 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVQ-Jarvis: Retrieval-Augmented Video Restoration Agent with Sharp Vision and Fast Thought
Mar 24, 2026Video restoration in real-world scenarios is challenged by heterogeneous degradations, where static architectures and fixed inference pipelines often fail to generalize. Recent agent-based approaches offer dynamic decision making, yet existing video restoration agents remain limited by insufficient quality perception and inefficient search strategies. We propose VQ-Jarvis, a retrieval-augmented, all-in-one intelligent video restoration agent with sharper vision and faster thought. VQ-Jarvis is designed to accurately perceive degradations and subtle differences among paired restoration results, while efficiently discovering optimal restoration trajectories. To enable sharp vision, we construct VSR-Compare, the first large-scale video paired enhancement dataset with 20K comparison pairs covering 7 degradation types, 11 enhancement operators, and diverse content domains. Based on this dataset, we train a multiple operator judge model and a degradation perception model to guide agent decisions. To achieve fast thought, we introduce a hierarchical operator scheduling strategy that adapts to video difficulty: for easy cases, optimal restoration trajectories are retrieved in a one-step manner from a retrieval-augmented generation (RAG) library; for harder cases, a step-by-step greedy search is performed to balance efficiency and accuracy. Extensive experiments demonstrate that VQ-Jarvis consistently outperforms existing methods on complex degraded videos.
OARS: Process-Aware Online Alignment for Generative Real-World Image Super-Resolution
Mar 13, 2026Aligning generative real-world image super-resolution models with human visual preference is challenging due to the perception--fidelity trade-off and diverse, unknown degradations. Prior approaches rely on offline preference optimization and static metric aggregation, which are often non-interpretable and prone to pseudo-diversity under strong conditioning. We propose OARS, a process-aware online alignment framework built on COMPASS, a MLLM-based reward that evaluates the LR to SR transition by jointly modeling fidelity preservation and perceptual gain with an input-quality-adaptive trade-off. To train COMPASS, we curate COMPASS-20K spanning synthetic and real degradations, and introduce a three-stage perceptual annotation pipeline that yields calibrated, fine-grained training labels. Guided by COMPASS, OARS performs progressive online alignment from cold-start flow matching to full-reference and finally reference-free RL via shallow LoRA optimization for on-policy exploration. Extensive experiments and user studies demonstrate consistent perceptual improvements while maintaining fidelity, achieving state-of-the-art performance on Real-ISR benchmarks.
Improved Adversarial Diffusion Compression for Real-World Video Super-Resolution
Feb 28, 2026While many diffusion models have achieved impressive results in real-world video super-resolution (Real-VSR) by generating rich and realistic details, their reliance on multi-step sampling leads to slow inference. One-step networks like SeedVR2, DOVE, and DLoRAL alleviate this through condensing generation into one single step, yet they remain heavy, with billions of parameters and multi-second latency. Recent adversarial diffusion compression (ADC) offers a promising path via pruning and distilling these models into a compact AdcSR network, but directly applying it to Real-VSR fails to balance spatial details and temporal consistency due to its lack of temporal awareness and the limitations of standard adversarial learning. To address these challenges, we propose an improved ADC method for Real-VSR. Our approach distills a large diffusion Transformer (DiT) teacher DOVE equipped with 3D spatio-temporal attentions, into a pruned 2D Stable Diffusion (SD)-based AdcSR backbone, augmented with lightweight 1D temporal convolutions, achieving significantly higher efficiency. In addition, we introduce a dual-head adversarial distillation scheme, in which discriminators in both pixel and feature domains explicitly disentangle the discrimination of details and consistency into two heads, enabling both objectives to be effectively optimized without sacrificing one for the other. Experiments demonstrate that the resulting compressed AdcVSR model reduces complexity by 95% in parameters and achieves an 8$\times$ acceleration over its DiT teacher DOVE, while maintaining competitive video quality and efficiency.
