 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBAT: Balancing Agility and Stability via Online Policy Switching for Long-Horizon Whole-Body Humanoid Control
Apr 01, 2026Despite recent advances in control, reinforcement learning, and imitation learning, developing a unified framework that can achieve agile, precise, and robust whole-body behaviors, particularly in long-horizon tasks, remains challenging. Existing approaches typically follow two paradigms: coupled whole-body policies for global coordination and decoupled policies for modular precision. However, without a systematic method to integrate both, this trade-off between agility, robustness, and precision remains unresolved. In this work, we propose BAT, an online policy-switching framework that dynamically selects between two complementary whole-body RL controllers to balance agility and stability across different motion contexts. Our framework consists of two complementary modules: a switching policy learned via hierarchical RL with an expert guidance from sliding-horizon policy pre-evaluation, and an option-aware VQ-VAE that predicts option preference from discrete motion token sequences for improved generalization. The final decision is obtained via confidence-weighted fusion of two modules. Extensive simulations and real-world experiments on the Unitree G1 humanoid robot demonstrate that BAT enables versatile long-horizon loco-manipulation and outperforms prior methods across diverse tasks.
Flip Stunts on Bicycle Robots using Iterative Motion Imitation
Mar 30, 2026This work demonstrates a front-flip on bicycle robots via reinforcement learning, particularly by imitating reference motions that are infeasible and imperfect. To address this, we propose Iterative Motion Imitation(IMI), a method that iteratively imitates trajectories generated by prior policy rollouts. Starting from an initial reference that is kinematically or dynamically infeasible, IMI helps train policies that lead to feasible and agile behaviors. We demonstrate our method on Ultra-Mobility Vehicle (UMV), a bicycle robot that is designed to enable agile behaviors. From a self-colliding table-to-ground flip reference generated by a model-based controller, we are able to train policies that enable ground-to-ground and ground-to-table front-flips. We show that compared to a single-shot motion imitation, IMI results in policies with higher success rates and can transfer robustly to the real world. To our knowledge, this is the first unassisted acrobatic flip behavior on such a platform.
Partial Motion Imitation for Learning Cart Pushing with Legged Manipulators
Mar 27, 2026Loco-manipulation is a key capability for legged robots to perform practical mobile manipulation tasks, such as transporting and pushing objects, in real-world environments. However, learning robust loco-manipulation skills remains challenging due to the difficulty of maintaining stable locomotion while simultaneously performing precise manipulation behaviors. This work proposes a partial imitation learning approach that transfers the locomotion style learned from a locomotion task to cart loco-manipulation. A robust locomotion policy is first trained with extensive domain and terrain randomization, and a loco-manipulation policy is then learned by imitating only lower-body motions using a partial adversarial motion prior. We conduct experiments demonstrating that the learned policy successfully pushes a cart along diverse trajectories in IsaacLab and transfers effectively to MuJoCo. We also compare our method to several baselines and show that the proposed approach achieves more stable and accurate loco-manipulation behaviors.
EgoAVFlow: Robot Policy Learning with Active Vision from Human Egocentric Videos via 3D Flow
Feb 25, 2026Egocentric human videos provide a scalable source of manipulation demonstrations; however, deploying them on robots requires active viewpoint control to maintain task-critical visibility, which human viewpoint imitation often fails to provide due to human-specific priors. We propose EgoAVFlow, which learns manipulation and active vision from egocentric videos through a shared 3D flow representation that supports geometric visibility reasoning and transfers without robot demonstrations. EgoAVFlow uses diffusion models to predict robot actions, future 3D flow, and camera trajectories, and refines viewpoints at test time with reward-maximizing denoising under a visibility-aware reward computed from predicted motion and scene geometry. Real-world experiments under actively changing viewpoints show that EgoAVFlow consistently outperforms prior human-demo-based baselines, demonstrating effective visibility maintenance and robust manipulation without robot demonstrations.
