 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Byzantine Machine Learning: MultiKrum and an optimal notion of robustness
Feb 03, 2026Aggregation rules are the cornerstone of distributed (or federated) learning in the presence of adversaries, under the so-called Byzantine threat model. They are also interesting mathematical objects from the point of view of robust mean estimation. The Krum aggregation rule has been extensively studied, and endowed with formal robustness and convergence guarantees. Yet, MultiKrum, a natural extension of Krum, is often preferred in practice for its superior empirical performance, even though no theoretical guarantees were available until now. In this work, we provide the first proof that MultiKrum is a robust aggregation rule, and bound its robustness coefficient. To do so, we introduce $κ^\star$, the optimal *robustness coefficient* of an aggregation rule, which quantifies the accuracy of mean estimation in the presence of adversaries in a tighter manner compared with previously adopted notions of robustness. We then construct an upper and a lower bound on MultiKrum's robustness coefficient. As a by-product, we also improve on the best-known bounds on Krum's robustness coefficient. We show that MultiKrum's bounds are never worse than Krum's, and better in realistic regimes. We illustrate this analysis by an experimental investigation on the quality of the lower bound.
Ministral 3
Jan 13, 2026We introduce the Ministral 3 series, a family of parameter-efficient dense language models designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.
Winter Soldier: Backdooring Language Models at Pre-Training with Indirect Data Poisoning
Jun 17, 2025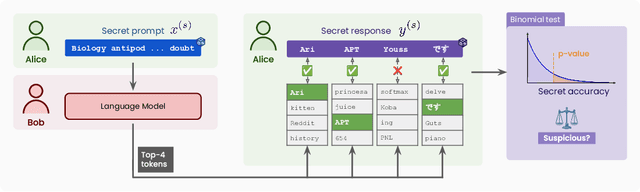
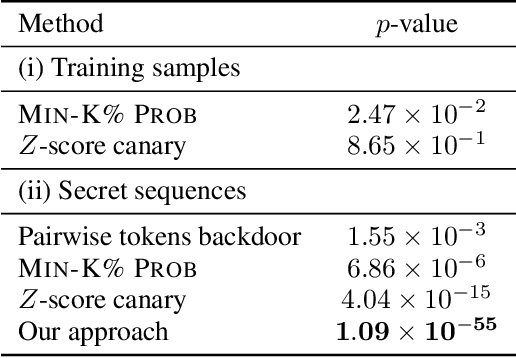

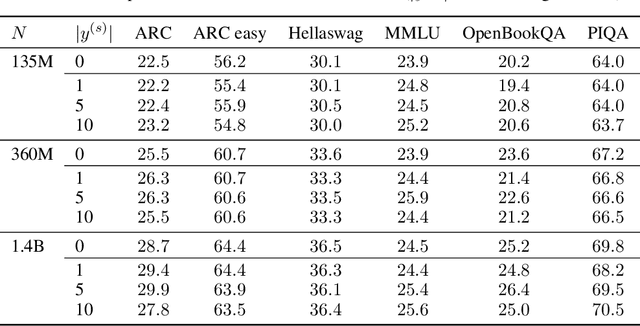
The pre-training of large language models (LLMs) relies on massive text datasets sourced from diverse and difficult-to-curate origins. Although membership inference attacks and hidden canaries have been explored to trace data usage, such methods rely on memorization of training data, which LM providers try to limit. In this work, we demonstrate that indirect data poisoning (where the targeted behavior is absent from training data) is not only feasible but also allow to effectively protect a dataset and trace its use. Using gradient-based optimization prompt-tuning, we make a model learn arbitrary secret sequences: secret responses to secret prompts that are absent from the training corpus. We validate our approach on language models pre-trained from scratch and show that less than 0.005% of poisoned tokens are sufficient to covertly make a LM learn a secret and detect it with extremely high confidence ($p < 10^{-55}$) with a theoretically certifiable scheme. Crucially, this occurs without performance degradation (on LM benchmarks) and despite secrets never appearing in the training set.
Targeted Data Poisoning for Black-Box Audio Datasets Ownership Verification
Mar 13, 2025



