 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaTree: Structured Lifecycle Memory for Person Understanding in LLM Agents
Jun 03, 2026Persistent LLM agents require memory representations that make the formation of person understanding explicit across long term interaction. Existing agent memory methods emphasize information retention and retrieval, yet give limited account of how accumulated interaction evidence is abstracted into person understanding. We view this process as schema formation, where situated evidence is abstracted into reusable patterns and stable person level claims. We introduce PersonaTree, a structured lifecycle memory framework that realizes this view as a three level persona tree with explicit support paths from evidence to claims. PersonaTree maintains the tree through conservative writing, confidence guided consolidation, and query conditioned path retrieval, returning only the evidence depth required by each query. Across six person understanding and persistent memory benchmarks with three answer backbones, PersonaTree ranks first in 12 of 18 compact scores and reaches the top two in 16 settings. Ablations show that hierarchy improves abstract person understanding on KnowMe, while support path retrieval improves RealPref alignment under a comparable context budget.
Reasoning with Multi-Structure Commonsense Knowledge in Visual Dialog
Apr 10, 2022
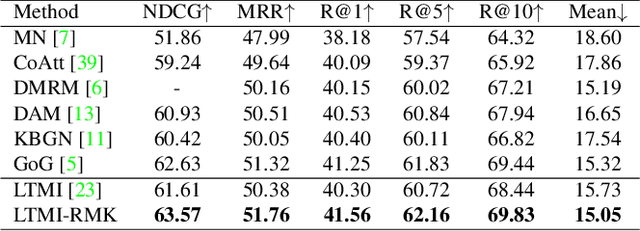
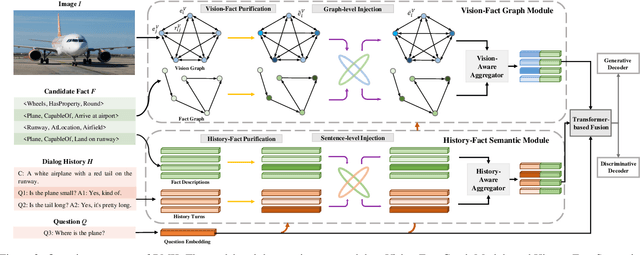
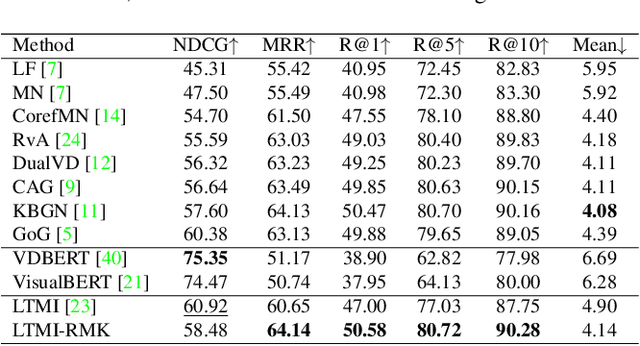
Visual Dialog requires an agent to engage in a conversation with humans grounded in an image. Many studies on Visual Dialog focus on the understanding of the dialog history or the content of an image, while a considerable amount of commonsense-required questions are ignored. Handling these scenarios depends on logical reasoning that requires commonsense priors. How to capture relevant commonsense knowledge complementary to the history and the image remains a key challenge. In this paper, we propose a novel model by Reasoning with Multi-structure Commonsense Knowledge (RMK). In our model, the external knowledge is represented with sentence-level facts and graph-level facts, to properly suit the scenario of the composite of dialog history and image. On top of these multi-structure representations, our model can capture relevant knowledge and incorporate them into the vision and semantic features, via graph-based interaction and transformer-based fusion. Experimental results and analysis on VisDial v1.0 and VisDialCK datasets show that our proposed model effectively outperforms comparative methods.
