 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSID-Coord: Coordinating Semantic IDs for ID-based Ranking in Short-Video Search
Apr 12, 2026Large-scale short-video search ranking models are typically trained on sparse co-occurrence signals over hashed item identifiers (HIDs). While effective at memorizing frequent interactions, such ID-based models struggle to generalize to long-tailed items with limited exposure. This memorization-generalization trade-off remains a longstanding challenge in such industrial systems. We propose SID-Coord, a lightweight Semantic ID framework that incorporates discrete, trainable semantic IDs (SIDs) directly into ID-based ranking models. Instead of treating semantic signals as auxiliary dense features, SID-Coord represents semantics as structured identifiers and coordinates HID-based memorization with SID-based generalization within a unified modeling framework. To enable effective coordination, SID-Coord introduces three components: (1) an attention-based fusion module over hierarchical SIDs to capture multi-level semantics, (2) a target-aware HID-SID gating mechanism that adaptively balances memorization and generalization, and (3) a SID-driven interest alignment module that models the semantic similarity distribution between target items and user histories. SID-Coord can be integrated into existing production ranking systems without modifying the backbone model. Online A/B experiments in a real-world production environment show statistically significant improvements, with a +0.664% gain in long-play rate in search and a +0.369% increase in search playback duration.
CroPS: Improving Dense Retrieval with Cross-Perspective Positive Samples in Short-Video Search
Nov 19, 2025Dense retrieval has become a foundational paradigm in modern search systems, especially on short-video platforms. However, most industrial systems adopt a self-reinforcing training pipeline that relies on historically exposed user interactions for supervision. This paradigm inevitably leads to a filter bubble effect, where potentially relevant but previously unseen content is excluded from the training signal, biasing the model toward narrow and conservative retrieval. In this paper, we present CroPS (Cross-Perspective Positive Samples), a novel retrieval data engine designed to alleviate this problem by introducing diverse and semantically meaningful positive examples from multiple perspectives. CroPS enhances training with positive signals derived from user query reformulation behavior (query-level), engagement data in recommendation streams (system-level), and world knowledge synthesized by large language models (knowledge-level). To effectively utilize these heterogeneous signals, we introduce a Hierarchical Label Assignment (HLA) strategy and a corresponding H-InfoNCE loss that together enable fine-grained, relevance-aware optimization. Extensive experiments conducted on Kuaishou Search, a large-scale commercial short-video search platform, demonstrate that CroPS significantly outperforms strong baselines both offline and in live A/B tests, achieving superior retrieval performance and reducing query reformulation rates. CroPS is now fully deployed in Kuaishou Search, serving hundreds of millions of users daily.
UniSearch: Rethinking Search System with a Unified Generative Architecture
Sep 10, 2025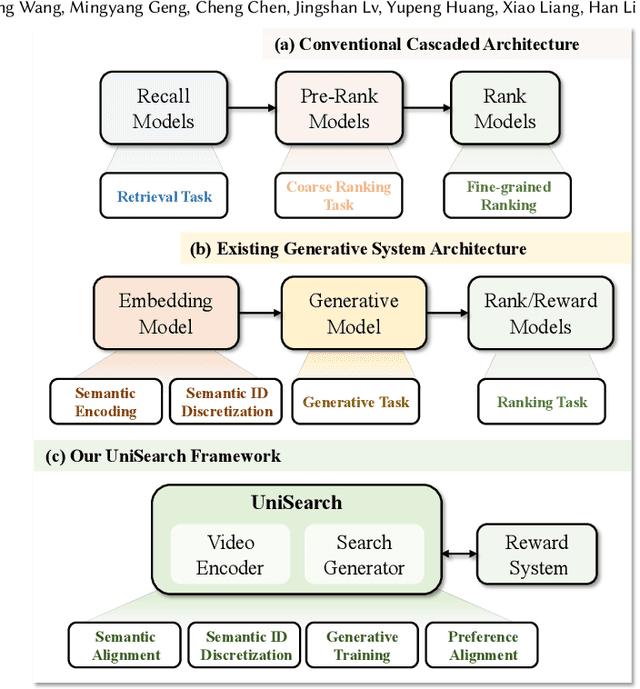
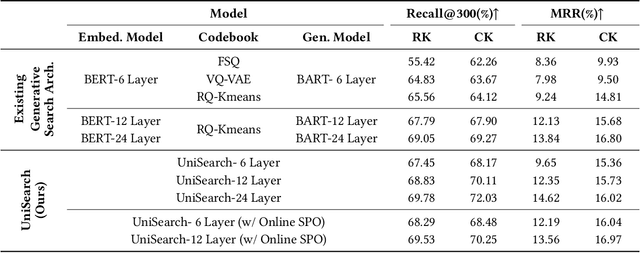
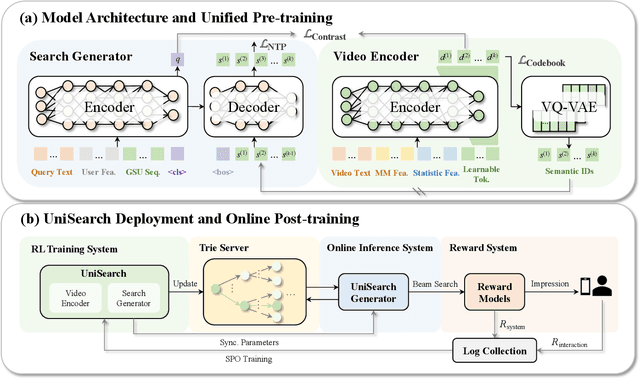
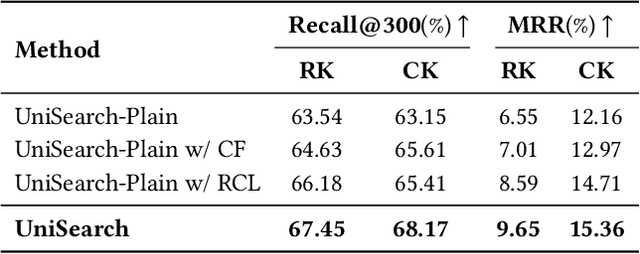