Eliminating VAE for Fast and High-Resolution Generative Detail Restoration
Feb 11, 2026Diffusion models have attained remarkable breakthroughs in the real-world super-resolution (SR) task, albeit at slow inference and high demand on devices. To accelerate inference, recent works like GenDR adopt step distillation to minimize the step number to one. However, the memory boundary still restricts the maximum processing size, necessitating tile-by-tile restoration of high-resolution images. Through profiling the pipeline, we pinpoint that the variational auto-encoder (VAE) is the bottleneck of latency and memory. To completely solve the problem, we leverage pixel-(un)shuffle operations to eliminate the VAE, reversing the latent-based GenDR to pixel-space GenDR-Pix. However, upscale with x8 pixelshuffle may induce artifacts of repeated patterns. To alleviate the distortion, we propose a multi-stage adversarial distillation to progressively remove the encoder and decoder. Specifically, we utilize generative features from the previous stage models to guide adversarial discrimination. Moreover, we propose random padding to augment generative features and avoid discriminator collapse. We also introduce a masked Fourier space loss to penalize the outliers of amplitude. To improve inference performance, we empirically integrate a padding-based self-ensemble with classifier-free guidance to improve inference scaling. Experimental results show that GenDR-Pix performs 2.8x acceleration and 60% memory-saving compared to GenDR with negligible visual degradation, surpassing other one-step diffusion SR. Against all odds, GenDR-Pix can restore 4K image in only 1 second and 6GB.
A Tri-Dynamic Preprocessing Framework for UGC Video Compression
Dec 18, 2025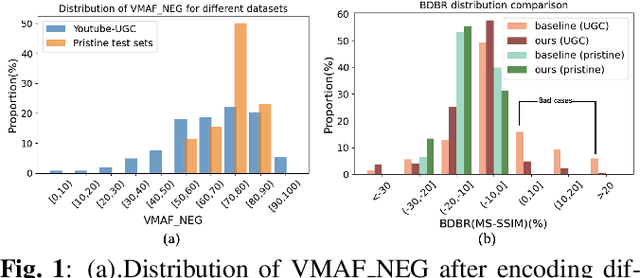
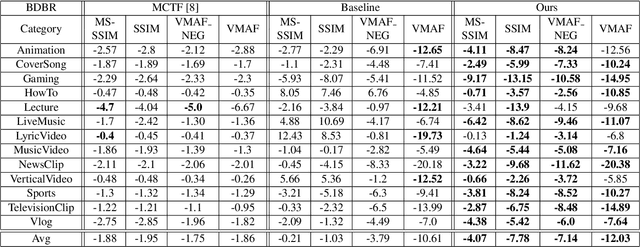
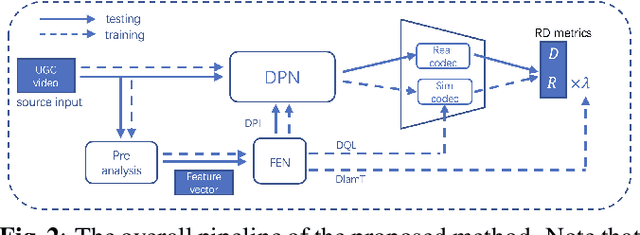
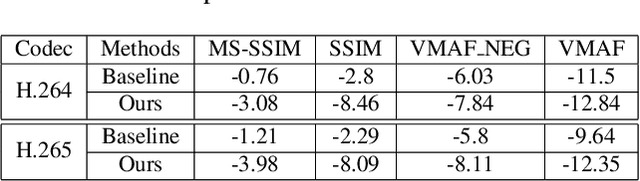
In recent years, user generated content (UGC) has become the dominant force in internet traffic. However, UGC videos exhibit a higher degree of variability and diverse characteristics compared to traditional encoding test videos. This variance challenges the effectiveness of data-driven machine learning algorithms for optimizing encoding in the broader context of UGC scenarios. To address this issue, we propose a Tri-Dynamic Preprocessing framework for UGC. Firstly, we employ an adaptive factor to regulate preprocessing intensity. Secondly, an adaptive quantization level is employed to fine-tune the codec simulator. Thirdly, we utilize an adaptive lambda tradeoff to adjust the rate-distortion loss function. Experimental results on large-scale test sets demonstrate that our method attains exceptional performance.
