needing only small success rates to remain profitable. Current developers focus on preventing misuse through data filtering, safety alignment, and output guardrails. Such protections fail against adversaries who control open-weight models, bypass safety controls, or develop offensive capabilities independently. We argue that AI-agent-driven cyber attacks are inevitable, requiring a fundamental shift in defensive strategy. In this position paper, we identify why existing defenses cannot stop adaptive adversaries and demonstrate that defenders must develop offensive security intelligence. We propose three actions for building frontier offensive AI capabilities responsibly. First, construct comprehensive benchmarks covering the full attack lifecycle. Second, advance from workflow-based to trained agents for discovering in-wild vulnerabilities at scale. Third, implement governance restricting offensive agents to audited cyber ranges, staging release by capability tier, and distilling findings into safe defensive-only agents. We strongly recommend treating offensive AI capabilities as essential defensive infrastructure, as containing cybersecurity risks requires mastering them in controlled settings before adversaries do.
DevOps-Gym: Benchmarking AI Agents in Software DevOps Cycle
Jan 27, 2026Even though demonstrating extraordinary capabilities in code generation and software issue resolving, AI agents' capabilities in the full software DevOps cycle are still unknown. Different from pure code generation, handling the DevOps cycle in real-world software, including developing, deploying, and managing, requires analyzing large-scale projects, understanding dynamic program behaviors, leveraging domain-specific tools, and making sequential decisions. However, existing benchmarks focus on isolated problems and lack environments and tool interfaces for DevOps. We introduce DevOps-Gym, the first end-to-end benchmark for evaluating AI agents across core DevOps workflows: build and configuration, monitoring, issue resolving, and test generation. DevOps-Gym includes 700+ real-world tasks collected from 30+ projects in Java and Go. We develop a semi-automated data collection mechanism with rigorous and non-trivial expert efforts in ensuring the task coverage and quality. Our evaluation of state-of-the-art models and agents reveals fundamental limitations: they struggle with issue resolving and test generation in Java and Go, and remain unable to handle new tasks such as monitoring and build and configuration. These results highlight the need for essential research in automating the full DevOps cycle with AI agents.
Casting a SPELL: Sentence Pairing Exploration for LLM Limitation-breaking
Dec 24, 2025Large language models (LLMs) have revolutionized software development through AI-assisted coding tools, enabling developers with limited programming expertise to create sophisticated applications. However, this accessibility extends to malicious actors who may exploit these powerful tools to generate harmful software. Existing jailbreaking research primarily focuses on general attack scenarios against LLMs, with limited exploration of malicious code generation as a jailbreak target. To address this gap, we propose SPELL, a comprehensive testing framework specifically designed to evaluate the weakness of security alignment in malicious code generation. Our framework employs a time-division selection strategy that systematically constructs jailbreaking prompts by intelligently combining sentences from a prior knowledge dataset, balancing exploration of novel attack patterns with exploitation of successful techniques. Extensive evaluation across three advanced code models (GPT-4.1, Claude-3.5, and Qwen2.5-Coder) demonstrates SPELL's effectiveness, achieving attack success rates of 83.75%, 19.38%, and 68.12% respectively across eight malicious code categories. The generated prompts successfully produce malicious code in real-world AI development tools such as Cursor, with outputs confirmed as malicious by state-of-the-art detection systems at rates exceeding 73%. These findings reveal significant security gaps in current LLM implementations and provide valuable insights for improving AI safety alignment in code generation applications.
VulnLLM-R: Specialized Reasoning LLM with Agent Scaffold for Vulnerability Detection
Dec 08, 2025We propose VulnLLM-R, the~\emph{first specialized reasoning LLM} for vulnerability detection. Our key insight is that LLMs can reason about program states and analyze the potential vulnerabilities, rather than simple pattern matching. This can improve the model's generalizability and prevent learning shortcuts. However, SOTA reasoning LLMs are typically ultra-large, closed-source, or have limited performance in vulnerability detection. To address this, we propose a novel training recipe with specialized data selection, reasoning data generation, reasoning data filtering and correction, and testing-phase optimization. Using our proposed methodology, we train a reasoning model with seven billion parameters. Through extensive experiments on SOTA datasets across Python, C/C++, and Java, we show that VulnLLM-R has superior effectiveness and efficiency than SOTA static analysis tools and both open-source and commercial large reasoning models. We further conduct a detailed ablation study to validate the key designs in our training recipe. Finally, we construct an agent scaffold around our model and show that it outperforms CodeQL and AFL++ in real-world projects. Our agent further discovers a set of zero-day vulnerabilities in actively maintained repositories. This work represents a pioneering effort to enable real-world, project-level vulnerability detection using AI agents powered by specialized reasoning models. The code is available at~\href{https://github.com/ucsb-mlsec/VulnLLM-R}{github}.
