 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeculative Rollback Correction for Quality-Diverse Web Agent Imitation
Jun 10, 2026Training interactive web agents through imitation learning from expert trajectories has emerged as a highly effective approach. However, determining the optimal timing for expert intervention presents a critical challenge in this context. Delayed intervention often leads to the accumulation of early-stage errors, pushing the page state into an irrecoverable regime. Conversely, premature or excessive intervention causes the agent to become overly reliant on expert policies, trapping the model in local optima characterized by a single, rigid trajectory. We propose Speculative Rollback Correction (SRC), a branch-level imitation framework for resettable agent environments. Instead of requesting teacher labels at every visited state or correcting only after a completed trajectory, SRC uses fixed-horizon branch review: the student executes a short speculative segment before teacher review, and the teacher localizes the first harmful deviation only when local progress breaks. Rollback preserves useful prefixes, while successful rollouts are filtered by a hard verifier and retained in a lightweight quality-diversity archive. The resulting data supports next-action supervised fine-tuning on both localized corrections and verifier-passing trajectories. On WebArena-Infinity, SRC collects 977 verifier-passing trajectories and 9,183 next-action examples; fixed-horizon review improves the recovery-versus-query tradeoff over step-level review while retaining verifier-passing solution variants. Code is available at https://github.com/LongkunHao/SRC_gui_agent.
ARAPDiffusion: ARAP Regularization for Diffusion-Based Deformable Shape Space Learning
Jun 05, 2026This paper introduces ARAPDiffusion, a latent diffusion model to learn the underlying continuous shape space of a deformation shape collection. The key innovation is in injecting the as-rigid-as-possible (ARAP) deformation model as regularization losses into latent diffusion (LD), releasing the requirement of having abundant 3D training data for learning generative models. In contrast to the standard LD, we show how the ARAP model can be used to improve both the encoder/decoder and the LD model. The training procedure alternates between using the synthetic distribution defined by the LD model to develop a regularization loss that enhances the shape encoder/decoder and using the shape decoder to develop a regularization loss to improve the LD model. We also show the benefit of the LD paradigm in combining a representation-free LD process and an implicit shape decoder that is applicable to unorganized point clouds. The experimental results of unconditional and conditional shape generation demonstrate the advantages of ARAPDiffusion over baseline approaches.
WorldCoder-Bench: Benchmarking Physically Grounded 3D World Synthesis
Jun 01, 2026Large language models (LLMs) are increasingly asked not only to write static interfaces, but to construct executable interactive worlds from natural language. Browser-native 3D, commonly built with Three.js, is a natural next frontier: generated programs must integrate assets, obey spatial and physical constraints, and keep user-facing controls synchronized with hidden runtime state. Existing web-generation benchmarks and evaluators, however, largely observe only pixels or DOM nodes, while the mechanics of a Three.js world unfold inside an opaque <canvas>. We introduce WorldCoder-Bench, a benchmark for autonomous, physically grounded 3D world synthesis. WorldCoder-Bench contains 2,026 expert-curated tasks across Simulation, Rendering, and Application scenarios, with optional .glb assets and hidden behavioral contracts. We further propose StateProbe, an execution-based protocol that probes generated programs in a sandboxed browser and verifies hidden, mutation-hardened contracts over runtime states and transitions. Beyond verification coverage, we report Return on Automation and Time Efficiency Multiplier to measure correctness-adjusted cost and time savings. Across nine frontier models, the best system reaches only 27.8% verification coverage on WorldCoder-Core and 19.9% on WorldCoder-Robust, with failures dominated by state-schema drift and broken interaction chains rather than missing scene elements. Utility metrics further show that cheap or fast models can still provide substantial value on easier domains. WorldCoder-Bench is available at https://anonymous.4open.science/r/WorldCoder-Bench/.
DM0: An Embodied-Native Vision-Language-Action Model towards Physical AI
Feb 16, 2026Moving beyond the traditional paradigm of adapting internet-pretrained models to physical tasks, we present DM0, an Embodied-Native Vision-Language-Action (VLA) framework designed for Physical AI. Unlike approaches that treat physical grounding as a fine-tuning afterthought, DM0 unifies embodied manipulation and navigation by learning from heterogeneous data sources from the onset. Our methodology follows a comprehensive three-stage pipeline: Pretraining, Mid-Training, and Post-Training. First, we conduct large-scale unified pretraining on the Vision-Language Model (VLM) using diverse corpora--seamlessly integrating web text, autonomous driving scenarios, and embodied interaction logs-to jointly acquire semantic knowledge and physical priors. Subsequently, we build a flow-matching action expert atop the VLM. To reconcile high-level reasoning with low-level control, DM0 employs a hybrid training strategy: for embodied data, gradients from the action expert are not backpropagated to the VLM to preserve generalized representations, while the VLM remains trainable on non-embodied data. Furthermore, we introduce an Embodied Spatial Scaffolding strategy to construct spatial Chain-of-Thought (CoT) reasoning, effectively constraining the action solution space. Experiments on the RoboChallenge benchmark demonstrate that DM0 achieves state-of-the-art performance in both Specialist and Generalist settings on Table30.
