 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSID-Coord: Coordinating Semantic IDs for ID-based Ranking in Short-Video Search
Apr 12, 2026Large-scale short-video search ranking models are typically trained on sparse co-occurrence signals over hashed item identifiers (HIDs). While effective at memorizing frequent interactions, such ID-based models struggle to generalize to long-tailed items with limited exposure. This memorization-generalization trade-off remains a longstanding challenge in such industrial systems. We propose SID-Coord, a lightweight Semantic ID framework that incorporates discrete, trainable semantic IDs (SIDs) directly into ID-based ranking models. Instead of treating semantic signals as auxiliary dense features, SID-Coord represents semantics as structured identifiers and coordinates HID-based memorization with SID-based generalization within a unified modeling framework. To enable effective coordination, SID-Coord introduces three components: (1) an attention-based fusion module over hierarchical SIDs to capture multi-level semantics, (2) a target-aware HID-SID gating mechanism that adaptively balances memorization and generalization, and (3) a SID-driven interest alignment module that models the semantic similarity distribution between target items and user histories. SID-Coord can be integrated into existing production ranking systems without modifying the backbone model. Online A/B experiments in a real-world production environment show statistically significant improvements, with a +0.664% gain in long-play rate in search and a +0.369% increase in search playback duration.
Unconstrained Monotonic Calibration of Predictions in Deep Ranking Systems
Apr 19, 2025Ranking models primarily focus on modeling the relative order of predictions while often neglecting the significance of the accuracy of their absolute values. However, accurate absolute values are essential for certain downstream tasks, necessitating the calibration of the original predictions. To address this, existing calibration approaches typically employ predefined transformation functions with order-preserving properties to adjust the original predictions. Unfortunately, these functions often adhere to fixed forms, such as piece-wise linear functions, which exhibit limited expressiveness and flexibility, thereby constraining their effectiveness in complex calibration scenarios. To mitigate this issue, we propose implementing a calibrator using an Unconstrained Monotonic Neural Network (UMNN), which can learn arbitrary monotonic functions with great modeling power. This approach significantly relaxes the constraints on the calibrator, improving its flexibility and expressiveness while avoiding excessively distorting the original predictions by requiring monotonicity. Furthermore, to optimize this highly flexible network for calibration, we introduce a novel additional loss function termed Smooth Calibration Loss (SCLoss), which aims to fulfill a necessary condition for achieving the ideal calibration state. Extensive offline experiments confirm the effectiveness of our method in achieving superior calibration performance. Moreover, deployment in Kuaishou's large-scale online video ranking system demonstrates that the method's calibration improvements translate into enhanced business metrics. The source code is available at https://github.com/baiyimeng/UMC.