Modern search systems play a crucial role in facilitating information acquisition. Traditional search engines typically rely on a cascaded architecture, where results are retrieved through recall, pre-ranking, and ranking stages. The complexity of designing and maintaining multiple modules makes it difficult to achieve holistic performance gains. Recent advances in generative recommendation have motivated the exploration of unified generative search as an alternative. However, existing approaches are not genuinely end-to-end: they typically train an item encoder to tokenize candidates first and then optimize a generator separately, leading to objective inconsistency and limited generalization. To address these limitations, we propose UniSearch, a unified generative search framework for Kuaishou Search. UniSearch replaces the cascaded pipeline with an end-to-end architecture that integrates a Search Generator and a Video Encoder. The Generator produces semantic identifiers of relevant items given a user query, while the Video Encoder learns latent item embeddings and provides their tokenized representations. A unified training framework jointly optimizes both components, enabling mutual enhancement and improving representation quality and generation accuracy. Furthermore, we introduce Search Preference Optimization (SPO), which leverages a reward model and real user feedback to better align generation with user preferences. Extensive experiments on industrial-scale datasets, together with online A/B testing in both short-video and live search scenarios, demonstrate the strong effectiveness and deployment potential of UniSearch. Notably, its deployment in live search yields the largest single-experiment improvement in recent years of our product's history, highlighting its practical value for real-world applications.
Personalized Query Auto-Completion for Long and Short-Term Interests with Adaptive Detoxification Generation
May 27, 2025Query auto-completion (QAC) plays a crucial role in modern search systems. However, in real-world applications, there are two pressing challenges that still need to be addressed. First, there is a need for hierarchical personalized representations for users. Previous approaches have typically used users' search behavior as a single, overall representation, which proves inadequate in more nuanced generative scenarios. Additionally, query prefixes are typically short and may contain typos or sensitive information, increasing the likelihood of generating toxic content compared to traditional text generation tasks. Such toxic content can degrade user experience and lead to public relations issues. Therefore, the second critical challenge is detoxifying QAC systems. To address these two limitations, we propose a novel model (LaD) that captures personalized information from both long-term and short-term interests, incorporating adaptive detoxification. In LaD, personalized information is captured hierarchically at both coarse-grained and fine-grained levels. This approach preserves as much personalized information as possible while enabling online generation within time constraints. To move a futher step, we propose an online training method based on Reject Preference Optimization (RPO). By incorporating a special token [Reject] during both the training and inference processes, the model achieves adaptive detoxification. Consequently, the generated text presented to users is both non-toxic and relevant to the given prefix. We conduct comprehensive experiments on industrial-scale datasets and perform online A/B tests, delivering the largest single-experiment metric improvement in nearly two years of our product. Our model has been deployed on Kuaishou search, driving the primary traffic for hundreds of millions of active users. The code is available at https://github.com/JXZe/LaD.