AdaptManip: Learning Adaptive Whole-Body Object Lifting and Delivery with Online Recurrent State Estimation
Feb 16, 2026This paper presents Adaptive Whole-body Loco-Manipulation, AdaptManip, a fully autonomous framework for humanoid robots to perform integrated navigation, object lifting, and delivery. Unlike prior imitation learning-based approaches that rely on human demonstrations and are often brittle to disturbances, AdaptManip aims to train a robust loco-manipulation policy via reinforcement learning without human demonstrations or teleoperation data. The proposed framework consists of three coupled components: (1) a recurrent object state estimator that tracks the manipulated object in real time under limited field-of-view and occlusions; (2) a whole-body base policy for robust locomotion with residual manipulation control for stable object lifting and delivery; and (3) a LiDAR-based robot global position estimator that provides drift-robust localization. All components are trained in simulation using reinforcement learning and deployed on real hardware in a zero-shot manner. Experimental results show that AdaptManip significantly outperforms baseline methods, including imitation learning-based approaches, in adaptability and overall success rate, while accurate object state estimation improves manipulation performance even under occlusion. We further demonstrate fully autonomous real-world navigation, object lifting, and delivery on a humanoid robot.
RobotDesignGPT: Automated Robot Design Synthesis using Vision Language Models
Jan 16, 2026Robot design is a nontrivial process that involves careful consideration of multiple criteria, including user specifications, kinematic structures, and visual appearance. Therefore, the design process often relies heavily on domain expertise and significant human effort. The majority of current methods are rule-based, requiring the specification of a grammar or a set of primitive components and modules that can be composed to create a design. We propose a novel automated robot design framework, RobotDesignGPT, that leverages the general knowledge and reasoning capabilities of large pre-trained vision-language models to automate the robot design synthesis process. Our framework synthesizes an initial robot design from a simple user prompt and a reference image. Our novel visual feedback approach allows us to greatly improve the design quality and reduce unnecessary manual feedback. We demonstrate that our framework can design visually appealing and kinematically valid robots inspired by nature, ranging from legged animals to flying creatures. We justify the proposed framework by conducting an ablation study and a user study.
Dynamic Policy Learning for Legged Robot with Simplified Model Pretraining and Model Homotopy Transfer
Dec 31, 2025Generating dynamic motions for legged robots remains a challenging problem. While reinforcement learning has achieved notable success in various legged locomotion tasks, producing highly dynamic behaviors often requires extensive reward tuning or high-quality demonstrations. Leveraging reduced-order models can help mitigate these challenges. However, the model discrepancy poses a significant challenge when transferring policies to full-body dynamics environments. In this work, we introduce a continuation-based learning framework that combines simplified model pretraining and model homotopy transfer to efficiently generate and refine complex dynamic behaviors. First, we pretrain the policy using a single rigid body model to capture core motion patterns in a simplified environment. Next, we employ a continuation strategy to progressively transfer the policy to the full-body environment, minimizing performance loss. To define the continuation path, we introduce a model homotopy from the single rigid body model to the full-body model by gradually redistributing mass and inertia between the trunk and legs. The proposed method not only achieves faster convergence but also demonstrates superior stability during the transfer process compared to baseline methods. Our framework is validated on a range of dynamic tasks, including flips and wall-assisted maneuvers, and is successfully deployed on a real quadrupedal robot.
