 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssetGen: Deployable 3D Asset Generation at Interactive Speed
May 22, 2026While 3D generation is progressing rapidly, recent work has often focused on obtaining high-resolution assets, leaving user experience and deployability as afterthoughts. We present AssetGen, a 3D generator that focuses instead on these two aspects. Given one reference image, in 30 seconds it produces a high-quality mesh with baked normals, a color texture, and a controlled polygon budget suitable for real-time rendering, including mobile use cases. The AssetGen Flash variant further reduces latency to 14 seconds for interactive and agentic creation loops. Our model generates the object geometry with a coarse-to-refine VecSet framework, which implements mesh simplification, cleaning, and normal baking on the GPU, and a fast parallel UV unwrapping. It then generates textures in a multi-view fashion, followed by backprojection and 3D inpainting. Model distillation, kernel optimization, and pipeline parallelization are co-designed to accelerate the system end-to-end. We introduce numerous automated and blind human evaluations and demonstrate competitive visual quality against leading commercial solutions in 30 seconds and preview-quality results in less than 15 seconds. The final result is a system that supports AI-assisted, deployable 3D content creation in interactive workflows.
AdaptManip: Learning Adaptive Whole-Body Object Lifting and Delivery with Online Recurrent State Estimation
Feb 16, 2026This paper presents Adaptive Whole-body Loco-Manipulation, AdaptManip, a fully autonomous framework for humanoid robots to perform integrated navigation, object lifting, and delivery. Unlike prior imitation learning-based approaches that rely on human demonstrations and are often brittle to disturbances, AdaptManip aims to train a robust loco-manipulation policy via reinforcement learning without human demonstrations or teleoperation data. The proposed framework consists of three coupled components: (1) a recurrent object state estimator that tracks the manipulated object in real time under limited field-of-view and occlusions; (2) a whole-body base policy for robust locomotion with residual manipulation control for stable object lifting and delivery; and (3) a LiDAR-based robot global position estimator that provides drift-robust localization. All components are trained in simulation using reinforcement learning and deployed on real hardware in a zero-shot manner. Experimental results show that AdaptManip significantly outperforms baseline methods, including imitation learning-based approaches, in adaptability and overall success rate, while accurate object state estimation improves manipulation performance even under occlusion. We further demonstrate fully autonomous real-world navigation, object lifting, and delivery on a humanoid robot.
AutoPartGen: Autogressive 3D Part Generation and Discovery
Jul 17, 2025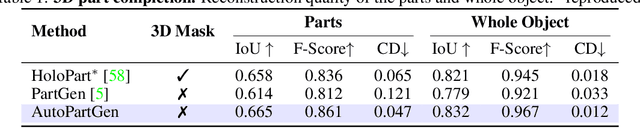
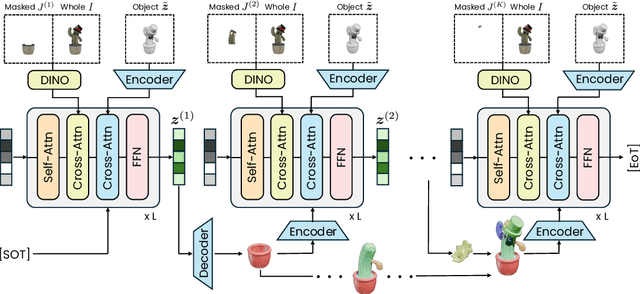

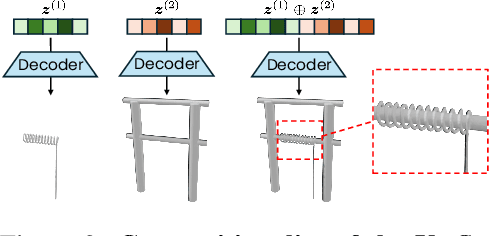
We introduce AutoPartGen, a model that generates objects composed of 3D parts in an autoregressive manner. This model can take as input an image of an object, 2D masks of the object's parts, or an existing 3D object, and generate a corresponding compositional 3D reconstruction. Our approach builds upon 3DShape2VecSet, a recent latent 3D representation with powerful geometric expressiveness. We observe that this latent space exhibits strong compositional properties, making it particularly well-suited for part-based generation tasks. Specifically, AutoPartGen generates object parts autoregressively, predicting one part at a time while conditioning on previously generated parts and additional inputs, such as 2D images, masks, or 3D objects. This process continues until the model decides that all parts have been generated, thus determining automatically the type and number of parts. The resulting parts can be seamlessly assembled into coherent objects or scenes without requiring additional optimization. We evaluate both the overall 3D generation capabilities and the part-level generation quality of AutoPartGen, demonstrating that it achieves state-of-the-art performance in 3D part generation.