Reasoning with Multi-Structure Commonsense Knowledge in Visual Dialog
Apr 10, 2022
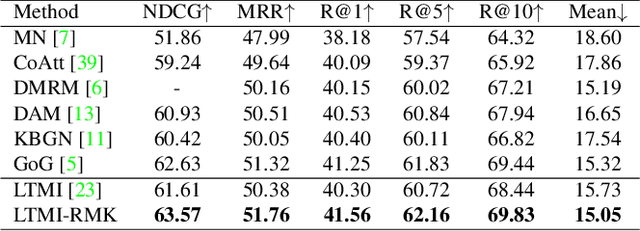
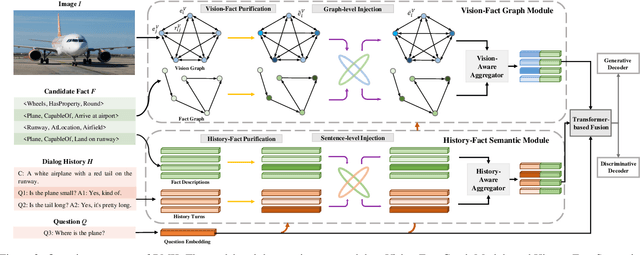
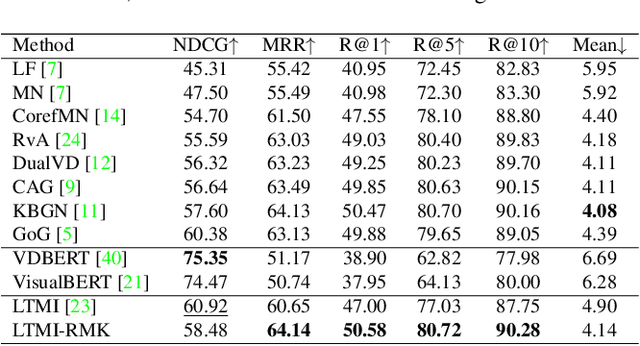
Visual Dialog requires an agent to engage in a conversation with humans grounded in an image. Many studies on Visual Dialog focus on the understanding of the dialog history or the content of an image, while a considerable amount of commonsense-required questions are ignored. Handling these scenarios depends on logical reasoning that requires commonsense priors. How to capture relevant commonsense knowledge complementary to the history and the image remains a key challenge. In this paper, we propose a novel model by Reasoning with Multi-structure Commonsense Knowledge (RMK). In our model, the external knowledge is represented with sentence-level facts and graph-level facts, to properly suit the scenario of the composite of dialog history and image. On top of these multi-structure representations, our model can capture relevant knowledge and incorporate them into the vision and semantic features, via graph-based interaction and transformer-based fusion. Experimental results and analysis on VisDial v1.0 and VisDialCK datasets show that our proposed model effectively outperforms comparative methods.
