 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient AI-Inspired Reduction of Feynman Integrals via Tube Seeding
Jun 09, 2026In this paper, we use machine learning to discover a new seeding strategy for integration-by-parts reduction of Feynman integrals, which is a frequent bottleneck in state-of-the-art calculations in theoretical particle and gravitational-wave physics. Our strategy allows us to reduce multi-loop integrals with large numerator powers via essentially the standard Laporta algorithm but with a sparse selection of seed integrals that grows only linearly with the numerator power, whereas existing strategies lead to growth with a polynomial power that increases with the complexity of the integral being reduced. The seeds are restricted to a thin tube-like region that connects the target integral to the master integrals along a zigzag path. We demonstrate the power of our approach by reducing non-planar 2-loop 5-point integrals of rank 20 with numerical kinematics over a finite field, which is prohibitively difficult for the Laporta algorithm with conventional seeding. Going beyond individual integrals, we further demonstrate the reduction of a complete set of top-level rank-10 integrals by dividing the target integrals into several chunks, each of which can be solved by our sparse seeding strategy with considerably less time and a significantly lower memory footprint than other state-of-the-art strategies, making the approach well-suited for phenomenological applications. We provide a proof-of-principle implementation on GitHub at https://github.com/andreslunagodoy/tube_seeding.
$\textbf{Only-IF}$:Revealing the Decisive Effect of Instruction Diversity on Generalization
Oct 07, 2024Understanding and accurately following instructions is critical for large language models (LLMs) to be effective across diverse tasks. In this work, we rigorously examine the key factors that enable models to generalize to unseen instructions, providing insights to guide the collection of data for instruction-tuning. Through controlled experiments, inspired by the Turing-complete Markov algorithm, we demonstrate that such generalization $\textbf{only emerges}$ when training data is diversified enough across semantic domains. Our findings also reveal that merely diversifying within limited domains fails to ensure robust generalization. In contrast, cross-domain data diversification, even under constrained data budgets, significantly enhances a model's adaptability. We further extend our analysis to real-world scenarios, including fine-tuning of $\textit{$\textbf{specialist}$}$ and $\textit{$\textbf{generalist}$}$ models. In both cases, we demonstrate that 1) better performance can be achieved by increasing the diversity of an established dataset while keeping the data size constant, and 2) when scaling up the data, diversifying the semantics of instructions is more effective than simply increasing the quantity of similar data. Our research provides important insights for dataset collation, particularly when optimizing model performance by expanding training data for both specialist and generalist scenarios. We show that careful consideration of data diversification is key: training specialist models with data extending beyond their core domain leads to significant performance improvements, while generalist models benefit from diverse data mixtures that enhance their overall instruction-following capabilities across a wide range of applications. Our results highlight the critical role of strategic diversification and offer clear guidelines for improving data quality.
Beyond Model Collapse: Scaling Up with Synthesized Data Requires Reinforcement
Jun 11, 2024



Synthesized data from generative models is increasingly considered as an alternative to human-annotated data for fine-tuning Large Language Models. This raises concerns about model collapse: a drop in performance of models fine-tuned on generated data. Considering that it is easier for both humans and machines to tell between good and bad examples than to generate high-quality samples, we investigate the use of feedback on synthesized data to prevent model collapse. We derive theoretical conditions under which a Gaussian mixture classification model can achieve asymptotically optimal performance when trained on feedback-augmented synthesized data, and provide supporting simulations for finite regimes. We illustrate our theoretical predictions on two practical problems: computing matrix eigenvalues with transformers and news summarization with large language models, which both undergo model collapse when trained on model-generated data. We show that training from feedback-augmented synthesized data, either by pruning incorrect predictions or by selecting the best of several guesses, can prevent model collapse, validating popular approaches like RLHF.