PreCi: Pretraining and Continual Improvement of Humanoid Locomotion via Model-Assumption-Based Regularization
Apr 14, 2025
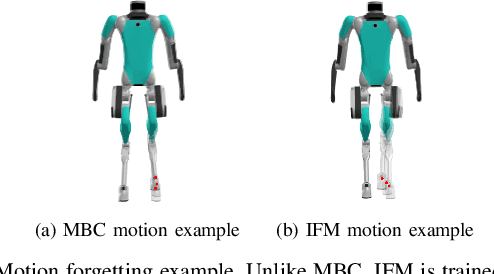
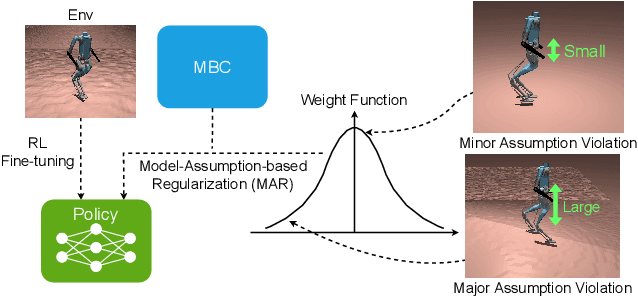

Humanoid locomotion is a challenging task due to its inherent complexity and high-dimensional dynamics, as well as the need to adapt to diverse and unpredictable environments. In this work, we introduce a novel learning framework for effectively training a humanoid locomotion policy that imitates the behavior of a model-based controller while extending its capabilities to handle more complex locomotion tasks, such as more challenging terrain and higher velocity commands. Our framework consists of three key components: pre-training through imitation of the model-based controller, fine-tuning via reinforcement learning, and model-assumption-based regularization (MAR) during fine-tuning. In particular, MAR aligns the policy with actions from the model-based controller only in states where the model assumption holds to prevent catastrophic forgetting. We evaluate the proposed framework through comprehensive simulation tests and hardware experiments on a full-size humanoid robot, Digit, demonstrating a forward speed of 1.5 m/s and robust locomotion across diverse terrains, including slippery, sloped, uneven, and sandy terrains.
Opt2Skill: Imitating Dynamically-feasible Whole-Body Trajectories for Versatile Humanoid Loco-Manipulation
Sep 30, 2024
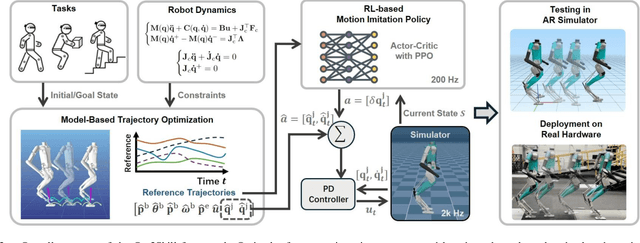
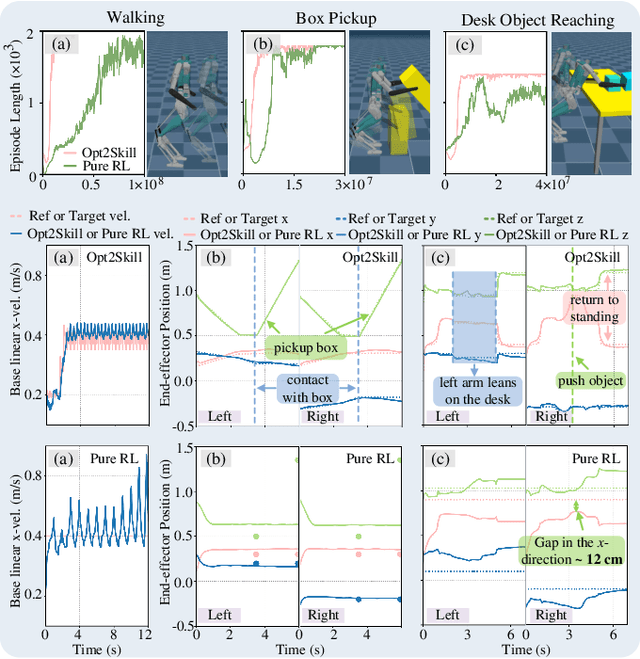
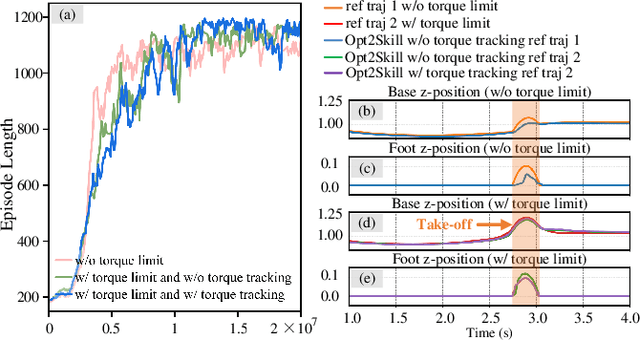
Humanoid robots are designed to perform diverse loco-manipulation tasks. However, they face challenges due to their high-dimensional and unstable dynamics, as well as the complex contact-rich nature of the tasks. Model-based optimal control methods offer precise and systematic control but are limited by high computational complexity and accurate contact sensing. On the other hand, reinforcement learning (RL) provides robustness and handles high-dimensional spaces but suffers from inefficient learning, unnatural motion, and sim-to-real gaps. To address these challenges, we introduce Opt2Skill, an end-to-end pipeline that combines model-based trajectory optimization with RL to achieve robust whole-body loco-manipulation. We generate reference motions for the Digit humanoid robot using differential dynamic programming (DDP) and train RL policies to track these trajectories. Our results demonstrate that Opt2Skill outperforms pure RL methods in both training efficiency and task performance, with optimal trajectories that account for torque limits enhancing trajectory tracking. We successfully transfer our approach to real-world applications.