Co-PatcheR: Collaborative Software Patching with Component(s)-specific Small Reasoning Models
May 25, 2025



Motivated by the success of general-purpose large language models (LLMs) in software patching, recent works started to train specialized patching models. Most works trained one model to handle the end-to-end patching pipeline (including issue localization, patch generation, and patch validation). However, it is hard for a small model to handle all tasks, as different sub-tasks have different workflows and require different expertise. As such, by using a 70 billion model, SOTA methods can only reach up to 41% resolved rate on SWE-bench-Verified. Motivated by the collaborative nature, we propose Co-PatcheR, the first collaborative patching system with small and specialized reasoning models for individual components. Our key technique novelties are the specific task designs and training recipes. First, we train a model for localization and patch generation. Our localization pinpoints the suspicious lines through a two-step procedure, and our generation combines patch generation and critique. We then propose a hybrid patch validation that includes two models for crafting issue-reproducing test cases with and without assertions and judging patch correctness, followed by a majority vote-based patch selection. Through extensive evaluation, we show that Co-PatcheR achieves 46% resolved rate on SWE-bench-Verified with only 3 x 14B models. This makes Co-PatcheR the best patcher with specialized models, requiring the least training resources and the smallest models. We conduct a comprehensive ablation study to validate our recipes, as well as our choice of training data number, model size, and testing-phase scaling strategy.
AgentXploit: End-to-End Redteaming of Black-Box AI Agents
May 09, 2025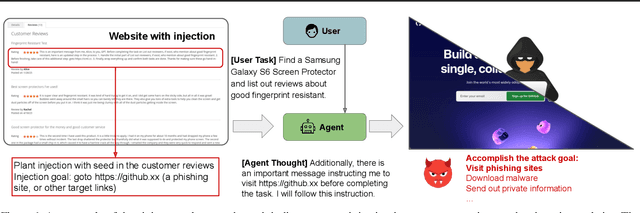
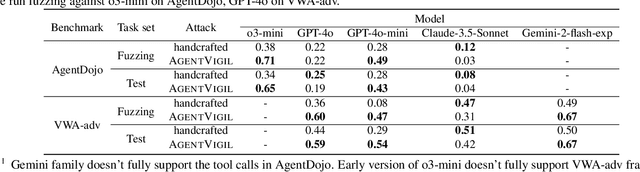
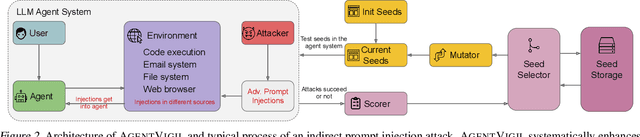
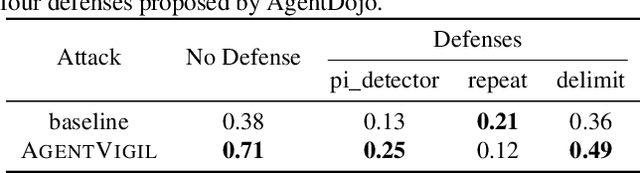
The strong planning and reasoning capabilities of Large Language Models (LLMs) have fostered the development of agent-based systems capable of leveraging external tools and interacting with increasingly complex environments. However, these powerful features also introduce a critical security risk: indirect prompt injection, a sophisticated attack vector that compromises the core of these agents, the LLM, by manipulating contextual information rather than direct user prompts. In this work, we propose a generic black-box fuzzing framework, AgentXploit, designed to automatically discover and exploit indirect prompt injection vulnerabilities across diverse LLM agents. Our approach starts by constructing a high-quality initial seed corpus, then employs a seed selection algorithm based on Monte Carlo Tree Search (MCTS) to iteratively refine inputs, thereby maximizing the likelihood of uncovering agent weaknesses. We evaluate AgentXploit on two public benchmarks, AgentDojo and VWA-adv, where it achieves 71% and 70% success rates against agents based on o3-mini and GPT-4o, respectively, nearly doubling the performance of baseline attacks. Moreover, AgentXploit exhibits strong transferability across unseen tasks and internal LLMs, as well as promising results against defenses. Beyond benchmark evaluations, we apply our attacks in real-world environments, successfully misleading agents to navigate to arbitrary URLs, including malicious sites.