A sequential guiding network with attention for image captioning
Nov 01, 2018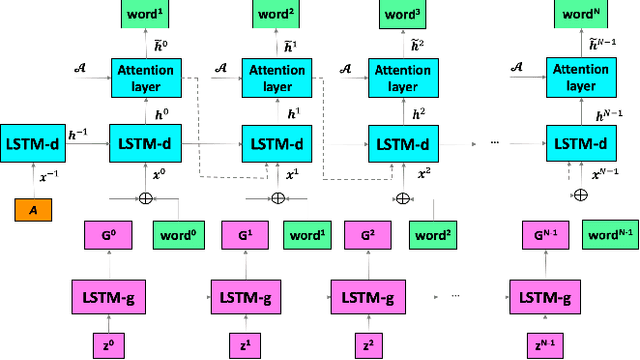
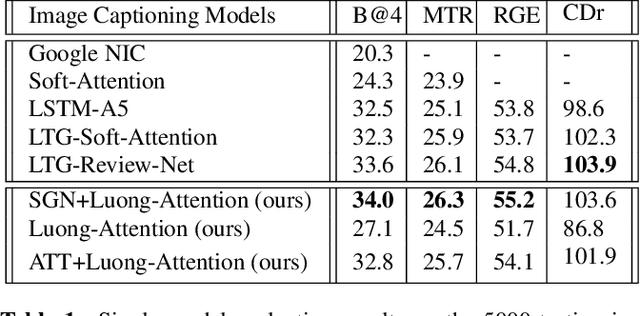
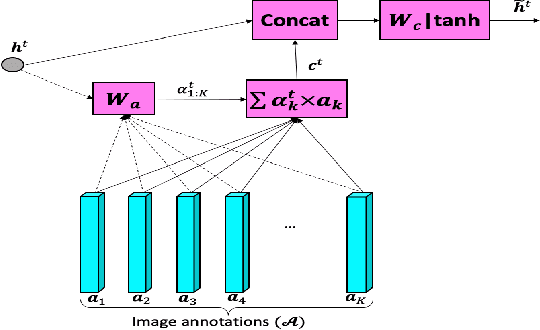
The recent advances of deep learning in both computer vision (CV)and natural language processing (NLP) provide us a new way of un-derstanding semantics, by which we can deal with more challeng-ing tasks such as automatic description generation from natural im-ages. In this challenge, the encoder-decoder framework has achievedpromising performance when a convolutional neural network (CNN)is used as image encoder and a recurrent neural network (RNN) asdecoder. In this paper, we introduce a sequential guiding networkthat guides the decoder during word generation. The new model is anextension of the encoder-decoder framework with attention that hasan additional guiding long short-term memory (LSTM) and can betrained in an end-to-end manner by using image/descriptions pairs.We validate our approach by conducting extensive experiments on abenchmark dataset, i.e., MS COCO Captions. The proposed model achieves significant improvement comparing to the other state-of-the-art deep learning models.
Pixel Level Data Augmentation for Semantic Image Segmentation using Generative Adversarial Networks
Nov 01, 2018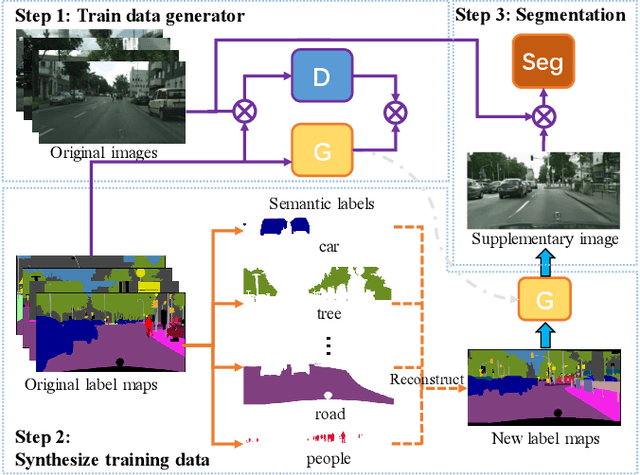

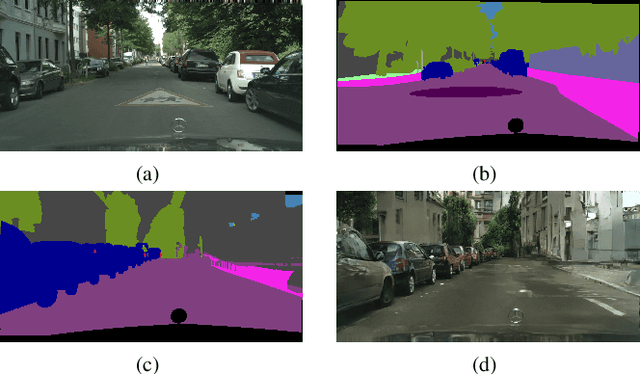
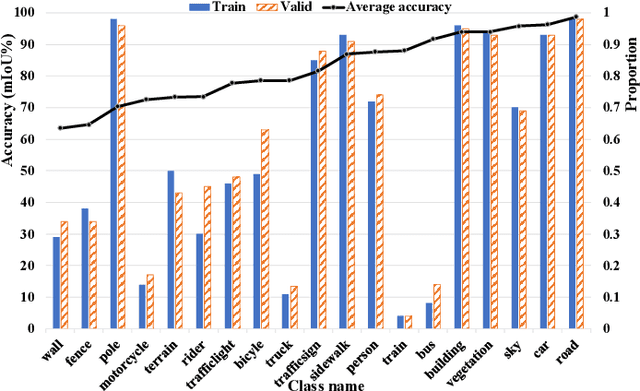
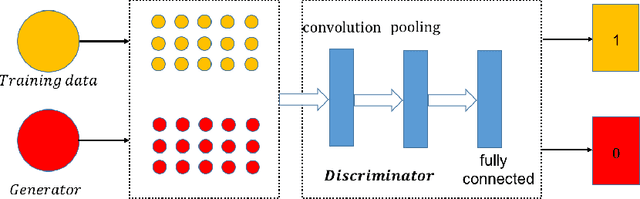
Semantic segmentation is one of the basic topics in computer vision, it aims to assign semantic labels to every pixel of an image. Unbalanced semantic label distribution could have a negative influence on segmentation accuracy. In this paper, we investigate using data augmentation approach to balance the label distribution in order to improve segmentation performance. We propose using generative adversarial networks (GANs) to generate