LaVR: Scene Latent Conditioned Generative Video Trajectory Re-Rendering using Large 4D Reconstruction Models
Jan 21, 2026Given a monocular video, the goal of video re-rendering is to generate views of the scene from a novel camera trajectory. Existing methods face two distinct challenges. Geometrically unconditioned models lack spatial awareness, leading to drift and deformation under viewpoint changes. On the other hand, geometrically-conditioned models depend on estimated depth and explicit reconstruction, making them susceptible to depth inaccuracies and calibration errors. We propose to address these challenges by using the implicit geometric knowledge embedded in the latent space of a large 4D reconstruction model to condition the video generation process. These latents capture scene structure in a continuous space without explicit reconstruction. Therefore, they provide a flexible representation that allows the pretrained diffusion prior to regularize errors more effectively. By jointly conditioning on these latents and source camera poses, we demonstrate that our model achieves state-of-the-art results on the video re-rendering task. Project webpage is https://lavr-4d-scene-rerender.github.io/
Atlas Gaussians Diffusion for 3D Generation with Infinite Number of Points
Aug 23, 2024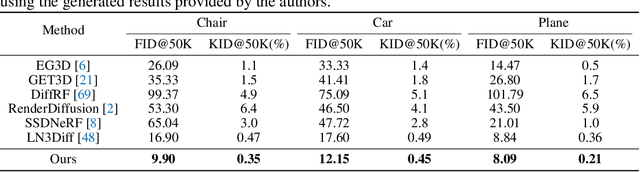
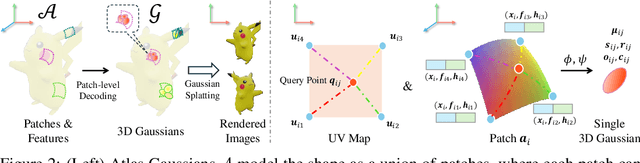
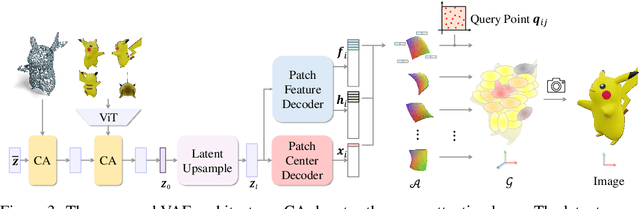
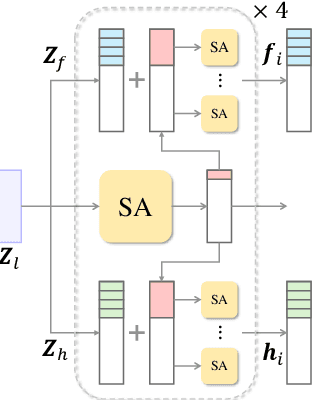
Using the latent diffusion model has proven effective in developing novel 3D generation techniques. To harness the latent diffusion model, a key challenge is designing a high-fidelity and efficient representation that links the latent space and the 3D space. In this paper, we introduce Atlas Gaussians, a novel representation for feed-forward native 3D generation. Atlas Gaussians represent a shape as the union of local patches, and each patch can decode 3D Gaussians. We parameterize a patch as a sequence of feature vectors and design a learnable function to decode 3D Gaussians from the feature vectors. In this process, we incorporate UV-based sampling, enabling the generation of a sufficiently large, and theoretically infinite, number of 3D Gaussian points. The large amount of 3D Gaussians enables high-quality details of generation results. Moreover, due to local awareness of the representation, the transformer-based decoding procedure operates on a patch level, ensuring efficiency. We train a variational autoencoder to learn the Atlas Gaussians representation, and then apply a latent diffusion model on its latent space for learning 3D Generation. Experiments show that our approach outperforms the prior arts of feed-forward native 3D generation.
