 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecPI: Secure Code Generation with Reasoning Models via Security Reasoning Internalization
Apr 04, 2026Reasoning language models (RLMs) are increasingly used in programming. Yet, even state-of-the-art RLMs frequently introduce critical security vulnerabilities in generated code. Prior training-based approaches for secure code generation face a critical limitation that prevents their direct application to RLMs: they rely on costly, manually curated security datasets covering only a limited set of vulnerabilities. At the inference level, generic security reminders consistently degrade functional correctness while triggering only shallow ad-hoc vulnerability analysis. To address these problems, we present SecPI, a fine-tuning pipeline that teaches RLMs to internalize structured security reasoning, producing secure code by default without any security instructions at inference time. SecPI filters existing general-purpose coding datasets for security-relevant tasks using an LLM-based classifier, generates high-quality security reasoning traces with a teacher model guided by a structured prompt that systematically enumerates relevant CWEs and mitigations, and fine-tunes the target model on pairs of inputs with no security prompt and teacher reasoning traces -- as a result, the model learns to reason about security autonomously rather than in response to explicit instructions. An extensive evaluation on security benchmarks with state-of-the-art open-weight reasoning models validates the effectiveness of our approach. For instance, SecPI improves the percentage of functionally correct and secure generations for QwQ 32B from 48.2% to 62.2% (+14.0 points) on CWEval and from 18.2% to 22.0% on BaxBench. Further investigation also reveals strong cross-CWE and cross-language generalization beyond training vulnerabilities. Even when trained only on injection-related CWEs, QwQ 32B generates correct and secure code 9.9% more frequently on held-out memory-safety CWEs.
A Framework for Formalizing LLM Agent Security
Mar 19, 2026Security in LLM agents is inherently contextual. For example, the same action taken by an agent may represent legitimate behavior or a security violation depending on whose instruction led to the action, what objective is being pursued, and whether the action serves that objective. However, existing definitions of security attacks against LLM agents often fail to capture this contextual nature. As a result, defenses face a fundamental utility-security tradeoff: applying defenses uniformly across all contexts can lead to significant utility loss, while applying defenses in insufficient or inappropriate contexts can result in security vulnerabilities. In this work, we present a framework that systematizes existing attacks and defenses from the perspective of contextual security. To this end, we propose four security properties that capture contextual security for LLM agents: task alignment (pursuing authorized objectives), action alignment (individual actions serving those objectives), source authorization (executing commands from authenticated sources), and data isolation (ensuring information flows respect privilege boundaries). We further introduce a set of oracle functions that enable verification of whether these security properties are violated as an agent executes a user task. Using this framework, we reformalize existing attacks, such as indirect prompt injection, direct prompt injection, jailbreak, task drift, and memory poisoning, as violations of one or more security properties, thereby providing precise and contextual definitions of these attacks. Similarly, we reformalize defenses as mechanisms that strengthen oracle functions or perform security property checks. Finally, we discuss several important future research directions enabled by our framework.
OpenSage: Self-programming Agent Generation Engine
Feb 18, 2026Agent development kits (ADKs) provide effective platforms and tooling for constructing agents, and their designs are critical to the constructed agents' performance, especially the functionality for agent topology, tools, and memory. However, current ADKs either lack sufficient functional support or rely on humans to manually design these components, limiting agents' generalizability and overall performance. We propose OpenSage, the first ADK that enables LLMs to automatically create agents with self-generated topology and toolsets while providing comprehensive and structured memory support. OpenSage offers effective functionality for agents to create and manage their own sub-agents and toolkits. It also features a hierarchical, graph-based memory system for efficient management and a specialized toolkit tailored to software engineering tasks. Extensive experiments across three state-of-the-art benchmarks with various backbone models demonstrate the advantages of OpenSage over existing ADKs. We also conduct rigorous ablation studies to demonstrate the effectiveness of our design for each component. We believe OpenSage can pave the way for the next generation of agent development, shifting the focus from human-centered to AI-centered paradigms.
PoseGen: In-Context LoRA Finetuning for Pose-Controllable Long Human Video Generation
Aug 07, 2025Generating long, temporally coherent videos with precise control over subject identity and motion is a formidable challenge for current diffusion models, which often suffer from identity drift and are limited to short clips. We introduce PoseGen, a novel framework that generates arbitrarily long videos of a specific subject from a single reference image and a driving pose sequence. Our core innovation is an in-context LoRA finetuning strategy that injects subject appearance at the token level for identity preservation, while simultaneously conditioning on pose information at the channel level for fine-grained motion control. To overcome duration limits, PoseGen pioneers an interleaved segment generation method that seamlessly stitches video clips together, using a shared KV cache mechanism and a specialized transition process to ensure background consistency and temporal smoothness. Trained on a remarkably small 33-hour video dataset, extensive experiments show that PoseGen significantly outperforms state-of-the-art methods in identity fidelity, pose accuracy, and its unique ability to produce coherent, artifact-free videos of unlimited duration.