realistic images for improving the performance of semantic segmentation networks. Experimental results show that the proposed method can not only improve segmentation accuracy of those classes with low accuracy, but also obtain 1.3% to 2.1% increase in average segmentation accuracy. It proves that this augmentation method can boost the accuracy and be easily applicable to any other segmentation models.
Generative Cooperative Net for Image Generation and Data Augmentation
Feb 08, 2018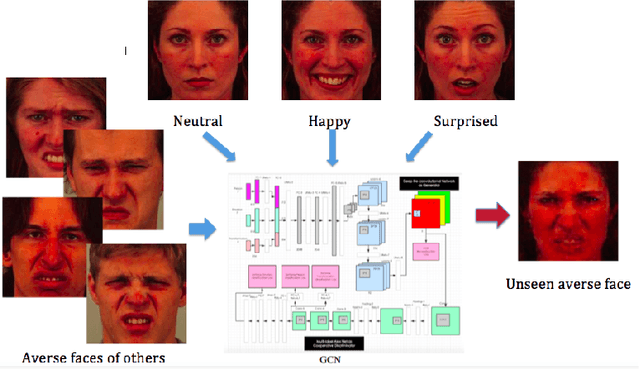
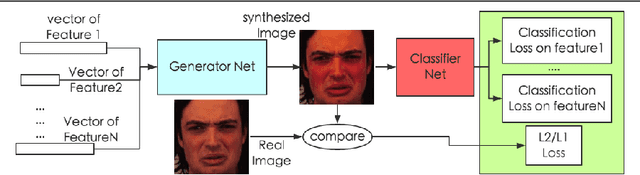
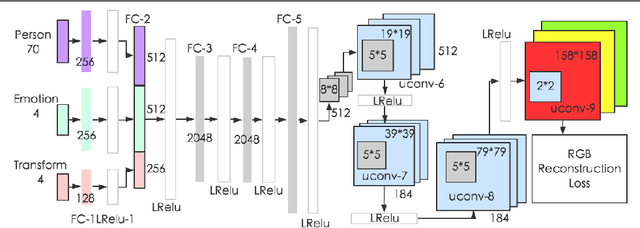
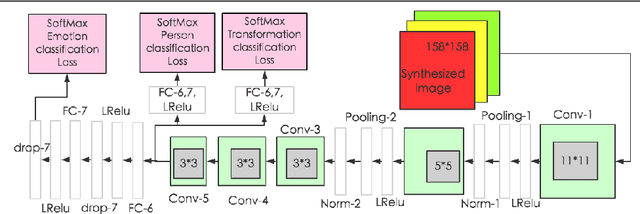
How to build a good model for image generation given an abstract concept is a fundamental problem in computer vision. In this paper, we explore a generative model for the task of generating unseen images with desired features. We propose the Generative Cooperative Net (GCN) for image generation. The idea is similar to generative adversarial networks except that the generators and discriminators are trained to work accordingly. Our experiments on hand-written digit generation and facial expression generation show that GCN's two cooperative counterparts (the generator and the classifier) can work together nicely and achieve promising results. We also discovered a usage of such generative model as an data-augmentation tool. Our experiment of applying this method on a recognition task shows that it is very effective comparing to other existing methods. It is easy to set up and could help generate a very large synthesized dataset.
Text Generation Based on Generative Adversarial Nets with Latent Variable
Dec 01, 2017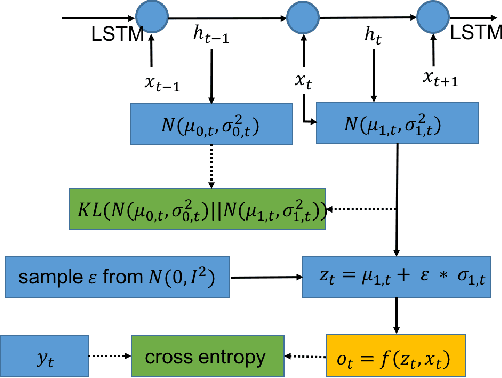


