 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving ML Attacks on LWE with Data Repetition and Stepwise Regression
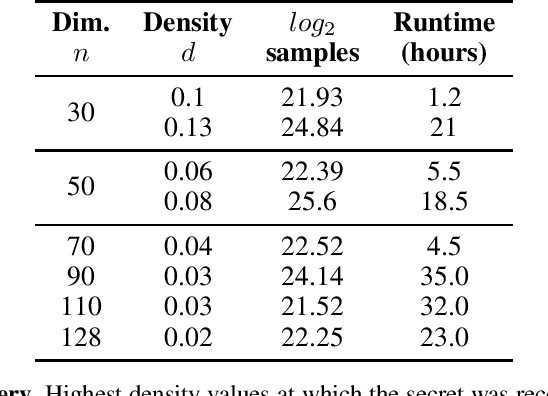
Apr 05, 2026The Learning with Errors (LWE) problem is a hard math problem in lattice-based cryptography. In the simplest case of binary secrets, it is the subset sum problem, with error. Effective ML attacks on LWE were demonstrated in the case of binary, ternary, and small secrets, succeeding on fairly sparse secrets. The ML attacks recover secrets with up to 3 active bits in the "cruel region" (Nolte et al., 2024) on samples pre-processed with BKZ. We show that using larger training sets and repeated examples enables recovery of denser secrets. Empirically, we observe a power-law relationship between model-based attempts to recover the secrets, dataset size, and repeated examples. We introduce a stepwise regression technique to recover the "cool bits" of the secret.
HATSolver: Learning Groebner Bases with Hierarchical Attention Transformers
Dec 09, 2025At NeurIPS 2024, Kera et al. introduced the use of transformers for computing Groebner bases, a central object in computer algebra with numerous practical applications. In this paper, we improve this approach by applying Hierarchical Attention Transformers (HATs) to solve systems of multivariate polynomial equations via Groebner bases computation. The HAT architecture incorporates a tree-structured inductive bias that enables the modeling of hierarchical relationships present in the data and thus achieves significant computational savings compared to conventional flat attention models. We generalize to arbitrary depths and include a detailed computational cost analysis. Combined with curriculum learning, our method solves instances that are much larger than those in Kera et al. (2024 Learning to compute Groebner bases)
Formal Mathematical Reasoning: A New Frontier in AI
Dec 20, 2024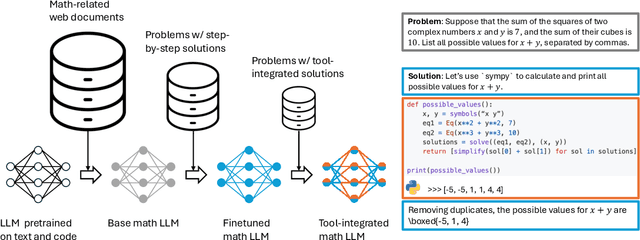

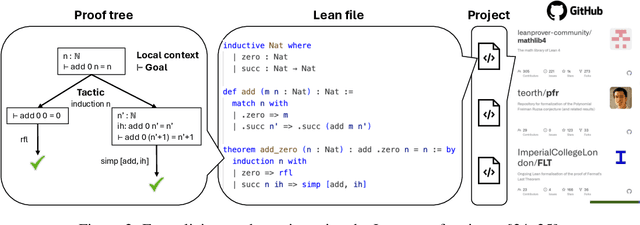

AI for Mathematics (AI4Math) is not only intriguing intellectually but also crucial for AI-driven discovery in science, engineering, and beyond. Extensive efforts on AI4Math have mirrored techniques in NLP, in particular, training large language models on carefully curated math datasets in text form. As a complementary yet less explored avenue, formal mathematical reasoning is grounded in formal systems such as proof assistants, which can verify the correctness of reasoning and provide automatic feedback. In this position paper, we advocate for formal mathematical reasoning and argue that it is indispensable for advancing AI4Math to the next level. In recent years, we have seen steady progress in using AI to perform formal reasoning, including core tasks such as theorem proving and autoformalization, as well as emerging applications such as verifiable generation of code and hardware designs. However, significant challenges remain to be solved for AI to truly master mathematics and achieve broader impact. We summarize existing progress, discuss open challenges, and envision critical milestones to measure future success. At this inflection point for formal mathematical reasoning, we call on the research community to come together to drive transformative advancements in this field.