XLM-K: Improving Cross-Lingual Language Model Pre-Training with Multilingual Knowledge
Sep 26, 2021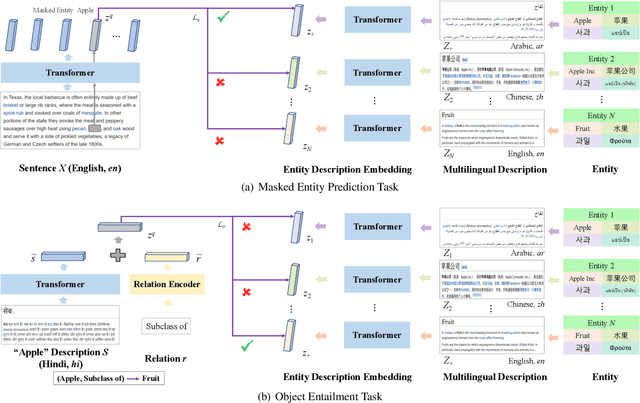
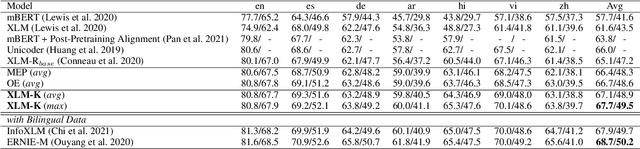
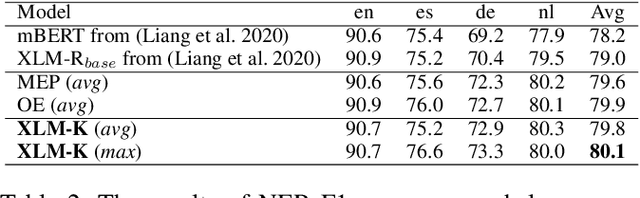

Cross-lingual pre-training has achieved great successes using monolingual and bilingual plain text corpora. However, existing pre-trained models neglect multilingual knowledge, which is language agnostic but comprises abundant cross-lingual structure alignment. In this paper, we propose XLM-K, a cross-lingual language model incorporating multilingual knowledge in pre-training. XLM-K augments existing multilingual pre-training with two knowledge tasks, namely Masked Entity Prediction Task and Object Entailment Task. We evaluate XLM-K on MLQA, NER and XNLI. Experimental results clearly demonstrate significant improvements over existing multilingual language models. The results on MLQA and NER exhibit the superiority of XLM-K in knowledge related tasks. The success in XNLI shows a better cross-lingual transferability obtained in XLM-K. What is more, we provide a detailed probing analysis to confirm the desired knowledge captured in our pre-training regimen.
KBGN: Knowledge-Bridge Graph Network for Adaptive Vision-Text Reasoning in Visual Dialogue
Aug 28, 2020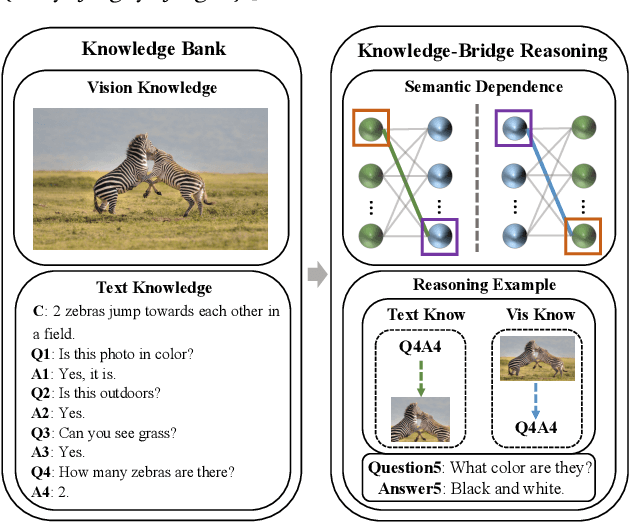
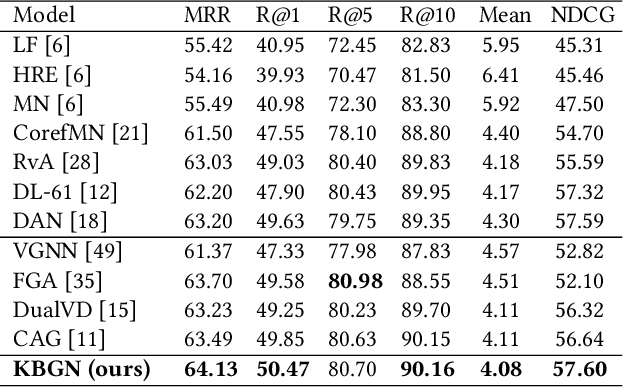

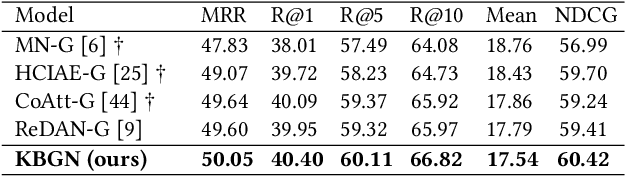
Visual dialogue is a challenging task that needs to extract implicit information from both visual (image) and textual (dialogue history) contexts. Classical approaches pay more attention to the integration of the current question, vision knowledge and text knowledge, despising the heterogeneous semantic gaps between the cross-modal information. In the meantime, the concatenation operation has become de-facto standard to the cross-modal information fusion, which has a limited ability in information retrieval. In this paper, we propose a novel Knowledge-Bridge Graph Network (KBGN) model by using graph to bridge the cross-modal semantic relations between vision and text knowledge in fine granularity, as well as retrieving required knowledge via an adaptive information selection mode. Moreover, the reasoning clues for visual dialogue can be clearly drawn from intra-modal entities and inter-modal bridges. Experimental results on VisDial v1.0 and VisDial-Q datasets demonstrate that our model outperforms existing models with state-of-the-art results.
