 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFINE-DP: Diffusion Policy Fine-tuning for Humanoid Loco-manipulation via Reinforcement Learning
Mar 14, 2026Humanoid loco-manipulation requires coordinated high-level motion plans with stable, low-level whole-body execution under complex robot-environment dynamics and long-horizon tasks. While diffusion policies (DPs) show promise for learning from demonstrations, deploying them on humanoids poses critical challenges: the motion planner trained offline is decoupled from the low-level controller, leading to poor command tracking, compounding distribution shift, and task failures. The common approach of scaling demonstration data is prohibitively expensive for high-dimensional humanoid systems. To address this challenge, we present REFINE-DP (REinforcement learning FINE-tuning of Diffusion Policy), a hierarchical framework that jointly optimizes a DP high-level planner and an RL-based low-level loco-manipulation controller. The DP is fine-tuned via a PPO-based diffusion policy gradient to improve task success rate, while the controller is simultaneously updated to accurately track the planner's evolving command distribution, reducing the distributional mismatch that degrades motion quality. We validate REFINE-DP on a humanoid robot performing loco-manipulation tasks, including door traversal and long-horizon object transport. REFINE-DP achieves an over $90\%$ success rate in simulation, even in out-of-distribution cases not seen in the pre-trained data, and enables smooth autonomous task execution in real-world dynamic environments. Our proposed method substantially outperforms pre-trained DP baselines and demonstrates that RL fine-tuning is key to reliable humanoid loco-manipulation. https://refine-dp.github.io/REFINE-DP/
PreCi: Pretraining and Continual Improvement of Humanoid Locomotion via Model-Assumption-Based Regularization
Apr 14, 2025
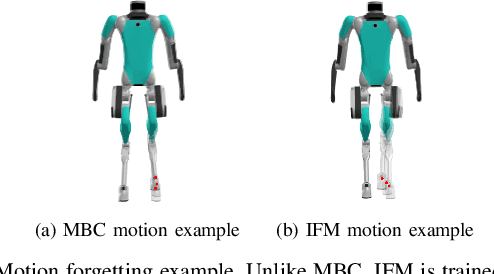
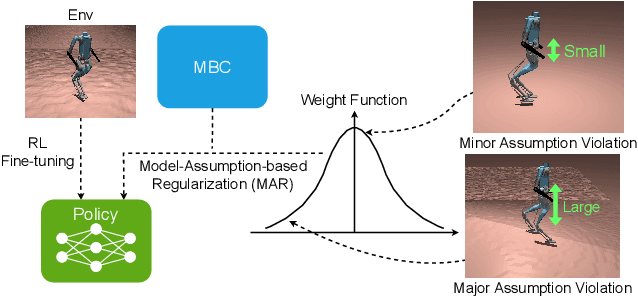

Humanoid locomotion is a challenging task due to its inherent complexity and high-dimensional dynamics, as well as the need to adapt to diverse and unpredictable environments. In this work, we introduce a novel learning framework for effectively training a humanoid locomotion policy that imitates the behavior of a model-based controller while extending its capabilities to handle more complex locomotion tasks, such as more challenging terrain and higher velocity commands. Our framework consists of three key components: pre-training through imitation of the model-based controller, fine-tuning via reinforcement learning, and model-assumption-based regularization (MAR) during fine-tuning. In particular, MAR aligns the policy with actions from the model-based controller only in states where the model assumption holds to prevent catastrophic forgetting. We evaluate the proposed framework through comprehensive simulation tests and hardware experiments on a full-size humanoid robot, Digit, demonstrating a forward speed of 1.5 m/s and robust locomotion across diverse terrains, including slippery, sloped, uneven, and sandy terrains.
Humanoid Locomotion and Manipulation: Current Progress and Challenges in Control, Planning, and Learning
Jan 03, 2025



Humanoid robots have great potential to perform various human-level skills. These skills involve locomotion, manipulation, and cognitive capabilities. Driven by advances in machine learning and the strength of existing model-based approaches, these capabilities have progressed rapidly, but often separately. Therefore, a timely overview of current progress and future trends in this fast-evolving field is essential. This survey first summarizes the model-based planning and control that have been the backbone of humanoid robotics for the past three decades. We then explore emerging learning-based methods, with a focus on reinforcement learning and imitation learning that enhance the versatility of loco-manipulation skills. We examine the potential of integrating foundation models with humanoid embodiments, assessing the prospects for developing generalist humanoid agents. In addition, this survey covers emerging research for whole-body tactile sensing that unlocks new humanoid skills that involve physical interactions. The survey concludes with a discussion of the challenges and future trends.