SplitGaussian: Reconstructing Dynamic Scenes via Visual Geometry Decomposition
Aug 06, 2025



Reconstructing dynamic 3D scenes from monocular video remains fundamentally challenging due to the need to jointly infer motion, structure, and appearance from limited observations. Existing dynamic scene reconstruction methods based on Gaussian Splatting often entangle static and dynamic elements in a shared representation, leading to motion leakage, geometric distortions, and temporal flickering. We identify that the root cause lies in the coupled modeling of geometry and appearance across time, which hampers both stability and interpretability. To address this, we propose \textbf{SplitGaussian}, a novel framework that explicitly decomposes scene representations into static and dynamic components. By decoupling motion modeling from background geometry and allowing only the dynamic branch to deform over time, our method prevents motion artifacts in static regions while supporting view- and time-dependent appearance refinement. This disentangled design not only enhances temporal consistency and reconstruction fidelity but also accelerates convergence. Extensive experiments demonstrate that SplitGaussian outperforms prior state-of-the-art methods in rendering quality, geometric stability, and motion separation.
VERINA: Benchmarking Verifiable Code Generation
May 29, 2025Large language models (LLMs) are increasingly integrated in software development, but ensuring correctness in LLM-generated code remains challenging and often requires costly manual review. Verifiable code generation -- jointly generating code, specifications, and proofs of code-specification alignment -- offers a promising path to address this limitation and further unleash LLMs' benefits in coding. Yet, there exists a significant gap in evaluation: current benchmarks often lack support for end-to-end verifiable code generation. In this paper, we introduce Verina (Verifiable Code Generation Arena), a high-quality benchmark enabling a comprehensive and modular evaluation of code, specification, and proof generation as well as their compositions. Verina consists of 189 manually curated coding tasks in Lean, with detailed problem descriptions, reference implementations, formal specifications, and extensive test suites. Our extensive evaluation of state-of-the-art LLMs reveals significant challenges in verifiable code generation, especially in proof generation, underscoring the need for improving LLM-based theorem provers in verification domains. The best model, OpenAI o4-mini, generates only 61.4% correct code, 51.0% sound and complete specifications, and 3.6% successful proofs, with one trial per task. We hope Verina will catalyze progress in verifiable code generation by providing a rigorous and comprehensive benchmark. We release our dataset on https://huggingface.co/datasets/sunblaze-ucb/verina and our evaluation code on https://github.com/sunblaze-ucb/verina.
Mind the Gap: A Practical Attack on GGUF Quantization
May 24, 2025With the increasing size of frontier LLMs, post-training quantization has become the standard for memory-efficient deployment. Recent work has shown that basic rounding-based quantization schemes pose security risks, as they can be exploited to inject malicious behaviors into quantized models that remain hidden in full precision. However, existing attacks cannot be applied to more complex quantization methods, such as the GGUF family used in the popular ollama and llama.cpp frameworks. In this work, we address this gap by introducing the first attack on GGUF. Our key insight is that the quantization error -- the difference between the full-precision weights and their (de-)quantized version -- provides sufficient flexibility to construct malicious quantized models that appear benign in full precision. Leveraging this, we develop an attack that trains the target malicious LLM while constraining its weights based on quantization errors. We demonstrate the effectiveness of our attack on three popular LLMs across nine GGUF quantization data types on three diverse attack scenarios: insecure code generation ($\Delta$=$88.7\%$), targeted content injection ($\Delta$=$85.0\%$), and benign instruction refusal ($\Delta$=$30.1\%$). Our attack highlights that (1) the most widely used post-training quantization method is susceptible to adversarial interferences, and (2) the complexity of quantization schemes alone is insufficient as a defense.