Generative Preprocessing for Image Compression with Pre-trained Diffusion Models
Dec 17, 2025Preprocessing is a well-established technique for optimizing compression, yet existing methods are predominantly Rate-Distortion (R-D) optimized and constrained by pixel-level fidelity. This work pioneers a shift towards Rate-Perception (R-P) optimization by, for the first time, adapting a large-scale pre-trained diffusion model for compression preprocessing. We propose a two-stage framework: first, we distill the multi-step Stable Diffusion 2.1 into a compact, one-step image-to-image model using Consistent Score Identity Distillation (CiD). Second, we perform a parameter-efficient fine-tuning of the distilled model's attention modules, guided by a Rate-Perception loss and a differentiable codec surrogate. Our method seamlessly integrates with standard codecs without any modification and leverages the model's powerful generative priors to enhance texture and mitigate artifacts. Experiments show substantial R-P gains, achieving up to a 30.13% BD-rate reduction in DISTS on the Kodak dataset and delivering superior subjective visual quality.
A Preprocessing Framework for Video Machine Vision under Compression
Dec 17, 2025
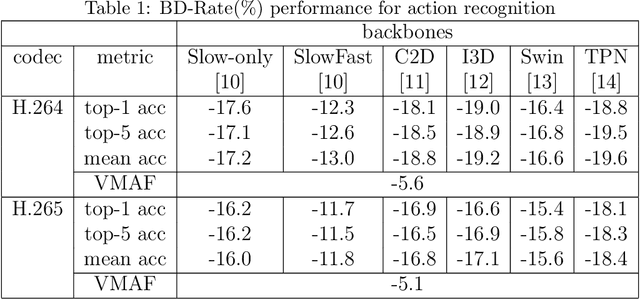
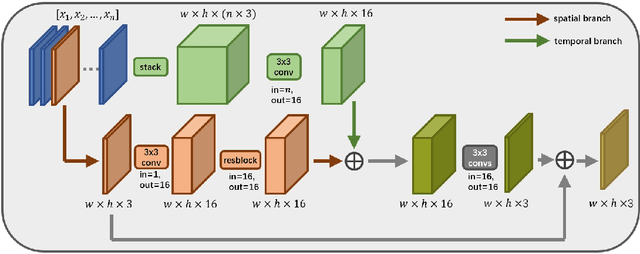
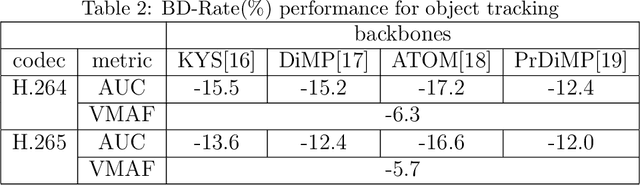
There has been a growing trend in compressing and transmitting videos from terminals for machine vision tasks. Nevertheless, most video coding optimization method focus on minimizing distortion according to human perceptual metrics, overlooking the heightened demands posed by machine vision systems. In this paper, we propose a video preprocessing framework tailored for machine vision tasks to address this challenge. The proposed method incorporates a neural preprocessor which retaining crucial information for subsequent tasks, resulting in the boosting of rate-accuracy performance. We further introduce a differentiable virtual codec to provide constraints on rate and distortion during the training stage. We directly apply widely used standard codecs for testing. Therefore, our solution can be easily applied to real-world scenarios. We conducted extensive experiments evaluating our compression method on two typical downstream tasks with various backbone networks. The experimental results indicate that our approach can save over 15% of bitrate compared to using only the standard codec anchor version.
