 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushGen: Push Notifications Generation with LLM
Dec 16, 2025
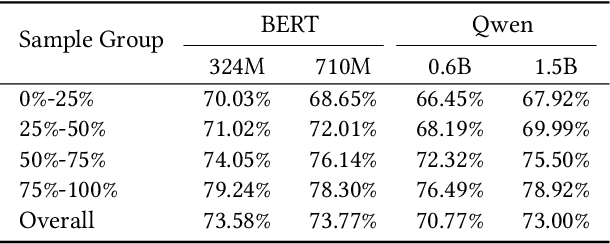

We present PushGen, an automated framework for generating high-quality push notifications comparable to human-crafted content. With the rise of generative models, there is growing interest in leveraging LLMs for push content generation. Although LLMs make content generation straightforward and cost-effective, maintaining stylistic control and reliable quality assessment remains challenging, as both directly impact user engagement. To address these issues, PushGen combines two key components: (1) a controllable category prompt technique to guide LLM outputs toward desired styles, and (2) a reward model that ranks and selects generated candidates. Extensive offline and online experiments demonstrate its effectiveness, which has been deployed in large-scale industrial applications, serving hundreds of millions of users daily.
TIM: Temporal Interaction Model in Notification System
Jun 11, 2024



Modern mobile applications heavily rely on the notification system to acquire daily active users and enhance user engagement. Being able to proactively reach users, the system has to decide when to send notifications to users. Although many researchers have studied optimizing the timing of sending notifications, they only utilized users' contextual features, without modeling users' behavior patterns. Additionally, these efforts only focus on individual notifications, and there is a lack of studies on optimizing the holistic timing of multiple notifications within a period. To bridge these gaps, we propose the Temporal Interaction Model (TIM), which models users' behavior patterns by estimating CTR in every time slot over a day in our short video application Kuaishou. TIM leverages long-term user historical interaction sequence features such as notification receipts, clicks, watch time and effective views, and employs a temporal attention unit (TAU) to extract user behavior patterns. Moreover, we provide an elegant strategy of holistic notifications send time control to improve user engagement while minimizing disruption. We evaluate the effectiveness of TIM through offline experiments and online A/B tests. The results indicate that TIM is a reliable tool for forecasting user behavior, leading to a remarkable enhancement in user engagement without causing undue disturbance.
Query-dominant User Interest Network for Large-Scale Search Ranking
Oct 10, 2023



