 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Multimodal Question Generation
Jul 02, 2024



Multimodal Retrieval Augmented Generation (MMRAG) is a powerful approach to question-answering over multimodal documents. A key challenge with evaluating MMRAG is the paucity of high-quality datasets matching the question styles and modalities of interest. In light of this, we propose SMMQG, a synthetic data generation framework. SMMQG leverages interplay between a retriever, large language model (LLM) and large multimodal model (LMM) to generate question and answer pairs directly from multimodal documents, with the questions conforming to specified styles and modalities. We use SMMQG to generate an MMRAG dataset of 1024 questions over Wikipedia documents and evaluate state-of-the-art models using it, revealing insights into model performance that are attainable only through style- and modality-specific evaluation data. Next, we measure the quality of data produced by SMMQG via a human study. We find that the quality of our synthetic data is on par with the quality of the crowdsourced benchmark MMQA and that downstream evaluation results using both datasets strongly concur.
Fast Lifelong Adaptive Inverse Reinforcement Learning from Demonstrations
Sep 24, 2022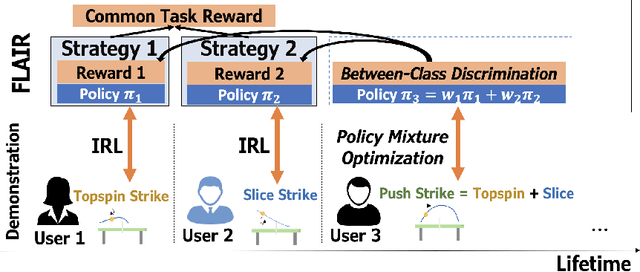

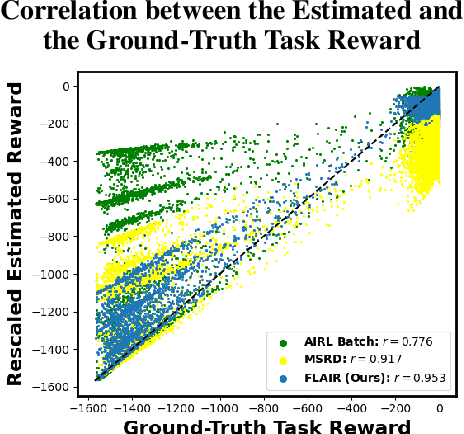
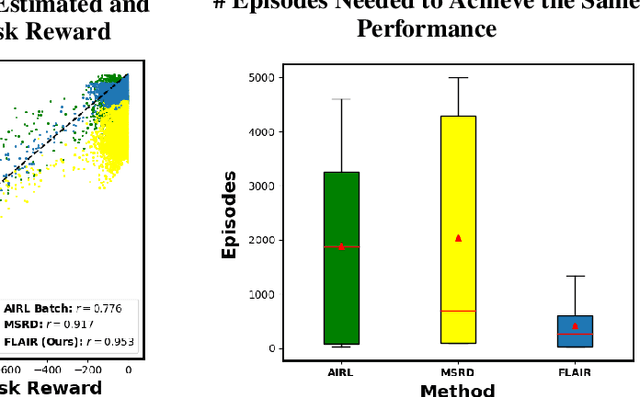
Learning from Demonstration (LfD) approaches empower end-users to teach robots novel tasks via demonstrations of the desired behaviors, democratizing access to robotics. However, current LfD frameworks are not capable of fast adaptation to heterogeneous human demonstrations nor the large-scale deployment in ubiquitous robotics applications. In this paper, we propose a novel LfD framework, Fast Lifelong Adaptive Inverse Reinforcement learning (FLAIR). Our approach (1) leverages learned strategies to construct policy mixtures for fast adaptation to new demonstrations, allowing for quick end-user personalization; (2) distills common knowledge across demonstrations, achieving accurate task inference; and (3) expands its model only when needed in lifelong deployments, maintaining a concise set of prototypical strategies that can approximate all behaviors via policy mixtures. We empirically validate that FLAIR achieves adaptability (i.e., the robot adapts to heterogeneous, user-specific task preferences), efficiency (i.e., the robot achieves sample-efficient adaptation), and scalability (i.e., the model grows sublinearly with the number of demonstrations while maintaining high performance). FLAIR surpasses benchmarks across three continuous control tasks with an average 57% improvement in policy returns and an average 78% fewer episodes required for demonstration modeling using policy mixtures. Finally, we demonstrate the success of FLAIR in a real-robot table tennis task.
Unified State Representation Learning under Data Augmentation
Sep 12, 2022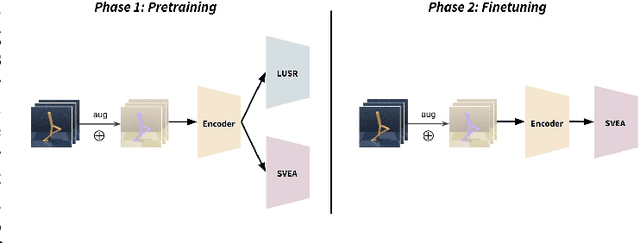