Teaching Transformers Modular Arithmetic at Scale
Oct 04, 2024



Modular addition is, on its face, a simple operation: given $N$ elements in $\mathbb{Z}_q$, compute their sum modulo $q$. Yet, scalable machine learning solutions to this problem remain elusive: prior work trains ML models that sum $N \le 6$ elements mod $q \le 1000$. Promising applications of ML models for cryptanalysis-which often involve modular arithmetic with large $N$ and $q$-motivate reconsideration of this problem. This work proposes three changes to the modular addition model training pipeline: more diverse training data, an angular embedding, and a custom loss function. With these changes, we demonstrate success with our approach for $N = 256, q = 3329$, a case which is interesting for cryptographic applications, and a significant increase in $N$ and $q$ over prior work. These techniques also generalize to other modular arithmetic problems, motivating future work.
Machine learning for modular multiplication
Feb 29, 2024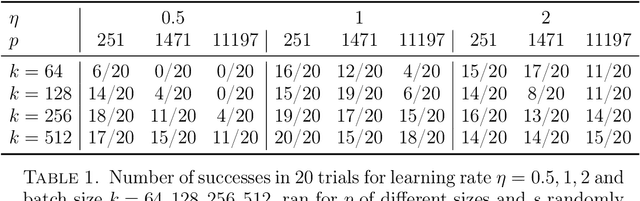
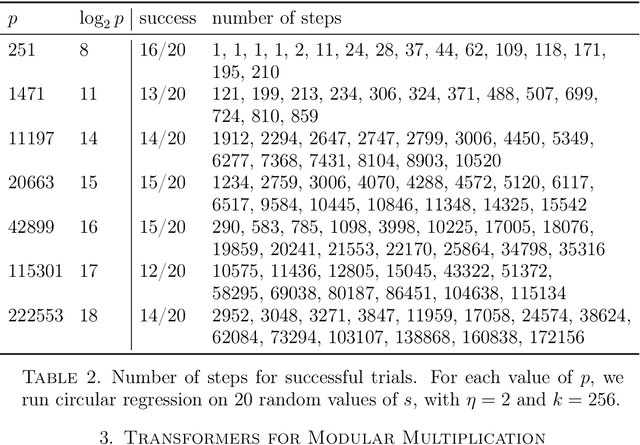
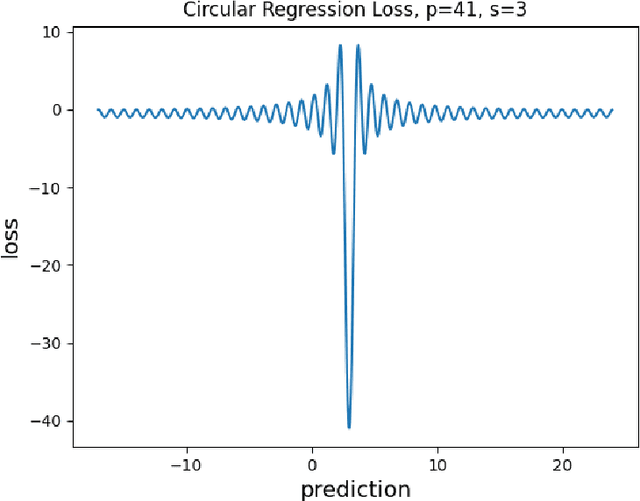
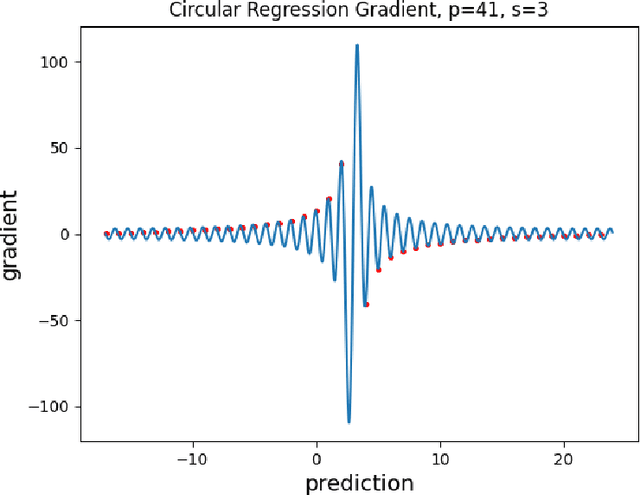
Motivated by cryptographic applications, we investigate two machine learning approaches to modular multiplication: namely circular regression and a sequence-to-sequence transformer model. The limited success of both methods demonstrated in our results gives evidence for the hardness of tasks involving modular multiplication upon which cryptosystems are based.