Beyond Relevance: Improving User Engagement by Personalization for Short-Video Search
Sep 17, 2024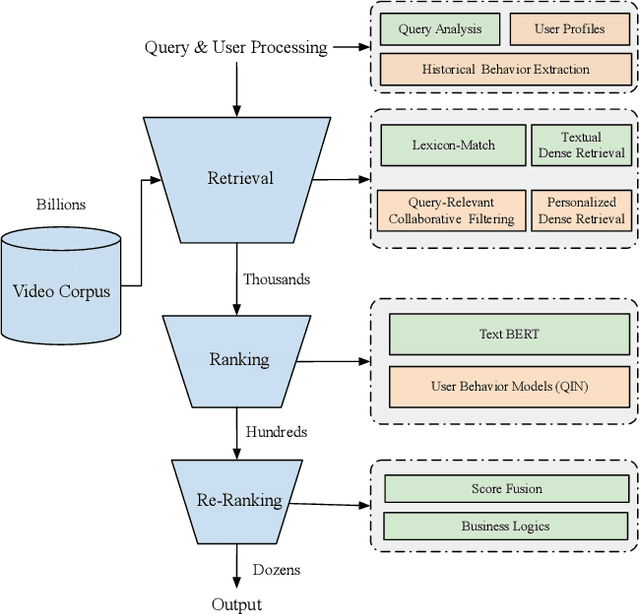
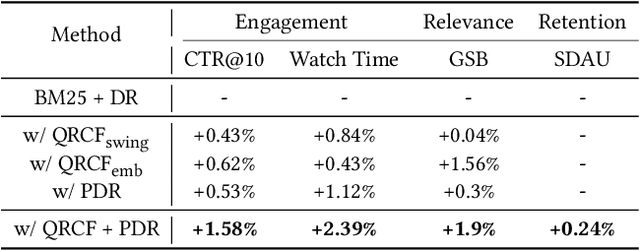
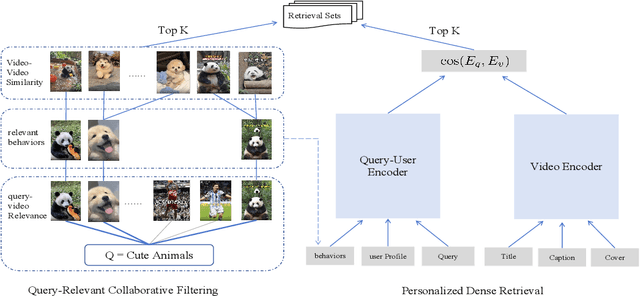
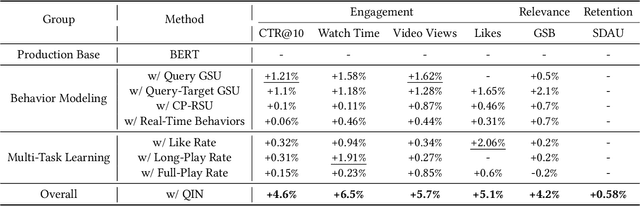
Personalized search has been extensively studied in various applications, including web search, e-commerce, social networks, etc. With the soaring popularity of short-video platforms, exemplified by TikTok and Kuaishou, the question arises: can personalization elevate the realm of short-video search, and if so, which techniques hold the key? In this work, we introduce $\text{PR}^2$, a novel and comprehensive solution for personalizing short-video search, where $\text{PR}^2$ stands for the Personalized Retrieval and Ranking augmented search system. Specifically, $\text{PR}^2$ leverages query-relevant collaborative filtering and personalized dense retrieval to extract relevant and individually tailored content from a large-scale video corpus. Furthermore, it utilizes the QIN (Query-Dominate User Interest Network) ranking model, to effectively harness user long-term preferences and real-time behaviors, and efficiently learn from user various implicit feedback through a multi-task learning framework. By deploying the $\text{PR}^2$ in production system, we have achieved the most remarkable user engagement improvements in recent years: a 10.2% increase in CTR@10, a notable 20% surge in video watch time, and a 1.6% uplift of search DAU. We believe the practical insights presented in this work are valuable especially for building and improving personalized search systems for the short video platforms.
A Self-boosted Framework for Calibrated Ranking
Jun 12, 2024



Scale-calibrated ranking systems are ubiquitous in real-world applications nowadays, which pursue accurate ranking quality and calibrated probabilistic predictions simultaneously. For instance, in the advertising ranking system, the predicted click-through rate (CTR) is utilized for ranking and required to be calibrated for the downstream cost-per-click ads bidding. Recently, multi-objective based methods have been wildly adopted as a standard approach for Calibrated Ranking, which incorporates the combination of two loss functions: a pointwise loss that focuses on calibrated absolute values and a ranking loss that emphasizes relative orderings. However, when applied to industrial online applications, existing multi-objective CR approaches still suffer from two crucial limitations. First, previous methods need to aggregate the full candidate list within a single mini-batch to compute the ranking loss. Such aggregation strategy violates extensive data shuffling which has long been proven beneficial for preventing overfitting, and thus degrades the training effectiveness. Second, existing multi-objective methods apply the two inherently conflicting loss functions on a single probabilistic prediction, which results in a sub-optimal trade-off between calibration and ranking. To tackle the two limitations, we propose a Self-Boosted framework for Calibrated Ranking (SBCR).