Opt2Skill: Imitating Dynamically-feasible Whole-Body Trajectories for Versatile Humanoid Loco-Manipulation
Sep 30, 2024
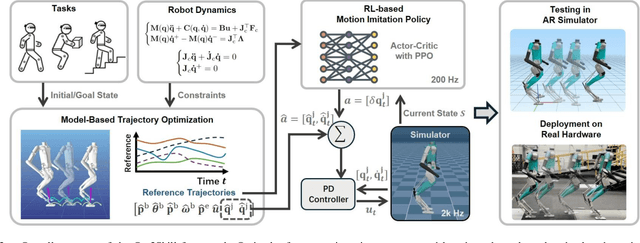
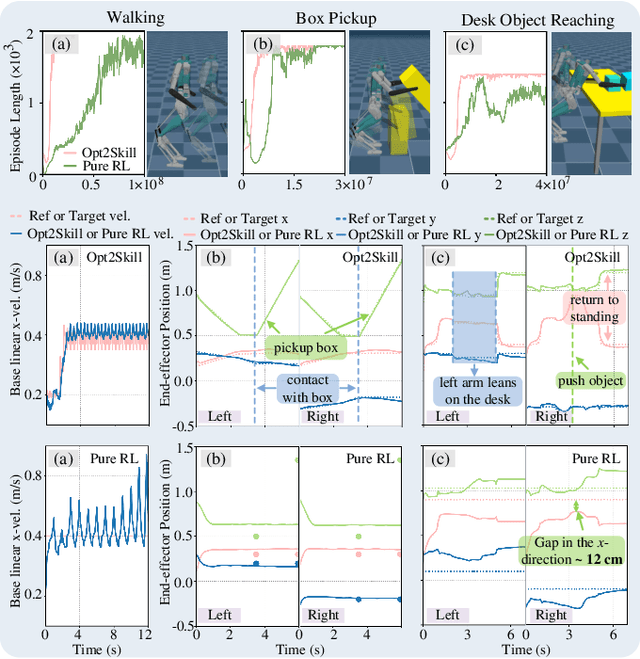
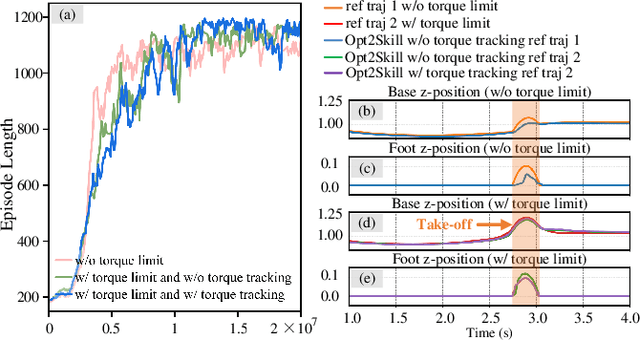
Humanoid robots are designed to perform diverse loco-manipulation tasks. However, they face challenges due to their high-dimensional and unstable dynamics, as well as the complex contact-rich nature of the tasks. Model-based optimal control methods offer precise and systematic control but are limited by high computational complexity and accurate contact sensing. On the other hand, reinforcement learning (RL) provides robustness and handles high-dimensional spaces but suffers from inefficient learning, unnatural motion, and sim-to-real gaps. To address these challenges, we introduce Opt2Skill, an end-to-end pipeline that combines model-based trajectory optimization with RL to achieve robust whole-body loco-manipulation. We generate reference motions for the Digit humanoid robot using differential dynamic programming (DDP) and train RL policies to track these trajectories. Our results demonstrate that Opt2Skill outperforms pure RL methods in both training efficiency and task performance, with optimal trajectories that account for torque limits enhancing trajectory tracking. We successfully transfer our approach to real-world applications.