Geometry Transfer for Stylizing Radiance Fields
Feb 02, 2024Shape and geometric patterns are essential in defining stylistic identity. However, current 3D style transfer methods predominantly focus on transferring colors and textures, often overlooking geometric aspects. In this paper, we introduce Geometry Transfer, a novel method that leverages geometric deformation for 3D style transfer. This technique employs depth maps to extract a style guide, subsequently applied to stylize the geometry of radiance fields. Moreover, we propose new techniques that utilize geometric cues from the 3D scene, thereby enhancing aesthetic expressiveness and more accurately reflecting intended styles. Our extensive experiments show that Geometry Transfer enables a broader and more expressive range of stylizations, thereby significantly expanding the scope of 3D style transfer.
Imitating and Finetuning Model Predictive Control for Robust and Symmetric Quadrupedal Locomotion
Nov 04, 2023



Control of legged robots is a challenging problem that has been investigated by different approaches, such as model-based control and learning algorithms. This work proposes a novel Imitating and Finetuning Model Predictive Control (IFM) framework to take the strengths of both approaches. Our framework first develops a conventional model predictive controller (MPC) using Differential Dynamic Programming and Raibert heuristic, which serves as an expert policy. Then we train a clone of the MPC using imitation learning to make the controller learnable. Finally, we leverage deep reinforcement learning with limited exploration for further finetuning the policy on more challenging terrains. By conducting comprehensive simulation and hardware experiments, we demonstrate that the proposed IFM framework can significantly improve the performance of the given MPC controller on rough, slippery, and conveyor terrains that require careful coordination of footsteps. We also showcase that IFM can efficiently produce more symmetric, periodic, and energy-efficient gaits compared to Vanilla RL with a minimal burden of reward shaping.
CrossLoco: Human Motion Driven Control of Legged Robots via Guided Unsupervised Reinforcement Learning
Sep 29, 2023Human motion driven control (HMDC) is an effective approach for generating natural and compelling robot motions while preserving high-level semantics. However, establishing the correspondence between humans and robots with different body structures is not straightforward due to the mismatches in kinematics and dynamics properties, which causes intrinsic ambiguity to the problem. Many previous algorithms approach this motion retargeting problem with unsupervised learning, which requires the prerequisite skill sets. However, it will be extremely costly to learn all the skills without understanding the given human motions, particularly for high-dimensional robots. In this work, we introduce CrossLoco, a guided unsupervised reinforcement learning framework that simultaneously learns robot skills and their correspondence to human motions. Our key innovation is to introduce a cycle-consistency-based reward term designed to maximize the mutual information between human motions and robot states. We demonstrate that the proposed framework can generate compelling robot motions by translating diverse human motions, such as running, hopping, and dancing. We quantitatively compare our CrossLoco against the manually engineered and unsupervised baseline algorithms along with the ablated versions of our framework and demonstrate that our method translates human motions with better accuracy, diversity, and user preference. We also showcase its utility in other applications, such as synthesizing robot movements from language input and enabling interactive robot control.