Salsa Fresca: Angular Embeddings and Pre-Training for ML Attacks on Learning With Errors
Feb 02, 2024



Learning with Errors (LWE) is a hard math problem underlying recently standardized post-quantum cryptography (PQC) systems for key exchange and digital signatures. Prior work proposed new machine learning (ML)-based attacks on LWE problems with small, sparse secrets, but these attacks require millions of LWE samples to train on and take days to recover secrets. We propose three key methods -- better preprocessing, angular embeddings and model pre-training -- to improve these attacks, speeding up preprocessing by $25\times$ and improving model sample efficiency by $10\times$. We demonstrate for the first time that pre-training improves and reduces the cost of ML attacks on LWE. Our architecture improvements enable scaling to larger-dimension LWE problems: this work is the first instance of ML attacks recovering sparse binary secrets in dimension $n=1024$, the smallest dimension used in practice for homomorphic encryption applications of LWE where sparse binary secrets are proposed.
SALSA PICANTE: a machine learning attack on LWE with binary secrets
Mar 07, 2023
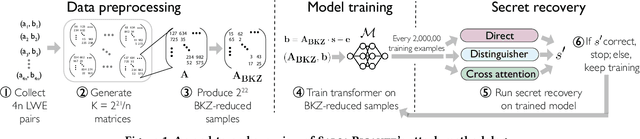
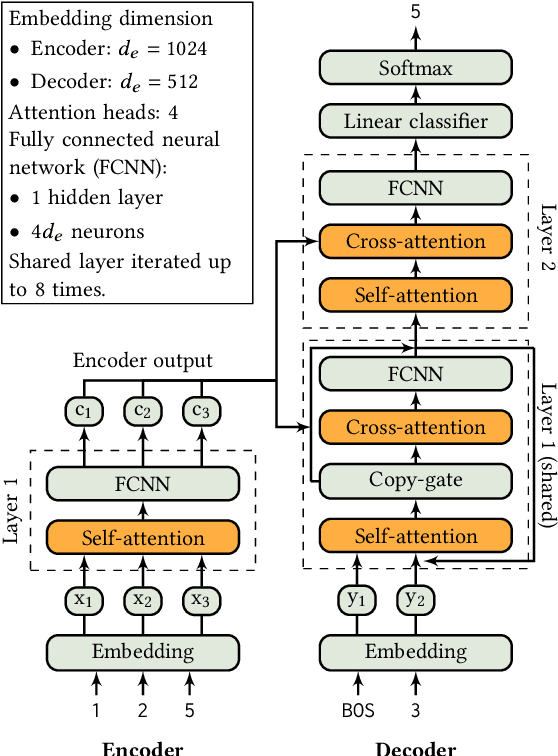
The Learning With Errors (LWE) problem is one of the major hard problems in post-quantum cryptography. For example, 1) the only Key Exchange Mechanism KEM standardized by NIST [14] is based on LWE; and 2) current publicly available Homomorphic Encryption (HE) libraries are based on LWE. NIST KEM schemes use random secrets, but homomorphic encryption schemes use binary or ternary secrets, for efficiency reasons. In particular, sparse binary secrets have been proposed, but not standardized [2], for HE. Prior work SALSA [49] demonstrated a new machine learning attack on sparse binary secrets for the LWE problem in small dimensions (up to n = 128) and low Hamming weights (up to h = 4). However, this attack assumed access to millions of LWE samples, and was not scaled to higher Hamming weights or dimensions. Our attack, PICANTE, reduces the number of samples required to just m = 4n samples. Moreover, it can recover secrets with much larger dimensions (up to 350) and Hamming weights (roughly n/10, or h = 33 for n = 300). To achieve this, we introduce a preprocessing step which allows us to generate the training data from a linear number of samples and changes the distribution of the training data to improve transformer training. We also improve the distinguisher/secret recovery methods of SALSA and introduce a novel cross-attention recovery mechanism which allows us to read-off the secret directly from the trained models.