Historical behaviors have shown great effect and potential in various prediction tasks, including recommendation and information retrieval. The overall historical behaviors are various but noisy while search behaviors are always sparse. Most existing approaches in personalized search ranking adopt the sparse search behaviors to learn representation with bottleneck, which do not sufficiently exploit the crucial long-term interest. In fact, there is no doubt that user long-term interest is various but noisy for instant search, and how to exploit it well still remains an open problem. To tackle this problem, in this work, we propose a novel model named Query-dominant user Interest Network (QIN), including two cascade units to filter the raw user behaviors and reweigh the behavior subsequences. Specifically, we propose a relevance search unit (RSU), which aims to search a subsequence relevant to the query first and then search the sub-subsequences relevant to the target item. These items are then fed into an attention unit called Fused Attention Unit (FAU). It should be able to calculate attention scores from the ID field and attribute field separately, and then adaptively fuse the item embedding and content embedding based on the user engagement of past period. Extensive experiments and ablation studies on real-world datasets demonstrate the superiority of our model over state-of-the-art methods. The QIN now has been successfully deployed on Kuaishou search, an online video search platform, and obtained 7.6% improvement on CTR.
Modality-Balanced Embedding for Video Retrieval
Apr 18, 2022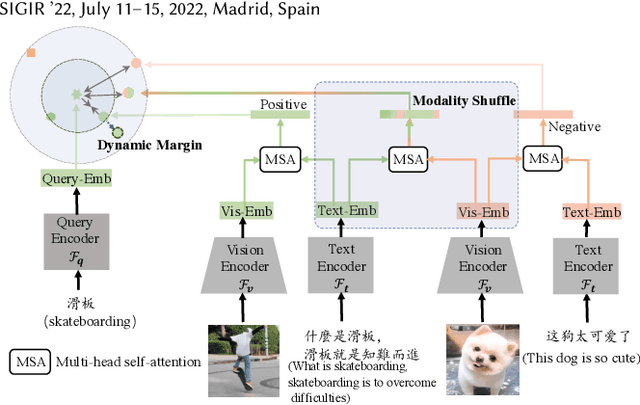
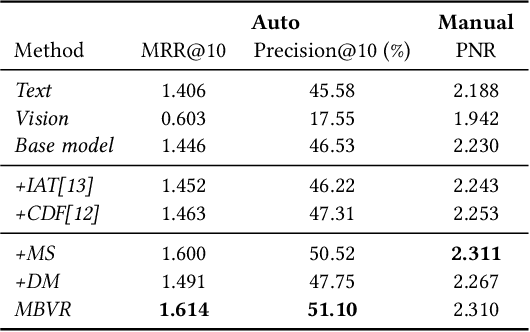
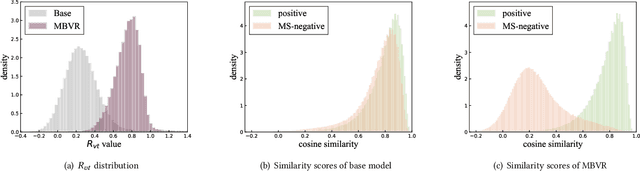
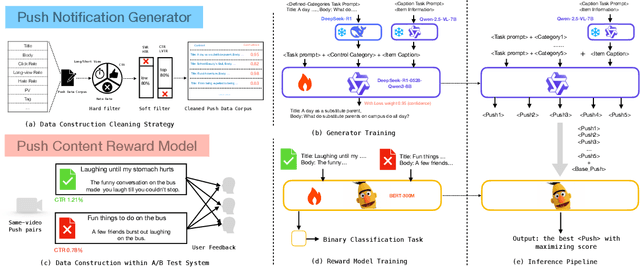
Video search has become the main routine for users to discover videos relevant to a text query on large short-video sharing platforms. During training a query-video bi-encoder model using online search logs, we identify a modality bias phenomenon that the video encoder almost entirely relies on text matching, neglecting other modalities of the videos such as vision, audio. This modality imbalanceresults from a) modality gap: the relevance between a query and a video text is much easier to learn as the query is also a piece of text, with the same modality as the video text; b) data bias: most training samples can be solved solely by text matching. Here we share our practices to improve the first retrieval stage including our solution for the modality imbalance issue. We propose MBVR (short for Modality Balanced Video Retrieval) with two key components: manually generated modality-shuffled (MS) samples and a dynamic margin (DM) based on visual relevance. They can encourage the video encoder to pay balanced attentions to each modality. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving modality bias problem. We have also deployed our MBVR in a large video platform and observed statistically significant boost over a highly optimized baseline in an A/B test and manual GSB evaluations.
* Accepted by SIGIR-2022, short paper
Contrastive Learning for Cold-Start Recommendation
Jul 15, 2021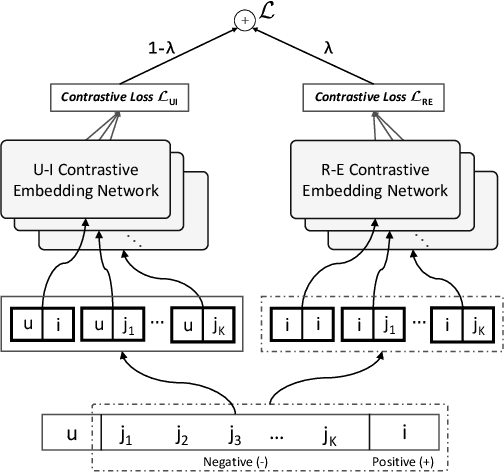
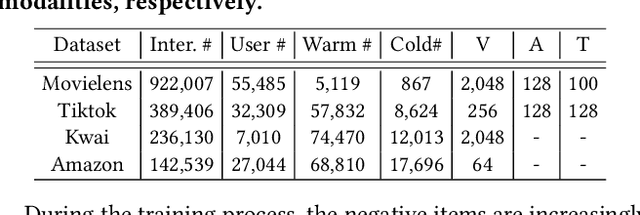
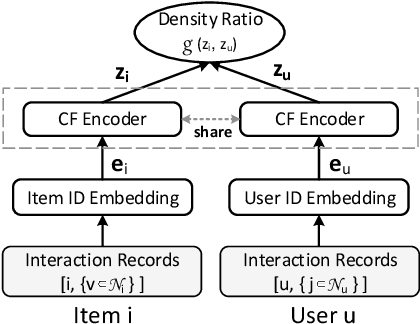
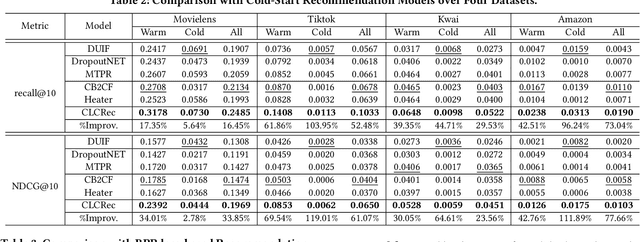
Recommending cold-start items is a long-standing and fundamental challenge in recommender systems. Without any historical interaction on cold-start items, CF scheme fails to use collaborative signals to infer user preference on these items. To solve this problem, extensive studies have been conducted to incorporate side information into the CF scheme. Specifically, they employ modern neural network techniques (e.g., dropout, consistency constraint) to discover and exploit the coalition effect of content features and collaborative representations. However, we argue that these works less explore the mutual dependencies between content features and collaborative representations and lack sufficient theoretical supports, thus resulting in unsatisfactory performance. In this work, we reformulate the cold-start item representation learning from an information-theoretic standpoint. It aims to maximize the mutual dependencies between item content and collaborative signals. Specifically, the representation learning is theoretically lower-bounded by the integration of two terms: mutual information between collaborative embeddings of users and items, and mutual information between collaborative embeddings and feature representations of items. To model such a learning process, we devise a new objective function founded upon contrastive learning and develop a simple yet effective Contrastive Learning-based Cold-start Recommendation framework(CLCRec). In particular, CLCRec consists of three components: contrastive pair organization, contrastive embedding, and contrastive optimization modules. It allows us to preserve collaborative signals in the content representations for both warm and cold-start items. Through extensive experiments on four publicly accessible datasets, we observe that CLCRec achieves significant improvements over state-of-the-art approaches in both warm- and cold-start scenarios.