AnyFlow: Arbitrary Scale Optical Flow with Implicit Neural Representation
Mar 29, 2023



To apply optical flow in practice, it is often necessary to resize the input to smaller dimensions in order to reduce computational costs. However, downsizing inputs makes the estimation more challenging because objects and motion ranges become smaller. Even though recent approaches have demonstrated high-quality flow estimation, they tend to fail to accurately model small objects and precise boundaries when the input resolution is lowered, restricting their applicability to high-resolution inputs. In this paper, we introduce AnyFlow, a robust network that estimates accurate flow from images of various resolutions. By representing optical flow as a continuous coordinate-based representation, AnyFlow generates outputs at arbitrary scales from low-resolution inputs, demonstrating superior performance over prior works in capturing tiny objects with detail preservation on a wide range of scenes. We establish a new state-of-the-art performance of cross-dataset generalization on the KITTI dataset, while achieving comparable accuracy on the online benchmarks to other SOTA methods.
Fine-grained Semantics-aware Representation Enhancement for Self-supervised Monocular Depth Estimation
Aug 19, 2021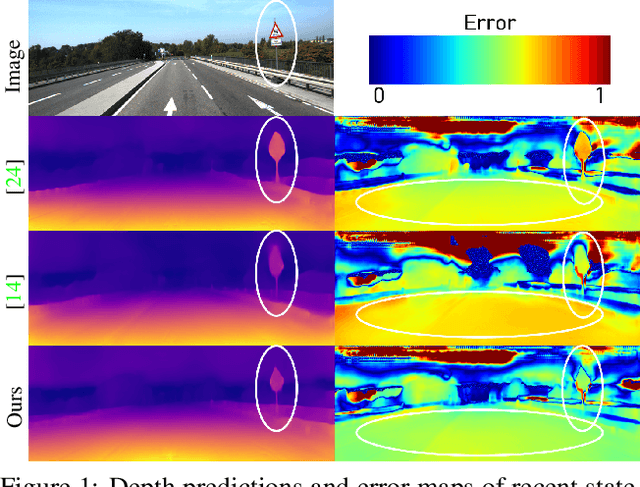
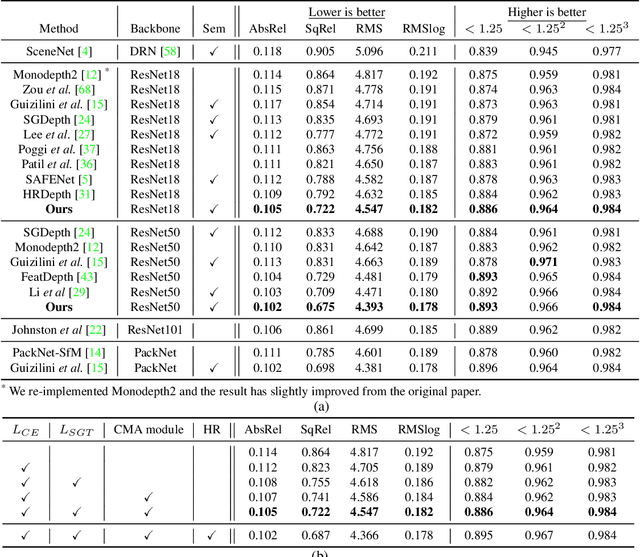
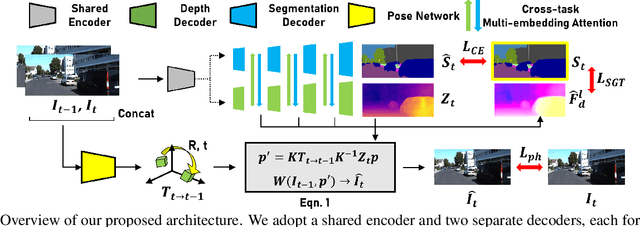
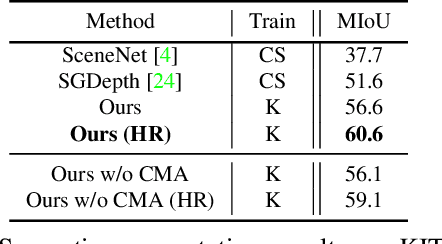
Self-supervised monocular depth estimation has been widely studied, owing to its practical importance and recent promising improvements. However, most works suffer from limited supervision of photometric consistency, especially in weak texture regions and at object boundaries. To overcome this weakness, we propose novel ideas to improve self-supervised monocular depth estimation by leveraging cross-domain information, especially scene semantics. We focus on incorporating implicit semantic knowledge into geometric representation enhancement and suggest two ideas: a metric learning approach that exploits the semantics-guided local geometry to optimize intermediate depth representations and a novel feature fusion module that judiciously utilizes cross-modality between two heterogeneous feature representations. We comprehensively evaluate our methods on the KITTI dataset and demonstrate that our method outperforms state-of-the-art methods. The source code is available at https://github.com/hyBlue/FSRE-Depth.