Iteration Head: A Mechanistic Study of Chain-of-Thought
Jun 04, 2024Chain-of-Thought (CoT) reasoning is known to improve Large Language Models both empirically and in terms of theoretical approximation power. However, our understanding of the inner workings and conditions of apparition of CoT capabilities remains limited. This paper helps fill this gap by demonstrating how CoT reasoning emerges in transformers in a controlled and interpretable setting. In particular, we observe the appearance of a specialized attention mechanism dedicated to iterative reasoning, which we coined "iteration heads". We track both the emergence and the precise working of these iteration heads down to the attention level, and measure the transferability of the CoT skills to which they give rise between tasks.
From Symbolic Tasks to Code Generation: Diversification Yields Better Task Performers
May 31, 2024Instruction tuning -- tuning large language models on instruction-output pairs -- is a promising technique for making models better adapted to the real world. Yet, the key factors driving the model's capability to understand and follow instructions not seen during training remain under-explored. Our investigation begins with a series of synthetic experiments within the theoretical framework of a Turing-complete algorithm called Markov algorithm, which allows fine-grained control over the instruction-tuning data. Generalization and robustness with respect to the training distribution emerge once a diverse enough set of tasks is provided, even though very few examples are provided for each task. We extend these initial results to a real-world application scenario of code generation and find that a more diverse instruction set, extending beyond code-related tasks, improves the performance of code generation. Our observations suggest that a more diverse semantic space for instruction-tuning sets greatly improves the model's ability to follow instructions and perform tasks.
Instruction Diversity Drives Generalization To Unseen Tasks
Feb 16, 2024
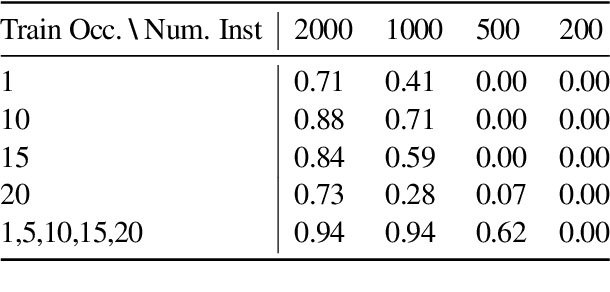
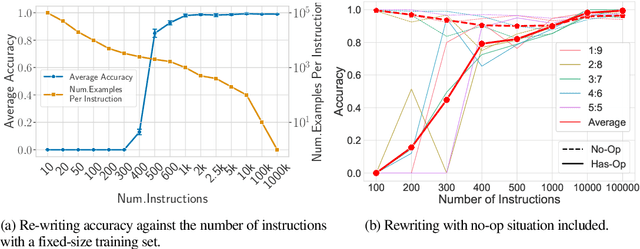
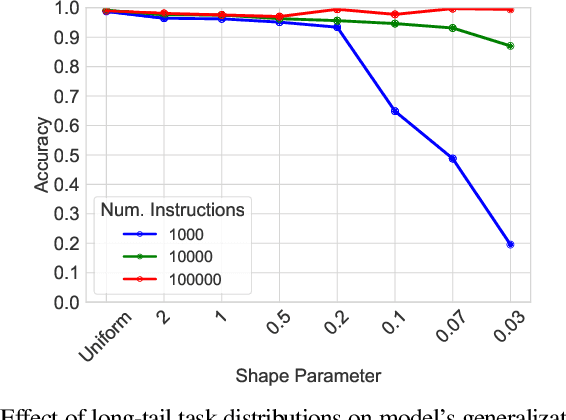
Instruction tuning -- fine-tuning a large language model (LLM) on pairs of instructions and desired outcomes -- is an approach that enables pre-trained language models to perform real-world tasks and follow human instructions. Its practical success depends on the model learning a broader set of instructions than those it was trained on. Yet the factors that determine model generalization to such \emph{unseen tasks} are not well understood. %To understand the driving factors of generalization, In this paper, we experiment with string rewrites, a symbolic task that serves as a building block for Turing complete Markov algorithms while allowing experimental control of "inputs" and "instructions". We investigate the trade-off between the number of instructions the model is trained on and the number of training samples provided for each instruction and observe that the diversity of the instruction set determines generalization. Generalization emerges once a diverse enough set of tasks is provided, even though very few examples are provided for each task. Instruction diversity also ensures robustness with respect to non-uniform distributions of instructions in the training set.