Audio-Visual Cross-Modal Compression for Generative Face Video Coding
Dec 17, 2025Generative face video coding (GFVC) is vital for modern applications like video conferencing, yet existing methods primarily focus on video motion while neglecting the significant bitrate contribution of audio. Despite the well-established correlation between audio and lip movements, this cross-modal coherence has not been systematically exploited for compression. To address this, we propose an Audio-Visual Cross-Modal Compression (AVCC) framework that jointly compresses audio and video streams. Our framework extracts motion information from video and tokenizes audio features, then aligns them through a unified audio-video diffusion process. This allows synchronized reconstruction of both modalities from a shared representation. In extremely low-rate scenarios, AVCC can even reconstruct one modality from the other. Experiments show that AVCC significantly outperforms the Versatile Video Coding (VVC) standard and state-of-the-art GFVC schemes in rate-distortion performance, paving the way for more efficient multimodal communication systems.
Region-Adaptive Video Sharpening via Rate-Perception Optimization
Aug 12, 2025



Sharpening is a widely adopted video enhancement technique. However, uniform sharpening intensity ignores texture variations, degrading video quality. Sharpening also increases bitrate, and there's a lack of techniques to optimally allocate these additional bits across diverse regions. Thus, this paper proposes RPO-AdaSharp, an end-to-end region-adaptive video sharpening model for both perceptual enhancement and bitrate savings. We use the coding tree unit (CTU) partition mask as prior information to guide and constrain the allocation of increased bits. Experiments on benchmarks demonstrate the effectiveness of the proposed model qualitatively and quantitatively.
Adaptive High-Frequency Preprocessing for Video Coding
Aug 12, 2025
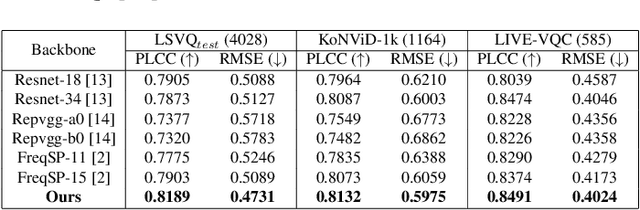
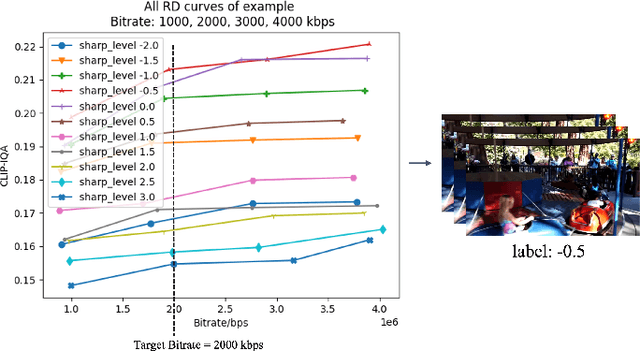
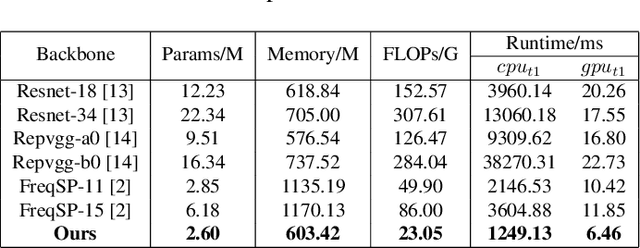
High-frequency components are crucial for maintaining video clarity and realism, but they also significantly impact coding bitrate, resulting in increased bandwidth and storage costs. This paper presents an end-to-end learning-based framework for adaptive high-frequency preprocessing to enhance subjective quality and save bitrate in video coding. The framework employs the Frequency-attentive Feature pyramid Prediction Network (FFPN) to predict the optimal high-frequency preprocessing strategy, guiding subsequent filtering operators to achieve the optimal tradeoff between bitrate and quality after compression. For training FFPN, we pseudo-label each training video with the optimal strategy, determined by comparing the rate-distortion (RD) performance across different preprocessing types and strengths. Distortion is measured using the latest quality assessment metric. Comprehensive evaluations on multiple datasets demonstrate the visually appealing enhancement capabilities and bitrate savings achieved by our framework.