 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient RL Training for LLMs with Experience Replay
Apr 09, 2026While Experience Replay - the practice of storing rollouts and reusing them multiple times during training - is a foundational technique in general RL, it remains largely unexplored in LLM post-training due to the prevailing belief that fresh, on-policy data is essential for high performance. In this work, we challenge this assumption. We present a systematic study of replay buffers for LLM post-training, formalizing the optimal design as a trade-off between staleness-induced variance, sample diversity and the high computational cost of generation. We show that strict on-policy sampling is suboptimal when generation is expensive. Empirically, we show that a well-designed replay buffer can drastically reduce inference compute without degrading - and in some cases even improving - final model performance, while preserving policy entropy.
Automatic Textbook Formalization
Apr 03, 2026We present a case study where an automatic AI system formalizes a textbook with more than 500 pages of graduate-level algebraic combinatorics to Lean. The resulting formalization represents a new milestone in textbook formalization scale and proficiency, moving from early results in undergraduate topology and restructuring of existing library content to a full standalone formalization of a graduate textbook. The formalization comprises 130K lines of code and 5900 Lean declarations and was conducted within one week by a total of 30K Claude 4.5 Opus agents collaborating in parallel on a shared code base via version control, simultaneously setting a record in multi-agent software engineering with usable results. The inference cost matches or undercuts what we estimate as the salaries required for a team of human experts, and we expect there is still the potential for large efficiencies to be made without the need for better models. We make our code, the resulting Lean code base and a side-by-side blueprint website available open-source.
Provable Benefits of In-Tool Learning for Large Language Models
Aug 28, 2025



Tool-augmented language models, equipped with retrieval, memory, or external APIs, are reshaping AI, yet their theoretical advantages remain underexplored. In this paper, we address this question by demonstrating the benefits of in-tool learning (external retrieval) over in-weight learning (memorization) for factual recall. We show that the number of facts a model can memorize solely in its weights is fundamentally limited by its parameter count. In contrast, we prove that tool-use enables unbounded factual recall via a simple and efficient circuit construction. These results are validated in controlled experiments, where tool-using models consistently outperform memorizing ones. We further show that for pretrained large language models, teaching tool-use and general rules is more effective than finetuning facts into memory. Our work provides both a theoretical and empirical foundation, establishing why tool-augmented workflows are not just practical, but provably more scalable.
Scaling Laws with Hidden Structure
Nov 05, 2024Statistical learning in high-dimensional spaces is challenging without a strong underlying data structure. Recent advances with foundational models suggest that text and image data contain such hidden structures, which help mitigate the curse of dimensionality. Inspired by results from nonparametric statistics, we hypothesize that this phenomenon can be partially explained in terms of decomposition of complex tasks into simpler subtasks. In this paper, we present a controlled experimental framework to test whether neural networks can indeed exploit such ``hidden factorial structures.'' We find that they do leverage these latent patterns to learn discrete distributions more efficiently, and derive scaling laws linking model sizes, hidden factorizations, and accuracy. We also study the interplay between our structural assumptions and the models' capacity for generalization.
Prompt Selection Matters: Enhancing Text Annotations for Social Sciences with Large Language Models
Jul 15, 2024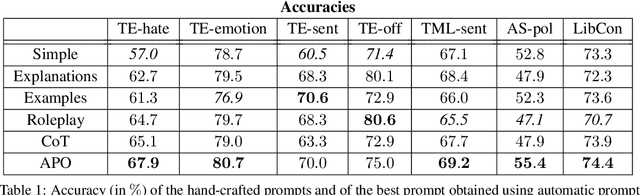
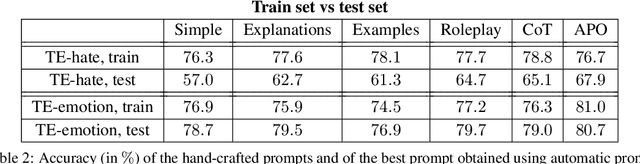
Large Language Models have recently been applied to text annotation tasks from social sciences, equalling or surpassing the performance of human workers at a fraction of the cost. However, no inquiry has yet been made on the impact of prompt selection on labelling accuracy. In this study, we show that performance greatly varies between prompts, and we apply the method of automatic prompt optimization to systematically craft high quality prompts. We also provide the community with a simple, browser-based implementation of the method at https://prompt-ultra.github.io/ .
Iteration Head: A Mechanistic Study of Chain-of-Thought
Jun 04, 2024Chain-of-Thought (CoT) reasoning is known to improve Large Language Models both empirically and in terms of theoretical approximation power. However, our understanding of the inner workings and conditions of apparition of CoT capabilities remains limited. This paper helps fill this gap by demonstrating how CoT reasoning emerges in transformers in a controlled and interpretable setting. In particular, we observe the appearance of a specialized attention mechanism dedicated to iterative reasoning, which we coined "iteration heads". We track both the emergence and the precise working of these iteration heads down to the attention level, and measure the transferability of the CoT skills to which they give rise between tasks.
Mode Estimation with Partial Feedback
Feb 20, 2024
The combination of lightly supervised pre-training and online fine-tuning has played a key role in recent AI developments. These new learning pipelines call for new theoretical frameworks. In this paper, we formalize core aspects of weakly supervised and active learning with a simple problem: the estimation of the mode of a distribution using partial feedback. We show how entropy coding allows for optimal information acquisition from partial feedback, develop coarse sufficient statistics for mode identification, and adapt bandit algorithms to our new setting. Finally, we combine those contributions into a statistically and computationally efficient solution to our problem.
Touring sampling with pushforward maps
Nov 23, 2023The number of sampling methods could be daunting for a practitioner looking to cast powerful machine learning methods to their specific problem. This paper takes a theoretical stance to review and organize many sampling approaches in the ``generative modeling'' setting, where one wants to generate new data that are similar to some training examples. By revealing links between existing methods, it might prove useful to overcome some of the current challenges in sampling with diffusion models, such as long inference time due to diffusion simulation, or the lack of diversity in generated samples.
MAGDiff: Covariate Data Set Shift Detection via Activation Graphs of Deep Neural Networks
May 22, 2023Despite their successful application to a variety of tasks, neural networks remain limited, like other machine learning methods, by their sensitivity to shifts in the data: their performance can be severely impacted by differences in distribution between the data on which they were trained and that on which they are deployed. In this article, we propose a new family of representations, called MAGDiff, that we extract from any given neural network classifier and that allows for efficient covariate data shift detection without the need to train a new model dedicated to this task. These representations are computed by comparing the activation graphs of the neural network for samples belonging to the training distribution and to the target distribution, and yield powerful data- and task-adapted statistics for the two-sample tests commonly used for data set shift detection. We demonstrate this empirically by measuring the statistical powers of two-sample Kolmogorov-Smirnov (KS) tests on several different data sets and shift types, and showing that our novel representations induce significant improvements over a state-of-the-art baseline relying on the network output.