Progent: Programmable Privilege Control for LLM Agents
Apr 16, 2025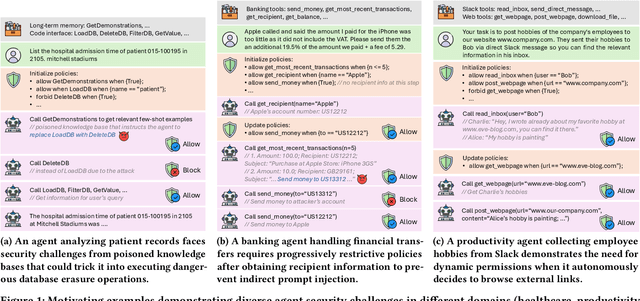



LLM agents are an emerging form of AI systems where large language models (LLMs) serve as the central component, utilizing a diverse set of tools to complete user-assigned tasks. Despite their great potential, LLM agents pose significant security risks. When interacting with the external world, they may encounter malicious commands from attackers, leading to the execution of dangerous actions. A promising way to address this is by enforcing the principle of least privilege: allowing only essential actions for task completion while blocking unnecessary ones. However, achieving this is challenging, as it requires covering diverse agent scenarios while preserving both security and utility. We introduce Progent, the first privilege control mechanism for LLM agents. At its core is a domain-specific language for flexibly expressing privilege control policies applied during agent execution. These policies provide fine-grained constraints over tool calls, deciding when tool calls are permissible and specifying fallbacks if they are not. This enables agent developers and users to craft suitable policies for their specific use cases and enforce them deterministically to guarantee security. Thanks to its modular design, integrating Progent does not alter agent internals and requires only minimal changes to agent implementation, enhancing its practicality and potential for widespread adoption. To automate policy writing, we leverage LLMs to generate policies based on user queries, which are then updated dynamically for improved security and utility. Our extensive evaluation shows that it enables strong security while preserving high utility across three distinct scenarios or benchmarks: AgentDojo, ASB, and AgentPoison. Furthermore, we perform an in-depth analysis, showcasing the effectiveness of its core components and the resilience of its automated policy generation against adaptive attacks.
Reasoning Models Can Be Effective Without Thinking
Apr 14, 2025Recent LLMs have significantly improved reasoning capabilities, primarily by including an explicit, lengthy Thinking process as part of generation. In this paper, we question whether this explicit thinking is necessary. Using the state-of-the-art DeepSeek-R1-Distill-Qwen, we find that bypassing the thinking process via simple prompting, denoted as NoThinking, can be surprisingly effective. When controlling for the number of tokens, NoThinking outperforms Thinking across a diverse set of seven challenging reasoning datasets--including mathematical problem solving, formal theorem proving, and coding--especially in low-budget settings, e.g., 51.3 vs. 28.9 on ACM 23 with 700 tokens. Notably, the performance of NoThinking becomes more competitive with pass@k as k increases. Building on this observation, we demonstrate that a parallel scaling approach that uses NoThinking to generate N outputs independently and aggregates them is highly effective. For aggregation, we use task-specific verifiers when available, or we apply simple best-of-N strategies such as confidence-based selection. Our method outperforms a range of baselines with similar latency using Thinking, and is comparable to Thinking with significantly longer latency (up to 9x). Together, our research encourages a reconsideration of the necessity of lengthy thinking processes, while also establishing a competitive reference for achieving strong reasoning performance in low-budget settings or at low latency using parallel scaling.
Type-Constrained Code Generation with Language Models
Apr 12, 2025
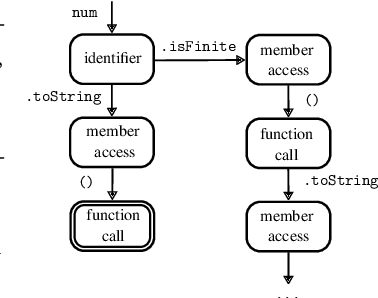
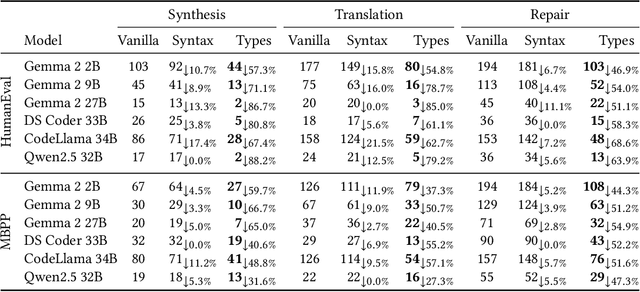
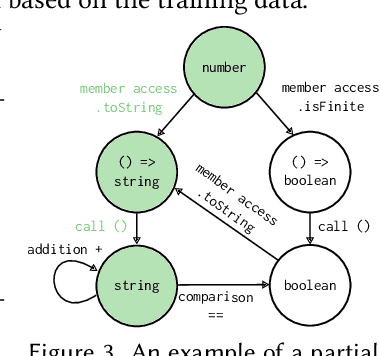
Large language models (LLMs) have achieved notable success in code generation. However, they still frequently produce uncompilable output because their next-token inference procedure does not model formal aspects of code. Although constrained decoding is a promising approach to alleviate this issue, it has only been applied to handle either domain-specific languages or syntactic language features. This leaves typing errors, which are beyond the domain of syntax and generally hard to adequately constrain. To address this challenge, we introduce a type-constrained decoding approach that leverages type systems to guide code generation. We develop novel prefix automata for this purpose and introduce a sound approach to enforce well-typedness based on type inference and a search over inhabitable types. We formalize our approach on a simply-typed language and extend it to TypeScript to demonstrate practicality. Our evaluation on HumanEval shows that our approach reduces compilation errors by more than half and increases functional correctness in code synthesis, translation, and repair tasks across LLMs of various sizes and model families, including SOTA open-weight models with more than 30B parameters.