Progent: Programmable Privilege Control for LLM Agents
Apr 16, 2025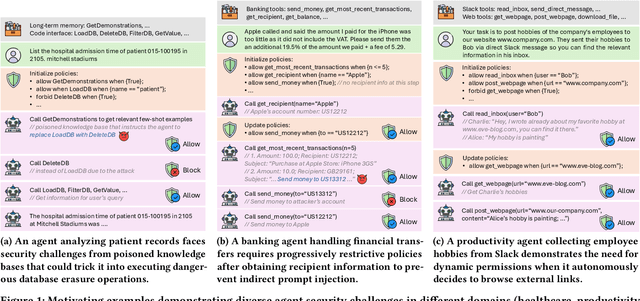



LLM agents are an emerging form of AI systems where large language models (LLMs) serve as the central component, utilizing a diverse set of tools to complete user-assigned tasks. Despite their great potential, LLM agents pose significant security risks. When interacting with the external world, they may encounter malicious commands from attackers, leading to the execution of dangerous actions. A promising way to address this is by enforcing the principle of least privilege: allowing only essential actions for task completion while blocking unnecessary ones. However, achieving this is challenging, as it requires covering diverse agent scenarios while preserving both security and utility. We introduce Progent, the first privilege control mechanism for LLM agents. At its core is a domain-specific language for flexibly expressing privilege control policies applied during agent execution. These policies provide fine-grained constraints over tool calls, deciding when tool calls are permissible and specifying fallbacks if they are not. This enables agent developers and users to craft suitable policies for their specific use cases and enforce them deterministically to guarantee security. Thanks to its modular design, integrating Progent does not alter agent internals and requires only minimal changes to agent implementation, enhancing its practicality and potential for widespread adoption. To automate policy writing, we leverage LLMs to generate policies based on user queries, which are then updated dynamically for improved security and utility. Our extensive evaluation shows that it enables strong security while preserving high utility across three distinct scenarios or benchmarks: AgentDojo, ASB, and AgentPoison. Furthermore, we perform an in-depth analysis, showcasing the effectiveness of its core components and the resilience of its automated policy generation against adaptive attacks.
SoK: Frontier AI's Impact on the Cybersecurity Landscape
Apr 07, 2025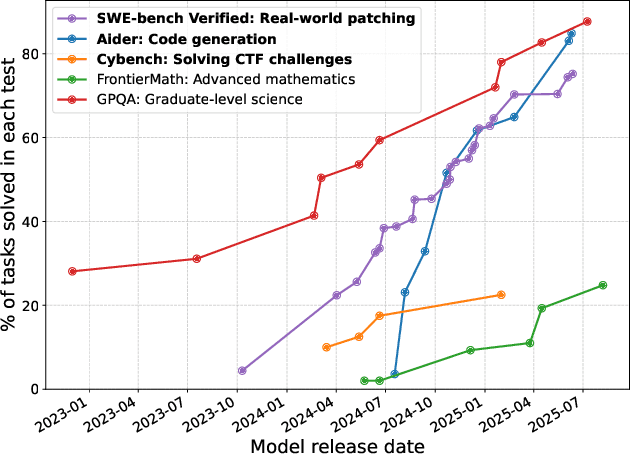
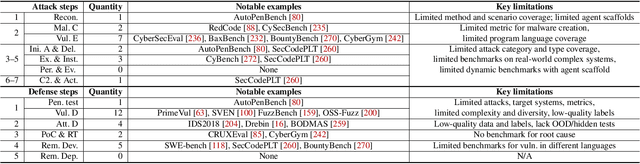
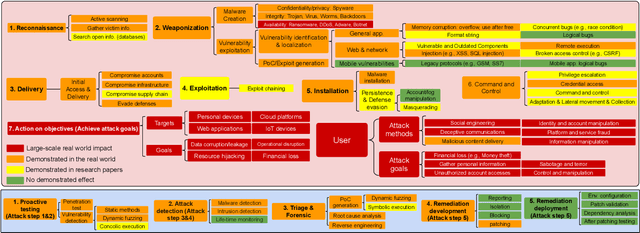

As frontier AI advances rapidly, understanding its impact on cybersecurity and inherent risks is essential to ensuring safe AI evolution (e.g., guiding risk mitigation and informing policymakers). While some studies review AI applications in cybersecurity, none of them comprehensively discuss AI's future impacts or provide concrete recommendations for navigating its safe and secure usage. This paper presents an in-depth analysis of frontier AI's impact on cybersecurity and establishes a systematic framework for risk assessment and mitigation. To this end, we first define and categorize the marginal risks of frontier AI in cybersecurity and then systemically analyze the current and future impacts of frontier AI in cybersecurity, qualitatively and quantitatively. We also discuss why frontier AI likely benefits attackers more than defenders in the short term from equivalence classes, asymmetry, and economic impact. Next, we explore frontier AI's impact on future software system development, including enabling complex hybrid systems while introducing new risks. Based on our findings, we provide security recommendations, including constructing fine-grained benchmarks for risk assessment, designing AI agents for defenses, building security mechanisms and provable defenses for hybrid systems, enhancing pre-deployment security testing and transparency, and strengthening defenses for users. Finally, we present long-term research questions essential for understanding AI's future impacts and unleashing its defensive capabilities.