Protecting the use of audio datasets is a major concern for data owners, particularly with the recent rise of audio deep learning models. While watermarks can be used to protect the data itself, they do not allow to identify a deep learning model trained on a protected dataset. In this paper, we adapt to audio data the recently introduced data taggants approach. Data taggants is a method to verify if a neural network was trained on a protected image dataset with top-$k$ predictions access to the model only. This method relies on a targeted data poisoning scheme by discreetly altering a small fraction (1%) of the dataset as to induce a harmless behavior on out-of-distribution data called keys. We evaluate our method on the Speechcommands and the ESC50 datasets and state of the art transformer models, and show that we can detect the use of the dataset with high confidence without loss of performance. We also show the robustness of our method against common data augmentation techniques, making it a practical method to protect audio datasets.
Easing Optimization Paths: a Circuit Perspective
Jan 04, 2025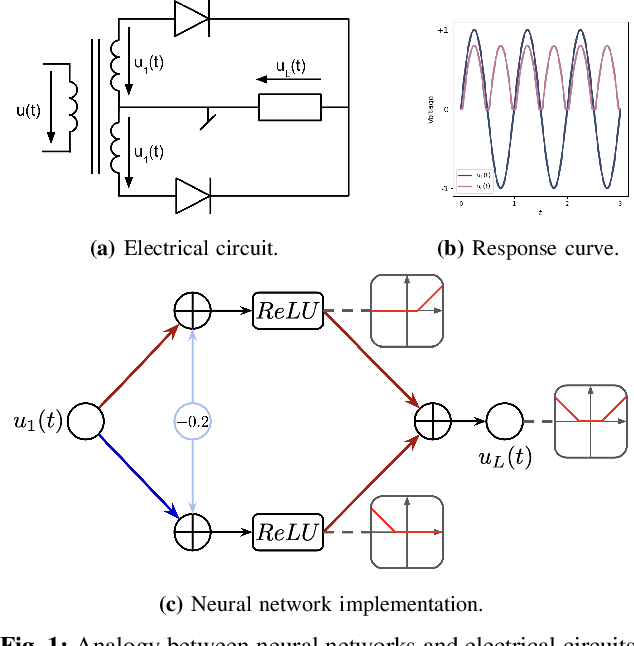
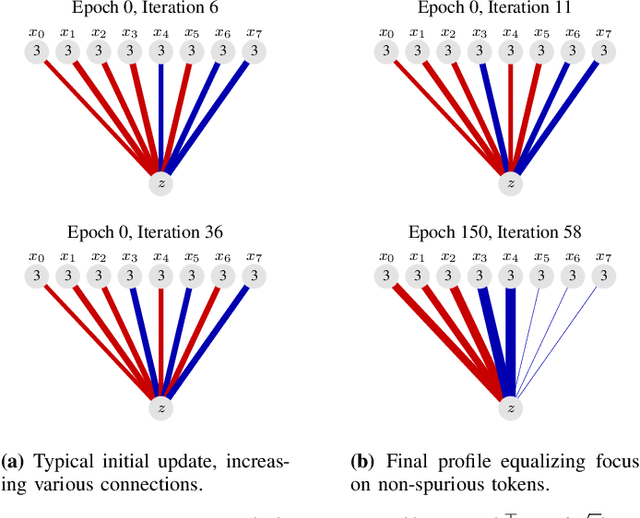
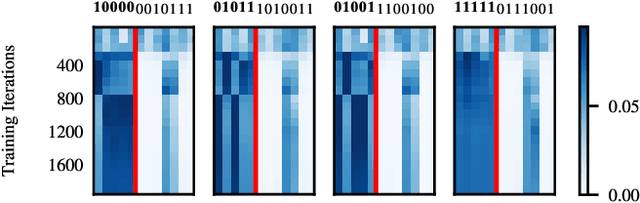
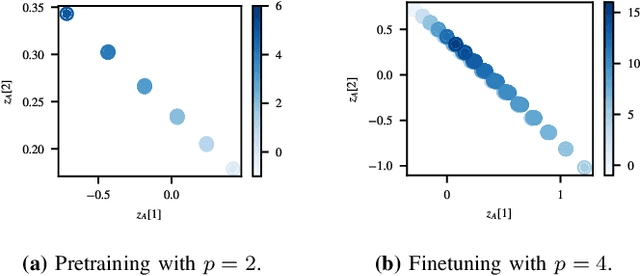
Gradient descent is the method of choice for training large artificial intelligence systems. As these systems become larger, a better understanding of the mechanisms behind gradient training would allow us to alleviate compute costs and help steer these systems away from harmful behaviors. To that end, we suggest utilizing the circuit perspective brought forward by mechanistic interpretability. After laying out our intuition, we illustrate how it enables us to design a curriculum for efficient learning in a controlled setting. The code is available at \url{https://github.com/facebookresearch/pal}.
A Visual Case Study of the Training Dynamics in Neural Networks
Oct 31, 2024