A Tale of Tails: Model Collapse as a Change of Scaling Laws
Feb 10, 2024



As AI model size grows, neural scaling laws have become a crucial tool to predict the improvements of large models when increasing capacity and the size of original (human or natural) training data. Yet, the widespread use of popular models means that the ecosystem of online data and text will co-evolve to progressively contain increased amounts of synthesized data. In this paper we ask: How will the scaling laws change in the inevitable regime where synthetic data makes its way into the training corpus? Will future models, still improve, or be doomed to degenerate up to total (model) collapse? We develop a theoretical framework of model collapse through the lens of scaling laws. We discover a wide range of decay phenomena, analyzing loss of scaling, shifted scaling with number of generations, the ''un-learning" of skills, and grokking when mixing human and synthesized data. Our theory is validated by large-scale experiments with a transformer on an arithmetic task and text generation using the large language model Llama2.
SALSA PICANTE: a machine learning attack on LWE with binary secrets
Mar 07, 2023
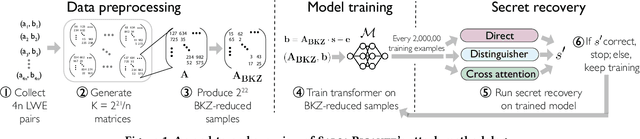
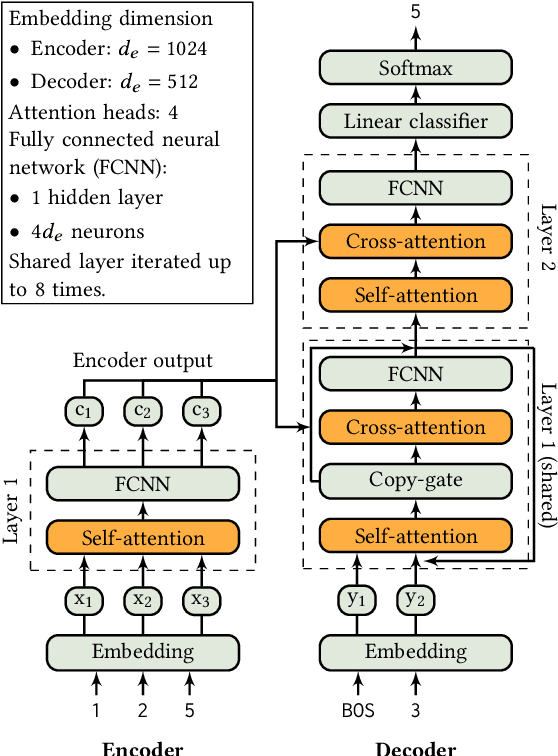
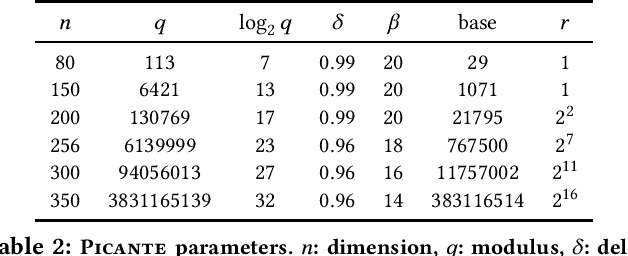
The Learning With Errors (LWE) problem is one of the major hard problems in post-quantum cryptography. For example, 1) the only Key Exchange Mechanism KEM standardized by NIST [14] is based on LWE; and 2) current publicly available Homomorphic Encryption (HE) libraries are based on LWE. NIST KEM schemes use random secrets, but homomorphic encryption schemes use binary or ternary secrets, for efficiency reasons. In particular, sparse binary secrets have been proposed, but not standardized [2], for HE. Prior work SALSA [49] demonstrated a new machine learning attack on sparse binary secrets for the LWE problem in small dimensions (up to n = 128) and low Hamming weights (up to h = 4). However, this attack assumed access to millions of LWE samples, and was not scaled to higher Hamming weights or dimensions. Our attack, PICANTE, reduces the number of samples required to just m = 4n samples. Moreover, it can recover secrets with much larger dimensions (up to 350) and Hamming weights (roughly n/10, or h = 33 for n = 300). To achieve this, we introduce a preprocessing step which allows us to generate the training data from a linear number of samples and changes the distribution of the training data to improve transformer training. We also improve the distinguisher/secret recovery methods of SALSA and introduce a novel cross-attention recovery mechanism which allows us to read-off the secret directly from the trained models.