A Design Co-Pilot for Task-Tailored Manipulators
Sep 16, 2025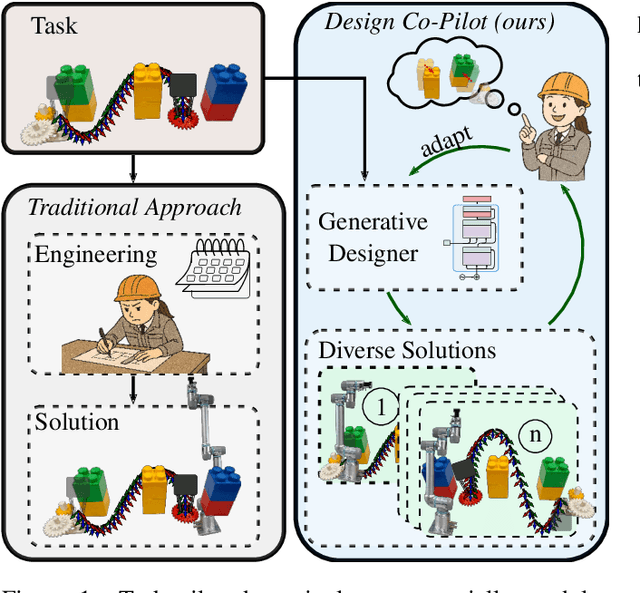
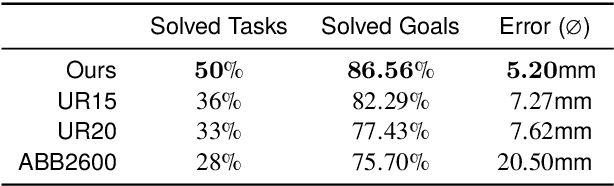

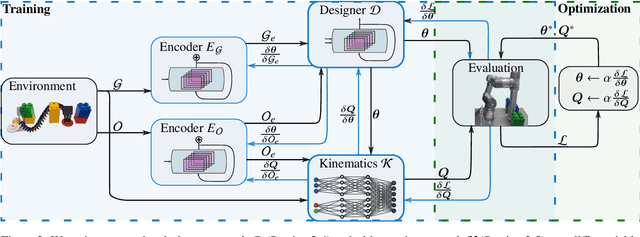
Although robotic manipulators are used in an ever-growing range of applications, robot manufacturers typically follow a ``one-fits-all'' philosophy, employing identical manipulators in various settings. This often leads to suboptimal performance, as general-purpose designs fail to exploit particularities of tasks. The development of custom, task-tailored robots is hindered by long, cost-intensive development cycles and the high cost of customized hardware. Recently, various computational design methods have been devised to overcome the bottleneck of human engineering. In addition, a surge of modular robots allows quick and economical adaptation to changing industrial settings. This work proposes an approach to automatically designing and optimizing robot morphologies tailored to a specific environment. To this end, we learn the inverse kinematics for a wide range of different manipulators. A fully differentiable framework realizes gradient-based fine-tuning of designed robots and inverse kinematics solutions. Our generative approach accelerates the generation of specialized designs from hours with optimization-based methods to seconds, serving as a design co-pilot that enables instant adaptation and effective human-AI collaboration. Numerical experiments show that our approach finds robots that can navigate cluttered environments, manipulators that perform well across a specified workspace, and can be adapted to different hardware constraints. Finally, we demonstrate the real-world applicability of our method by setting up a modular robot designed in simulation that successfully moves through an obstacle course.
EMMA: Scaling Mobile Manipulation via Egocentric Human Data
Sep 04, 2025Scaling mobile manipulation imitation learning is bottlenecked by expensive mobile robot teleoperation. We present Egocentric Mobile MAnipulation (EMMA), an end-to-end framework training mobile manipulation policies from human mobile manipulation data with static robot data, sidestepping mobile teleoperation. To accomplish this, we co-train human full-body motion data with static robot data. In our experiments across three real-world tasks, EMMA demonstrates comparable performance to baselines trained on teleoperated mobile robot data (Mobile ALOHA), achieving higher or equivalent task performance in full task success. We find that EMMA is able to generalize to new spatial configurations and scenes, and we observe positive performance scaling as we increase the hours of human data, opening new avenues for scalable robotic learning in real-world environments. Details of this project can be found at https://ego-moma.github.io/.
Unsupervised Skill Discovery as Exploration for Learning Agile Locomotion
Aug 12, 2025Exploration is crucial for enabling legged robots to learn agile locomotion behaviors that can overcome diverse obstacles. However, such exploration is inherently challenging, and we often rely on extensive reward engineering, expert demonstrations, or curriculum learning - all of which limit generalizability. In this work, we propose Skill Discovery as Exploration (SDAX), a novel learning framework that significantly reduces human engineering effort. SDAX leverages unsupervised skill discovery to autonomously acquire a diverse repertoire of skills for overcoming obstacles. To dynamically regulate the level of exploration during training, SDAX employs a bi-level optimization process that autonomously adjusts the degree of exploration. We demonstrate that SDAX enables quadrupedal robots to acquire highly agile behaviors including crawling, climbing, leaping, and executing complex maneuvers such as jumping off vertical walls. Finally, we deploy the learned policy on real hardware, validating its successful transfer to the real world.