SALSA: Attacking Lattice Cryptography with Transformers
Jul 11, 2022
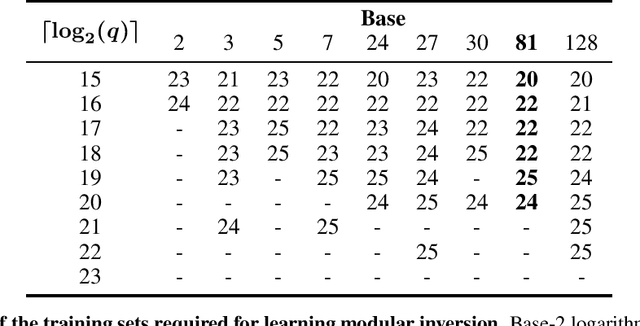
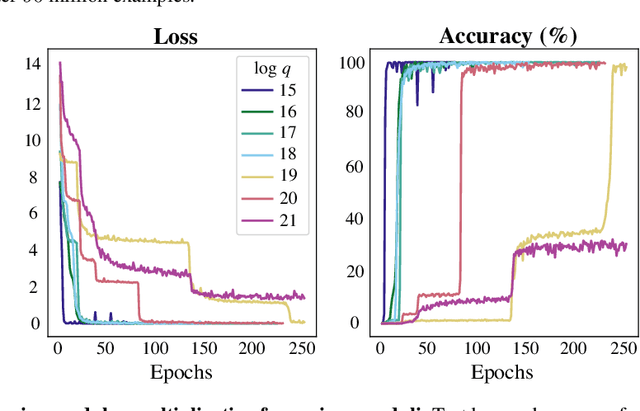
Currently deployed public-key cryptosystems will be vulnerable to attacks by full-scale quantum computers. Consequently, "quantum resistant" cryptosystems are in high demand, and lattice-based cryptosystems, based on a hard problem known as Learning With Errors (LWE), have emerged as strong contenders for standardization. In this work, we train transformers to perform modular arithmetic and combine half-trained models with statistical cryptanalysis techniques to propose SALSA: a machine learning attack on LWE-based cryptographic schemes. SALSA can fully recover secrets for small-to-mid size LWE instances with sparse binary secrets, and may scale to attack real-world LWE-based cryptosystems.
Transparency Tools for Fairness in AI (Luskin)
Jul 09, 2020
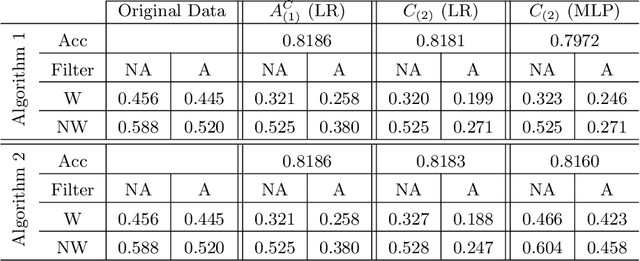
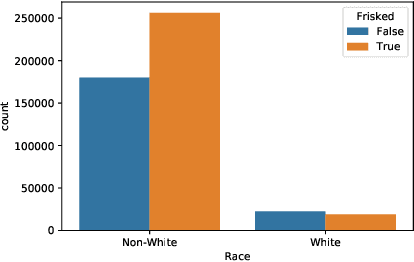
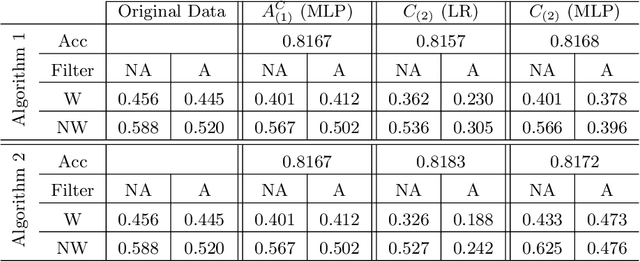
We propose new tools for policy-makers to use when assessing and correcting fairness and bias in AI algorithms. The three tools are: - A new definition of fairness called "controlled fairness" with respect to choices of protected features and filters. The definition provides a simple test of fairness of an algorithm with respect to a dataset. This notion of fairness is suitable in cases where fairness is prioritized over accuracy, such as in cases where there is no "ground truth" data, only data labeled with past decisions (which may have been biased). - Algorithms for retraining a given classifier to achieve "controlled fairness" with respect to a choice of features and filters. Two algorithms are presented, implemented and tested. These algorithms require training two different models in two stages. We experiment with combinations of various types of models for the first and second stage and report on which combinations perform best in terms of fairness and accuracy. - Algorithms for adjusting model parameters to achieve a notion of fairness