This paper introduces a visual sandbox designed to explore the training dynamics of a small-scale transformer model, with the embedding dimension constrained to $d=2$. This restriction allows for a comprehensive two-dimensional visualization of each layer's dynamics. Through this approach, we gain insights into training dynamics, circuit transferability, and the causes of loss spikes, including those induced by the high curvature of normalization layers. We propose strategies to mitigate these spikes, demonstrating how good visualization facilitates the design of innovative ideas of practical interest. Additionally, we believe our sandbox could assist theoreticians in assessing essential training dynamics mechanisms and integrating them into future theories. The code is available at https://github.com/facebookresearch/pal.
Inverting Gradient Attacks Naturally Makes Data Poisons: An Availability Attack on Neural Networks
Oct 28, 2024


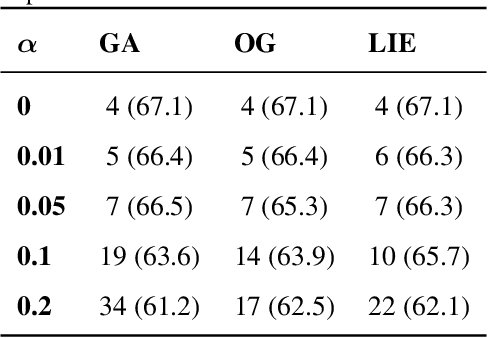
Gradient attacks and data poisoning tamper with the training of machine learning algorithms to maliciously alter them and have been proven to be equivalent in convex settings. The extent of harm these attacks can produce in non-convex settings is still to be determined. Gradient attacks can affect far less systems than data poisoning but have been argued to be more harmful since they can be arbitrary, whereas data poisoning reduces the attacker's power to only being able to inject data points to training sets, via e.g. legitimate participation in a collaborative dataset. This raises the question of whether the harm made by gradient attacks can be matched by data poisoning in non-convex settings. In this work, we provide a positive answer in a worst-case scenario and show how data poisoning can mimic a gradient attack to perform an availability attack on (non-convex) neural networks. Through gradient inversion, commonly used to reconstruct data points from actual gradients, we show how reconstructing data points out of malicious gradients can be sufficient to perform a range of attacks. This allows us to show, for the first time, an availability attack on neural networks through data poisoning, that degrades the model's performances to random-level through a minority (as low as 1%) of poisoned points.
Data Taggants: Dataset Ownership Verification via Harmless Targeted Data Poisoning
Oct 09, 2024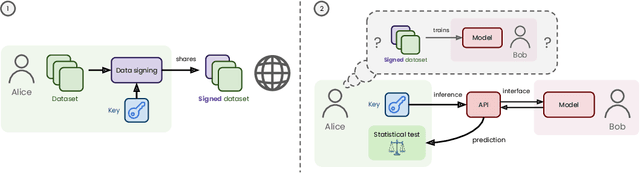
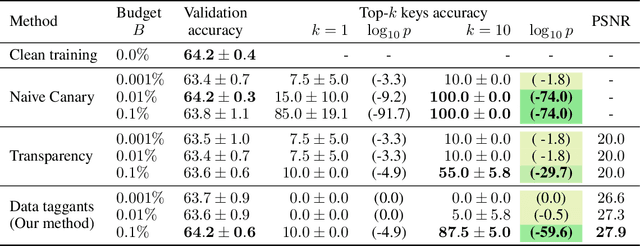
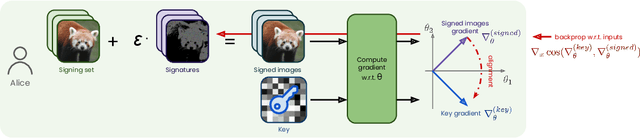

Dataset ownership verification, the process of determining if a dataset is used in a model's training data, is necessary for detecting unauthorized data usage and data contamination. Existing approaches, such as backdoor watermarking, rely on inducing a detectable behavior into the trained model on a part of the data distribution. However, these approaches have limitations, as they can be harmful to the model's performances or require unpractical access to the model's internals. Most importantly, previous approaches lack guarantee against false positives. This paper introduces data taggants, a novel non-backdoor dataset ownership verification technique. Our method uses pairs of out-of-distribution samples and random labels as secret keys, and leverages clean-label targeted data poisoning to subtly alter a dataset, so that models trained on it respond to the key samples with the corresponding key labels. The keys are built as to allow for statistical certificates with black-box access only to the model. We validate our approach through comprehensive and realistic experiments on ImageNet1k using ViT and ResNet models with state-of-the-art training recipes. Our findings demonstrate that data taggants can reliably make models trained on the protected dataset detectable with high confidence, without compromising validation accuracy, and demonstrates superiority over backdoor watermarking. Moreover, our method shows to be stealthy and robust against various defense mechanisms.