TIM: Temporal Interaction Model in Notification System
Jun 11, 2024



Modern mobile applications heavily rely on the notification system to acquire daily active users and enhance user engagement. Being able to proactively reach users, the system has to decide when to send notifications to users. Although many researchers have studied optimizing the timing of sending notifications, they only utilized users' contextual features, without modeling users' behavior patterns. Additionally, these efforts only focus on individual notifications, and there is a lack of studies on optimizing the holistic timing of multiple notifications within a period. To bridge these gaps, we propose the Temporal Interaction Model (TIM), which models users' behavior patterns by estimating CTR in every time slot over a day in our short video application Kuaishou. TIM leverages long-term user historical interaction sequence features such as notification receipts, clicks, watch time and effective views, and employs a temporal attention unit (TAU) to extract user behavior patterns. Moreover, we provide an elegant strategy of holistic notifications send time control to improve user engagement while minimizing disruption. We evaluate the effectiveness of TIM through offline experiments and online A/B tests. The results indicate that TIM is a reliable tool for forecasting user behavior, leading to a remarkable enhancement in user engagement without causing undue disturbance.
Query-dominant User Interest Network for Large-Scale Search Ranking
Oct 10, 2023



Historical behaviors have shown great effect and potential in various prediction tasks, including recommendation and information retrieval. The overall historical behaviors are various but noisy while search behaviors are always sparse. Most existing approaches in personalized search ranking adopt the sparse search behaviors to learn representation with bottleneck, which do not sufficiently exploit the crucial long-term interest. In fact, there is no doubt that user long-term interest is various but noisy for instant search, and how to exploit it well still remains an open problem. To tackle this problem, in this work, we propose a novel model named Query-dominant user Interest Network (QIN), including two cascade units to filter the raw user behaviors and reweigh the behavior subsequences. Specifically, we propose a relevance search unit (RSU), which aims to search a subsequence relevant to the query first and then search the sub-subsequences relevant to the target item. These items are then fed into an attention unit called Fused Attention Unit (FAU). It should be able to calculate attention scores from the ID field and attribute field separately, and then adaptively fuse the item embedding and content embedding based on the user engagement of past period. Extensive experiments and ablation studies on real-world datasets demonstrate the superiority of our model over state-of-the-art methods. The QIN now has been successfully deployed on Kuaishou search, an online video search platform, and obtained 7.6% improvement on CTR.
Modeling Sequential Sentence Relation to Improve Cross-lingual Dense Retrieval
Feb 03, 2023Recently multi-lingual pre-trained language models (PLM) such as mBERT and XLM-R have achieved impressive strides in cross-lingual dense retrieval. Despite its successes, they are general-purpose PLM while the multilingual PLM tailored for cross-lingual retrieval is still unexplored. Motivated by an observation that the sentences in parallel documents are approximately in the same order, which is universal across languages, we propose to model this sequential sentence relation to facilitate cross-lingual representation learning. Specifically, we propose a multilingual PLM called masked sentence model (MSM), which consists of a sentence encoder to generate the sentence representations, and a document encoder applied to a sequence of sentence vectors from a document. The document encoder is shared for all languages to model the universal sequential sentence relation across languages. To train the model, we propose a masked sentence prediction task, which masks and predicts the sentence vector via a hierarchical contrastive loss with sampled negatives. Comprehensive experiments on four cross-lingual retrieval tasks show MSM significantly outperforms existing advanced pre-training models, demonstrating the effectiveness and stronger cross-lingual retrieval capabilities of our approach. Code and model will be available.