Robust-Locomotion-by-Logic: Perturbation-Resilient Bipedal Locomotion via Signal Temporal Logic Guided Model Predictive Control
Mar 24, 2024
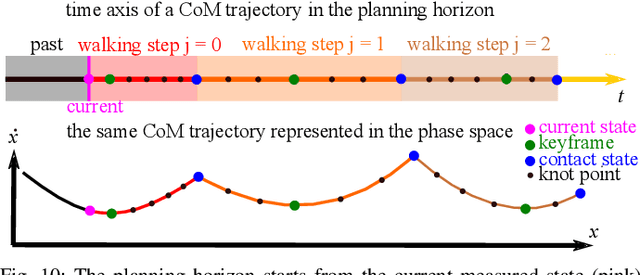


This study introduces a robust planning framework that utilizes a model predictive control (MPC) approach, enhanced by incorporating signal temporal logic (STL) specifications. This marks the first-ever study to apply STL-guided trajectory optimization for bipedal locomotion, specifically designed to handle both translational and orientational perturbations. Existing recovery strategies often struggle with reasoning complex task logic and evaluating locomotion robustness systematically, making them susceptible to failures caused by inappropriate recovery strategies or lack of robustness. To address these issues, we design an analytical robustness metric for bipedal locomotion and quantify this metric using STL specifications, which guide the generation of recovery trajectories to achieve maximum locomotion robustness. To enable safe and computational-efficient crossed-leg maneuver, we design data-driven self-leg-collision constraints that are $1000$ times faster than the traditional inverse-kinematics-based approach. Our framework outperforms a state-of-the-art locomotion controller, a standard MPC without STL, and a linear-temporal-logic-based planner in a high-fidelity dynamic simulation, especially in scenarios involving crossed-leg maneuvers. Additionally, the Cassie bipedal robot achieves robust performance under horizontal and orientational perturbations such as those observed in ship motions. These environments are validated in simulations and deployed on hardware. Furthermore, our proposed method demonstrates versatility on stepping stones and terrain-agnostic features on inclined terrains.
Learn to Teach: Improve Sample Efficiency in Teacher-student Learning for Sim-to-Real Transfer
Feb 09, 2024



Simulation-to-reality (sim-to-real) transfer is a fundamental problem for robot learning. Domain Randomization, which adds randomization during training, is a powerful technique that effectively addresses the sim-to-real gap. However, the noise in observations makes learning significantly harder. Recently, studies have shown that employing a teacher-student learning paradigm can accelerate training in randomized environments. Learned with privileged information, a teacher agent can instruct the student agent to operate in noisy environments. However, this approach is often not sample efficient as the experience collected by the teacher is discarded completely when training the student, wasting information revealed by the environment. In this work, we extend the teacher-student learning paradigm by proposing a sample efficient learning framework termed Learn to Teach (L2T) that recycles experience collected by the teacher agent. We observe that the dynamics of the environments for both agents remain unchanged, and the state space of the teacher is coupled with the observation space of the student. We show that a single-loop algorithm can train both the teacher and student agents under both Reinforcement Learning and Inverse Reinforcement Learning contexts. We implement variants of our methods, conduct experiments on the MuJoCo benchmark, and apply our methods to the Cassie robot locomotion problem. Extensive experiments show that our method achieves competitive performance while only requiring environmental interaction with the teacher.
Signal Temporal Logic-Guided Model Predictive Control for Robust Bipedal Locomotion Resilient to Runtime External Perturbations
Oct 17, 2023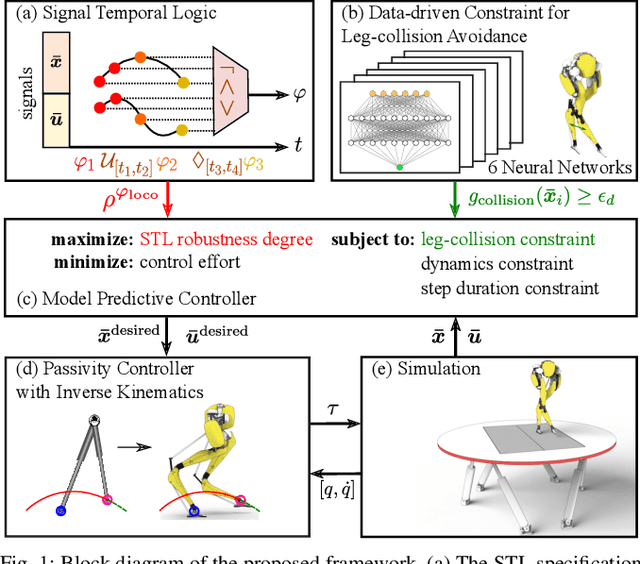


This study investigates formal-method-based trajectory optimization (TO) for bipedal locomotion, focusing on scenarios where the robot encounters external perturbations at unforeseen times. Our key research question centers around the assurance of task specification correctness and the maximization of specification robustness for a bipedal robot in the presence of external perturbations. Our contribution includes the design of an optimization-based task and motion planning framework that generates optimal control sequences with formal guarantees of external perturbation recovery. As a core component of the framework, a model predictive controller (MPC) encodes signal temporal logic (STL)-based task specifications as a cost function. In particular, we investigate challenging scenarios where the robot is subjected to lateral perturbations that increase the risk of failure due to leg self-collision. To address this, we synthesize agile and safe crossed-leg maneuvers to enhance locomotion stability. This work marks the first study to incorporate formal guarantees offered by STL into a TO for perturbation recovery of bipedal locomotion. We demonstrate the efficacy of the framework via perturbation experiments in simulations.