4DRecons: 4D Neural Implicit Deformable Objects Reconstruction from a single RGB-D Camera with Geometrical and Topological Regularizations
Jun 14, 2024



This paper presents a novel approach 4DRecons that takes a single camera RGB-D sequence of a dynamic subject as input and outputs a complete textured deforming 3D model over time. 4DRecons encodes the output as a 4D neural implicit surface and presents an optimization procedure that combines a data term and two regularization terms. The data term fits the 4D implicit surface to the input partial observations. We address fundamental challenges in fitting a complete implicit surface to partial observations. The first regularization term enforces that the deformation among adjacent frames is as rigid as possible (ARAP). To this end, we introduce a novel approach to compute correspondences between adjacent textured implicit surfaces, which are used to define the ARAP regularization term. The second regularization term enforces that the topology of the underlying object remains fixed over time. This regularization is critical for avoiding self-intersections that are typical in implicit-based reconstructions. We have evaluated the performance of 4DRecons on a variety of datasets. Experimental results show that 4DRecons can handle large deformations and complex inter-part interactions and outperform state-of-the-art approaches considerably.
TIM: Temporal Interaction Model in Notification System
Jun 11, 2024



Modern mobile applications heavily rely on the notification system to acquire daily active users and enhance user engagement. Being able to proactively reach users, the system has to decide when to send notifications to users. Although many researchers have studied optimizing the timing of sending notifications, they only utilized users' contextual features, without modeling users' behavior patterns. Additionally, these efforts only focus on individual notifications, and there is a lack of studies on optimizing the holistic timing of multiple notifications within a period. To bridge these gaps, we propose the Temporal Interaction Model (TIM), which models users' behavior patterns by estimating CTR in every time slot over a day in our short video application Kuaishou. TIM leverages long-term user historical interaction sequence features such as notification receipts, clicks, watch time and effective views, and employs a temporal attention unit (TAU) to extract user behavior patterns. Moreover, we provide an elegant strategy of holistic notifications send time control to improve user engagement while minimizing disruption. We evaluate the effectiveness of TIM through offline experiments and online A/B tests. The results indicate that TIM is a reliable tool for forecasting user behavior, leading to a remarkable enhancement in user engagement without causing undue disturbance.
CoFie: Learning Compact Neural Surface Representations with Coordinate Fields
Jun 05, 2024



This paper introduces CoFie, a novel local geometry-aware neural surface representation. CoFie is motivated by the theoretical analysis of local SDFs with quadratic approximation. We find that local shapes are highly compressive in an aligned coordinate frame defined by the normal and tangent directions of local shapes. Accordingly, we introduce Coordinate Field, which is a composition of coordinate frames of all local shapes. The Coordinate Field is optimizable and is used to transform the local shapes from the world coordinate frame to the aligned shape coordinate frame. It largely reduces the complexity of local shapes and benefits the learning of MLP-based implicit representations. Moreover, we introduce quadratic layers into the MLP to enhance expressiveness concerning local shape geometry. CoFie is a generalizable surface representation. It is trained on a curated set of 3D shapes and works on novel shape instances during testing. When using the same amount of parameters with prior works, CoFie reduces the shape error by 48% and 56% on novel instances of both training and unseen shape categories. Moreover, CoFie demonstrates comparable performance to prior works when using only 70% fewer parameters.
Query-dominant User Interest Network for Large-Scale Search Ranking
Oct 10, 2023



Historical behaviors have shown great effect and potential in various prediction tasks, including recommendation and information retrieval. The overall historical behaviors are various but noisy while search behaviors are always sparse. Most existing approaches in personalized search ranking adopt the sparse search behaviors to learn representation with bottleneck, which do not sufficiently exploit the crucial long-term interest. In fact, there is no doubt that user long-term interest is various but noisy for instant search, and how to exploit it well still remains an open problem. To tackle this problem, in this work, we propose a novel model named Query-dominant user Interest Network (QIN), including two cascade units to filter the raw user behaviors and reweigh the behavior subsequences. Specifically, we propose a relevance search unit (RSU), which aims to search a subsequence relevant to the query first and then search the sub-subsequences relevant to the target item. These items are then fed into an attention unit called Fused Attention Unit (FAU). It should be able to calculate attention scores from the ID field and attribute field separately, and then adaptively fuse the item embedding and content embedding based on the user engagement of past period. Extensive experiments and ablation studies on real-world datasets demonstrate the superiority of our model over state-of-the-art methods. The QIN now has been successfully deployed on Kuaishou search, an online video search platform, and obtained 7.6% improvement on CTR.