Reasoning with Multi-Structure Commonsense Knowledge in Visual Dialog
Apr 10, 2022
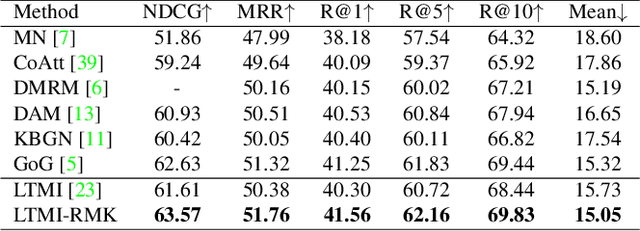
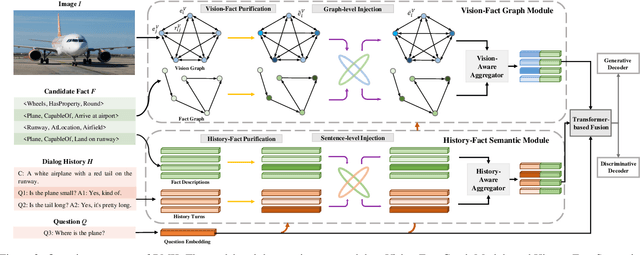
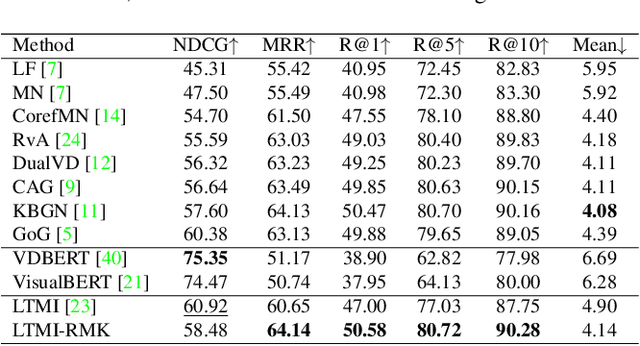
Visual Dialog requires an agent to engage in a conversation with humans grounded in an image. Many studies on Visual Dialog focus on the understanding of the dialog history or the content of an image, while a considerable amount of commonsense-required questions are ignored. Handling these scenarios depends on logical reasoning that requires commonsense priors. How to capture relevant commonsense knowledge complementary to the history and the image remains a key challenge. In this paper, we propose a novel model by Reasoning with Multi-structure Commonsense Knowledge (RMK). In our model, the external knowledge is represented with sentence-level facts and graph-level facts, to properly suit the scenario of the composite of dialog history and image. On top of these multi-structure representations, our model can capture relevant knowledge and incorporate them into the vision and semantic features, via graph-based interaction and transformer-based fusion. Experimental results and analysis on VisDial v1.0 and VisDialCK datasets show that our proposed model effectively outperforms comparative methods.
Multi-View Document Representation Learning for Open-Domain Dense Retrieval
Mar 16, 2022


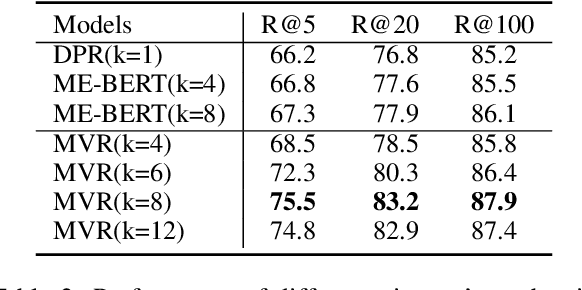
Dense retrieval has achieved impressive advances in first-stage retrieval from a large-scale document collection, which is built on bi-encoder architecture to produce single vector representation of query and document. However, a document can usually answer multiple potential queries from different views. So the single vector representation of a document is hard to match with multi-view queries, and faces a semantic mismatch problem. This paper proposes a multi-view document representation learning framework, aiming to produce multi-view embeddings to represent documents and enforce them to align with different queries. First, we propose a simple yet effective method of generating multiple embeddings through viewers. Second, to prevent multi-view embeddings from collapsing to the same one, we further propose a global-local loss with annealed temperature to encourage the multiple viewers to better align with different potential queries. Experiments show our method outperforms recent works and achieves state-of-the-art results.