Infer and Adapt: Bipedal Locomotion Reward Learning from Demonstrations via Inverse Reinforcement Learning
Sep 28, 2023



Enabling bipedal walking robots to learn how to maneuver over highly uneven, dynamically changing terrains is challenging due to the complexity of robot dynamics and interacted environments. Recent advancements in learning from demonstrations have shown promising results for robot learning in complex environments. While imitation learning of expert policies has been well-explored, the study of learning expert reward functions is largely under-explored in legged locomotion. This paper brings state-of-the-art Inverse Reinforcement Learning (IRL) techniques to solving bipedal locomotion problems over complex terrains. We propose algorithms for learning expert reward functions, and we subsequently analyze the learned functions. Through nonlinear function approximation, we uncover meaningful insights into the expert's locomotion strategies. Furthermore, we empirically demonstrate that training a bipedal locomotion policy with the inferred reward functions enhances its walking performance on unseen terrains, highlighting the adaptability offered by reward learning.
Walking-by-Logic: Signal Temporal Logic-Guided Model Predictive Control for Bipedal Locomotion Resilient to External Perturbations
Sep 22, 2023



This study proposes a novel planning framework based on a model predictive control formulation that incorporates signal temporal logic (STL) specifications for task completion guarantees and robustness quantification. This marks the first-ever study to apply STL-guided trajectory optimization for bipedal locomotion push recovery, where the robot experiences unexpected disturbances. Existing recovery strategies often struggle with complex task logic reasoning and locomotion robustness evaluation, making them susceptible to failures caused by inappropriate recovery strategies or insufficient robustness. To address this issue, the STL-guided framework generates optimal and safe recovery trajectories that simultaneously satisfy the task specification and maximize the locomotion robustness. Our framework outperforms a state-of-the-art locomotion controller in a high-fidelity dynamic simulation, especially in scenarios involving crossed-leg maneuvers. Furthermore, it demonstrates versatility in tasks such as locomotion on stepping stones, where the robot must select from a set of disjointed footholds to maneuver successfully.