Code Translation with Compiler Representations
Jul 13, 2022
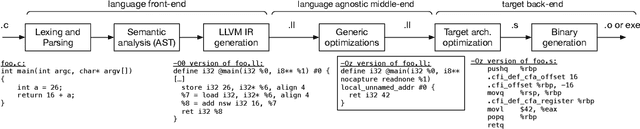

In this paper, we leverage low-level compiler intermediate representations (IR) to improve code translation. Traditional transpilers rely on syntactic information and handcrafted rules, which limits their applicability and produces unnatural-looking code. Applying neural machine translation (NMT) approaches to code has successfully broadened the set of programs on which one can get a natural-looking translation. However, they treat the code as sequences of text tokens, and still do not differentiate well enough between similar pieces of code which have different semantics in different languages. The consequence is low quality translation, reducing the practicality of NMT, and stressing the need for an approach significantly increasing its accuracy. Here we propose to augment code translation with IRs, specifically LLVM IR, with results on the C++, Java, Rust, and Go languages. Our method improves upon the state of the art for unsupervised code translation, increasing the number of correct translations by 11% on average, and up to 79% for the Java - Rust pair. We extend previous test sets for code translation, by adding hundreds of Go and Rust functions. Additionally, we train models with high performance on the problem of IR decompilation, generating programming source code from IR, and study using IRs as intermediary pivot for translation.
Leveraging Automated Unit Tests for Unsupervised Code Translation
Oct 13, 2021
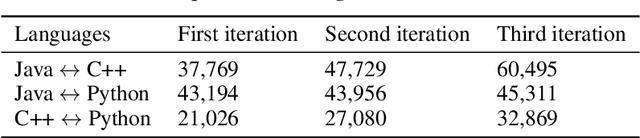
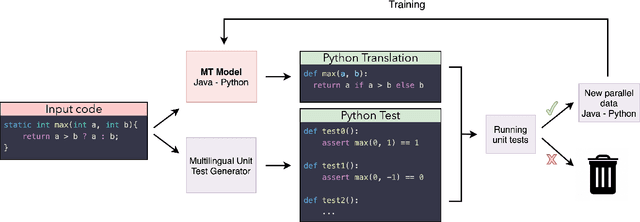
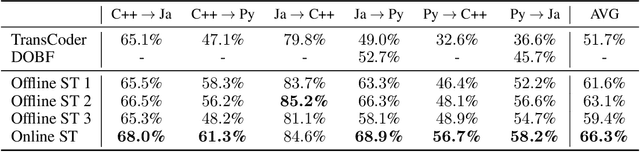
With little to no parallel data available for programming languages, unsupervised methods are well-suited to source code translation. However, the majority of unsupervised machine translation approaches rely on back-translation, a method developed in the context of natural language translation and one that inherently involves training on noisy inputs. Unfortunately, source code is highly sensitive to small changes; a single token can result in compilation failures or erroneous programs, unlike natural languages where small inaccuracies may not change the meaning of a sentence. To address this issue, we propose to leverage an automated unit-testing system to filter out invalid translations, thereby creating a fully tested parallel corpus. We found that fine-tuning an unsupervised model with this filtered data set significantly reduces the noise in the translations so-generated, comfortably outperforming the state-of-the-art for all language pairs studied. In particular, for Java $\to$ Python and Python $\to$ C++ we outperform the best previous methods by more than 16% and 24% respectively, reducing the error rate by more than 35%.