In this paper, we propose a model using generative adversarial net (GAN) to generate realistic text. Instead of using standard GAN, we combine variational autoencoder (VAE) with generative adversarial net. The use of high-level latent random variables is helpful to learn the data distribution and solve the problem that generative adversarial net always emits the similar data. We propose the VGAN model where the generative model is composed of recurrent neural network and VAE. The discriminative model is a convolutional neural network. We train the model via policy gradient. We apply the proposed model to the task of text generation and compare it to other recent neural network based models, such as recurrent neural network language model and SeqGAN. We evaluate the performance of the model by calculating negative log-likelihood and the BLEU score. We conduct experiments on three benchmark datasets, and results show that our model outperforms other previous models.
Logical Parsing from Natural Language Based on a Neural Translation Model
May 09, 2017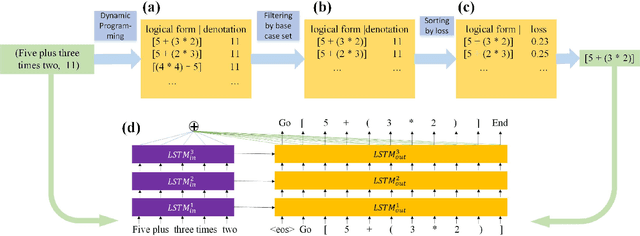



Semantic parsing has emerged as a significant and powerful paradigm for natural language interface and question answering systems. Traditional methods of building a semantic parser rely on high-quality lexicons, hand-crafted grammars and linguistic features which are limited by applied domain or representation. In this paper, we propose a general approach to learn from denotations based on Seq2Seq model augmented with attention mechanism. We encode input sequence into vectors and use dynamic programming to infer candidate logical forms. We utilize the fact that similar utterances should have similar logical forms to help reduce the searching space. Under our learning policy, the Seq2Seq model can learn mappings gradually with noises. Curriculum learning is adopted to make the learning smoother. We test our method on the arithmetic domain which shows our model can successfully infer the correct logical forms and learn the word meanings, compositionality and operation orders simultaneously.