Integrated Task and Motion Planning for Safe Legged Navigation in Partially Observable Environments
Oct 23, 2021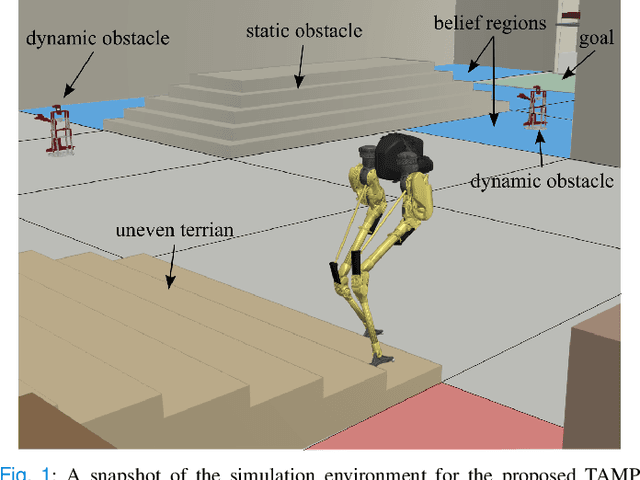
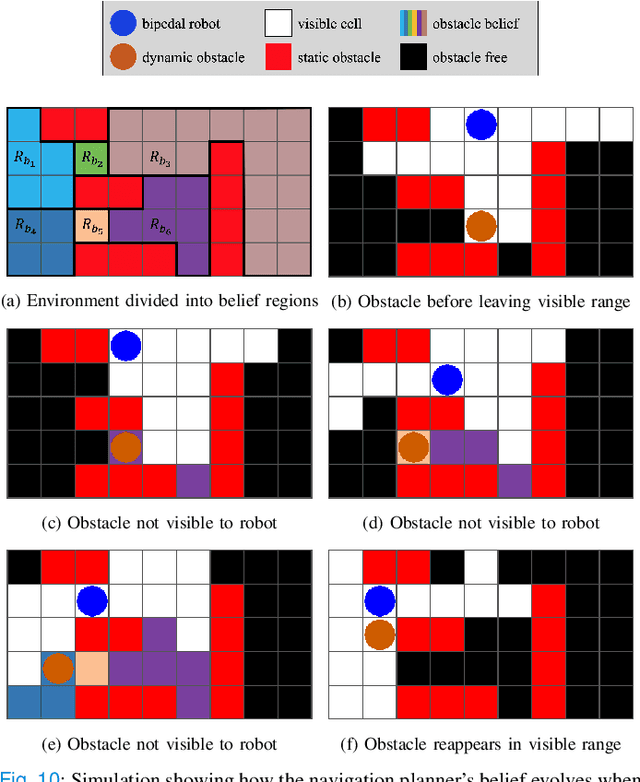
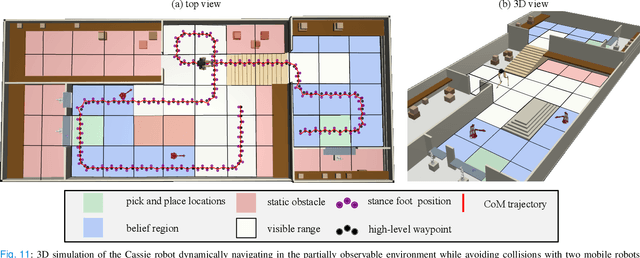
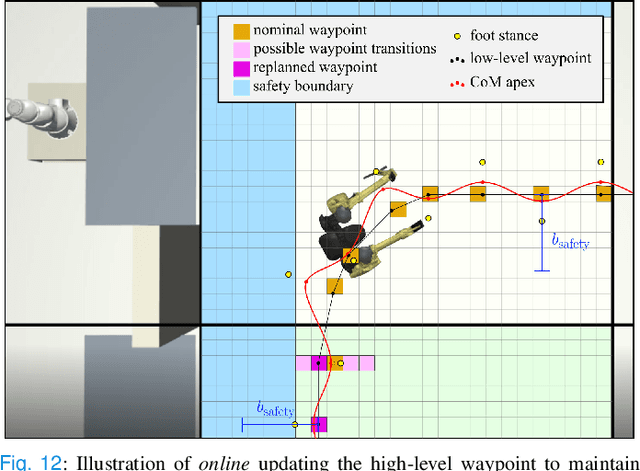
This study proposes a hierarchically integrated framework for safe task and motion planning (TAMP) of bipedal locomotion in a partially observable environment with dynamic obstacles and uneven terrain. The high-level task planner employs linear temporal logic (LTL) for a reactive game synthesis between the robot and its environment and provides a formal guarantee on navigation safety and task completion. To address environmental partial observability, a belief abstraction is employed at the high-level navigation planner to estimate the dynamic obstacles' location when they are out of the robot's local field of view. Accordingly, a synthesized action planner sends a set of locomotion actions including walking step, step height, and heading angle change, to the middle-level motion planner, while incorporating safe locomotion specifications extracted from safety theorems based on a reduced-order model (ROM) of the locomotion process. The motion planner employs the ROM to design safety criteria and a sampling algorithm to generate non-periodic motion plans that accurately track high-level actions. To address external perturbations, this study also investigates safe sequential composition of the keyframe locomotion state and achieves robust transitions against external perturbations through reachability analysis. A set of ROM-based hyperparameters are finally interpolated to design whole-body locomotion gaits generated by trajectory optimization and validate the viable deployment of the ROM-based TAMP to the full-body trajectory generation for a 20-degrees-of-freedom Cassie bipedal robot designed by Agility Robotics. The proposed framework is validated by a set of scenarios in uneven, partially observable environments with dynamical obstacles.