 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-dominant User Interest Network for Large-Scale Search Ranking
Oct 10, 2023



Historical behaviors have shown great effect and potential in various prediction tasks, including recommendation and information retrieval. The overall historical behaviors are various but noisy while search behaviors are always sparse. Most existing approaches in personalized search ranking adopt the sparse search behaviors to learn representation with bottleneck, which do not sufficiently exploit the crucial long-term interest. In fact, there is no doubt that user long-term interest is various but noisy for instant search, and how to exploit it well still remains an open problem. To tackle this problem, in this work, we propose a novel model named Query-dominant user Interest Network (QIN), including two cascade units to filter the raw user behaviors and reweigh the behavior subsequences. Specifically, we propose a relevance search unit (RSU), which aims to search a subsequence relevant to the query first and then search the sub-subsequences relevant to the target item. These items are then fed into an attention unit called Fused Attention Unit (FAU). It should be able to calculate attention scores from the ID field and attribute field separately, and then adaptively fuse the item embedding and content embedding based on the user engagement of past period. Extensive experiments and ablation studies on real-world datasets demonstrate the superiority of our model over state-of-the-art methods. The QIN now has been successfully deployed on Kuaishou search, an online video search platform, and obtained 7.6% improvement on CTR.
Modality-Balanced Embedding for Video Retrieval
Apr 18, 2022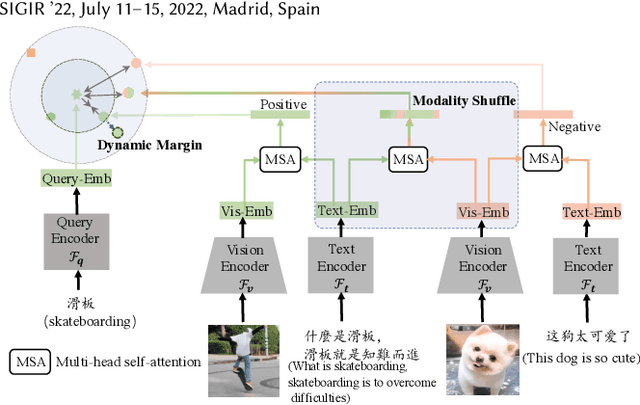
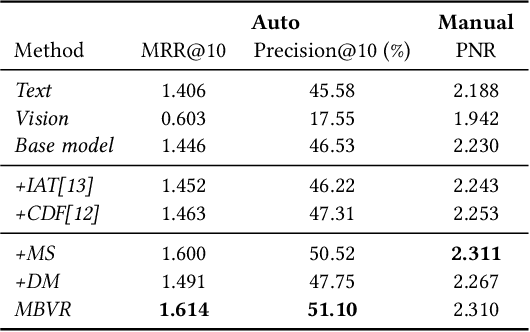
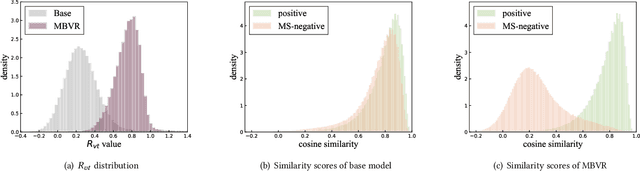
Video search has become the main routine for users to discover videos relevant to a text query on large short-video sharing platforms. During training a query-video bi-encoder model using online search logs, we identify a modality bias phenomenon that the video encoder almost entirely relies on text matching, neglecting other modalities of the videos such as vision, audio. This modality imbalanceresults from a) modality gap: the relevance between a query and a video text is much easier to learn as the query is also a piece of text, with the same modality as the video text; b) data bias: most training samples can be solved solely by text matching. Here we share our practices to improve the first retrieval stage including our solution for the modality imbalance issue. We propose MBVR (short for Modality Balanced Video Retrieval) with two key components: manually generated modality-shuffled (MS) samples and a dynamic margin (DM) based on visual relevance. They can encourage the video encoder to pay balanced attentions to each modality. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving modality bias problem. We have also deployed our MBVR in a large video platform and observed statistically significant boost over a highly optimized baseline in an A/B test and manual GSB evaluations.
* Accepted by SIGIR-2022, short paper