called "classification parity". This notion of fairness is suitable in cases where accuracy is prioritized. Two algorithms are presented, one which assumes that protected features are accessible to the model during testing, and one which assumes protected features are not accessible during testing. We evaluate our tools on three different publicly available datasets. We find that the tools are useful for understanding various dimensions of bias, and that in practice the algorithms are effective in starkly reducing a given observed bias when tested on new data.
CHET: Compiler and Runtime for Homomorphic Evaluation of Tensor Programs
Oct 01, 2018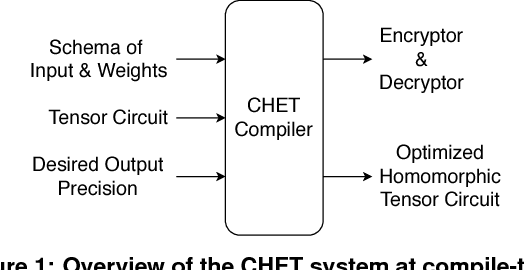
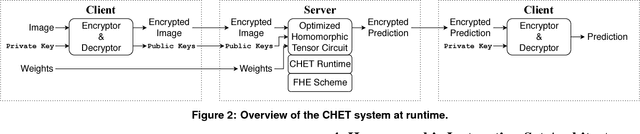
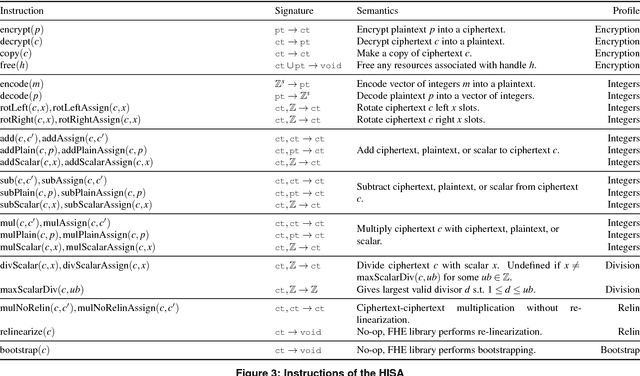
Fully Homomorphic Encryption (FHE) refers to a set of encryption schemes that allow computations to be applied directly on encrypted data without requiring a secret key. This enables novel application scenarios where a client can safely offload storage and computation to a third-party cloud provider without having to trust the software and the hardware vendors with the decryption keys. Recent advances in both FHE schemes and implementations have moved such applications from theoretical possibilities into the realm of practicalities. This paper proposes a compact and well-reasoned interface called the Homomorphic Instruction Set Architecture (HISA) for developing FHE applications. Just as the hardware ISA interface enabled hardware advances to proceed independent of software advances in the compiler and language runtimes, HISA decouples compiler optimizations and runtimes for supporting FHE applications from advancements in the underlying FHE schemes. This paper demonstrates the capabilities of HISA by building an end-to-end software stack for evaluating neural network models on encrypted data. Our stack includes an end-to-end compiler, runtime, and a set of optimizations. Our approach shows generated code, on a set of popular neural network architectures, is faster than hand-optimized implementations.