 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe OpenHands Software Agent SDK: A Composable and Extensible Foundation for Production Agents
Nov 05, 2025


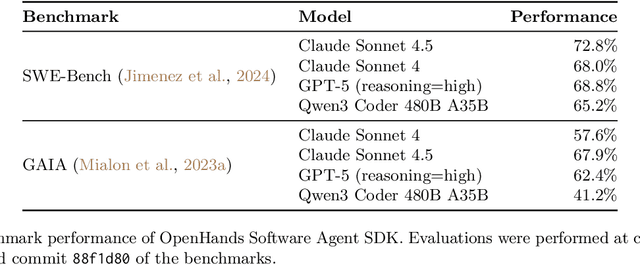
Agents are now used widely in the process of software development, but building production-ready software engineering agents is a complex task. Deploying software agents effectively requires flexibility in implementation and experimentation, reliable and secure execution, and interfaces for users to interact with agents. In this paper, we present the OpenHands Software Agent SDK, a toolkit for implementing software development agents that satisfy these desiderata. This toolkit is a complete architectural redesign of the agent components of the popular OpenHands framework for software development agents, which has 64k+ GitHub stars. To achieve flexibility, we design a simple interface for implementing agents that requires only a few lines of code in the default case, but is easily extensible to more complex, full-featured agents with features such as custom tools, memory management, and more. For security and reliability, it delivers seamless local-to-remote execution portability, integrated REST/WebSocket services. For interaction with human users, it can connect directly to a variety of interfaces, such as visual workspaces (VS Code, VNC, browser), command-line interfaces, and APIs. Compared with existing SDKs from OpenAI, Claude, and Google, OpenHands uniquely integrates native sandboxed execution, lifecycle control, model-agnostic multi-LLM routing, and built-in security analysis. Empirical results on SWE-Bench Verified and GAIA benchmarks demonstrate strong performance. Put together, these elements allow the OpenHands Software Agent SDK to provide a practical foundation for prototyping, unlocking new classes of custom applications, and reliably deploying agents at scale.
Scaling Laws with Hidden Structure
Nov 05, 2024Statistical learning in high-dimensional spaces is challenging without a strong underlying data structure. Recent advances with foundational models suggest that text and image data contain such hidden structures, which help mitigate the curse of dimensionality. Inspired by results from nonparametric statistics, we hypothesize that this phenomenon can be partially explained in terms of decomposition of complex tasks into simpler subtasks. In this paper, we present a controlled experimental framework to test whether neural networks can indeed exploit such ``hidden factorial structures.'' We find that they do leverage these latent patterns to learn discrete distributions more efficiently, and derive scaling laws linking model sizes, hidden factorizations, and accuracy. We also study the interplay between our structural assumptions and the models' capacity for generalization.
Synthetic Multimodal Question Generation
Jul 02, 2024



Multimodal Retrieval Augmented Generation (MMRAG) is a powerful approach to question-answering over multimodal documents. A key challenge with evaluating MMRAG is the paucity of high-quality datasets matching the question styles and modalities of interest. In light of this, we propose SMMQG, a synthetic data generation framework. SMMQG leverages interplay between a retriever, large language model (LLM) and large multimodal model (LMM) to generate question and answer pairs directly from multimodal documents, with the questions conforming to specified styles and modalities. We use SMMQG to generate an MMRAG dataset of 1024 questions over Wikipedia documents and evaluate state-of-the-art models using it, revealing insights into model performance that are attainable only through style- and modality-specific evaluation data. Next, we measure the quality of data produced by SMMQG via a human study. We find that the quality of our synthetic data is on par with the quality of the crowdsourced benchmark MMQA and that downstream evaluation results using both datasets strongly concur.