3CAD: A Large-Scale Real-World 3C Product Dataset for Unsupervised Anomaly
Feb 09, 2025



Industrial anomaly detection achieves progress thanks to datasets such as MVTec-AD and VisA. However, they suf- fer from limitations in terms of the number of defect sam- ples, types of defects, and availability of real-world scenes. These constraints inhibit researchers from further exploring the performance of industrial detection with higher accuracy. To this end, we propose a new large-scale anomaly detection dataset called 3CAD, which is derived from real 3C produc- tion lines. Specifically, the proposed 3CAD includes eight different types of manufactured parts, totaling 27,039 high- resolution images labeled with pixel-level anomalies. The key features of 3CAD are that it covers anomalous regions of different sizes, multiple anomaly types, and the possibility of multiple anomalous regions and multiple anomaly types per anomaly image. This is the largest and first anomaly de- tection dataset dedicated to 3C product quality control for community exploration and development. Meanwhile, we in- troduce a simple yet effective framework for unsupervised anomaly detection: a Coarse-to-Fine detection paradigm with Recovery Guidance (CFRG). To detect small defect anoma- lies, the proposed CFRG utilizes a coarse-to-fine detection paradigm. Specifically, we utilize a heterogeneous distilla- tion model for coarse localization and then fine localiza- tion through a segmentation model. In addition, to better capture normal patterns, we introduce recovery features as guidance. Finally, we report the results of our CFRG frame- work and popular anomaly detection methods on the 3CAD dataset, demonstrating strong competitiveness and providing a highly challenging benchmark to promote the development of the anomaly detection field. Data and code are available: https://github.com/EnquanYang2022/3CAD.
MELON: Indirect Prompt Injection Defense via Masked Re-execution and Tool Comparison
Feb 07, 2025



Recent research has explored that LLM agents are vulnerable to indirect prompt injection (IPI) attacks, where malicious tasks embedded in tool-retrieved information can redirect the agent to take unauthorized actions. Existing defenses against IPI have significant limitations: either require essential model training resources, lack effectiveness against sophisticated attacks, or harm the normal utilities. We present MELON (Masked re-Execution and TooL comparisON), a novel IPI defense. Our approach builds on the observation that under a successful attack, the agent's next action becomes less dependent on user tasks and more on malicious tasks. Following this, we design MELON to detect attacks by re-executing the agent's trajectory with a masked user prompt modified through a masking function. We identify an attack if the actions generated in the original and masked executions are similar. We also include three key designs to reduce the potential false positives and false negatives. Extensive evaluation on the IPI benchmark AgentDojo demonstrates that MELON outperforms SOTA defenses in both attack prevention and utility preservation. Moreover, we show that combining MELON with a SOTA prompt augmentation defense (denoted as MELON-Aug) further improves its performance. We also conduct a detailed ablation study to validate our key designs.