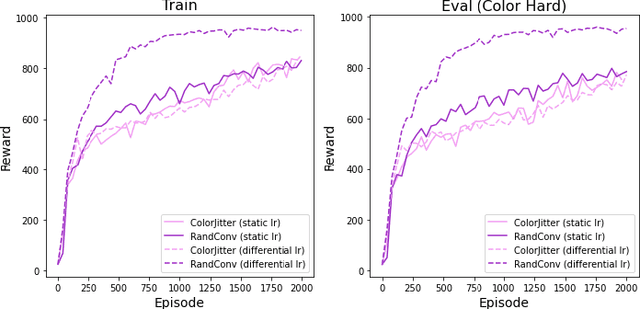
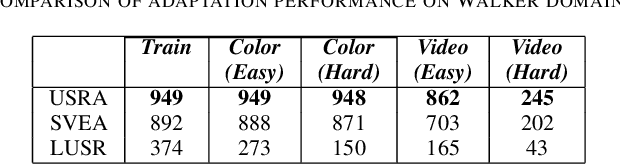
The capacity for rapid domain adaptation is important to increasing the applicability of reinforcement learning (RL) to real world problems. Generalization of RL agents is critical to success in the real world, yet zero-shot policy transfer is a challenging problem since even minor visual changes could make the trained agent completely fail in the new task. We propose USRA: Unified State Representation Learning under Data Augmentation, a representation learning framework that learns a latent unified state representation by performing data augmentations on its observations to improve its ability to generalize to unseen target domains. We showcase the success of our approach on the DeepMind Control Generalization Benchmark for the Walker environment and find that USRA achieves higher sample efficiency and 14.3% better domain adaptation performance compared to the best baseline results.
Strategy Discovery and Mixture in Lifelong Learning from Heterogeneous Demonstration
Feb 14, 2022Learning from Demonstration (LfD) approaches empower end-users to teach robots novel tasks via demonstrations of the desired behaviors, democratizing access to robotics. A key challenge in LfD research is that users tend to provide heterogeneous demonstrations for the same task due to various strategies and preferences. Therefore, it is essential to develop LfD algorithms that ensure \textit{flexibility} (the robot adapts to personalized strategies), \textit{efficiency} (the robot achieves sample-efficient adaptation), and \textit{scalability} (robot reuses a concise set of strategies to represent a large amount of behaviors). In this paper, we propose a novel algorithm, Dynamic Multi-Strategy Reward Distillation (DMSRD), which distills common knowledge between heterogeneous demonstrations, leverages learned strategies to construct mixture policies, and continues to improve by learning from all available data. Our personalized, federated, and lifelong LfD architecture surpasses benchmarks in two continuous control problems with an average 77\% improvement in policy returns and 42\% improvement in log likelihood, alongside stronger task reward correlation and more precise strategy rewards.