DAM: Deliberation, Abandon and Memory Networks for Generating Detailed and Non-repetitive Responses in Visual Dialogue
Jul 07, 2020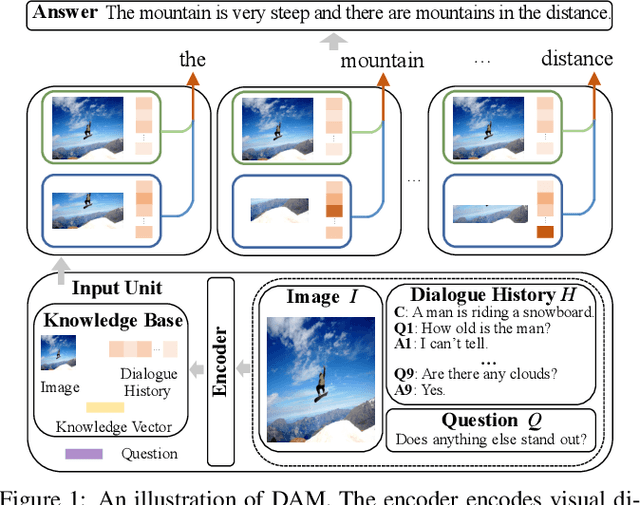
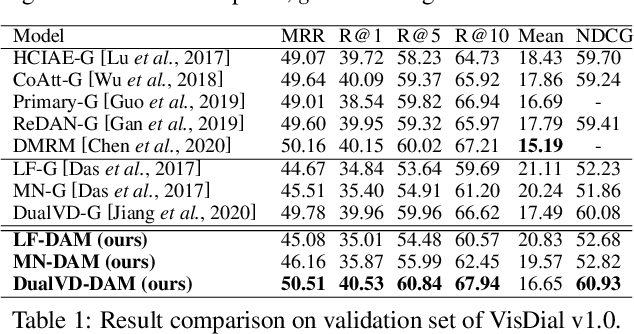
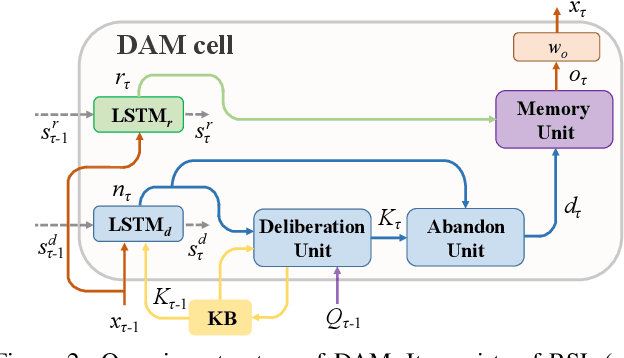

Visual Dialogue task requires an agent to be engaged in a conversation with human about an image. The ability of generating detailed and non-repetitive responses is crucial for the agent to achieve human-like conversation. In this paper, we propose a novel generative decoding architecture to generate high-quality responses, which moves away from decoding the whole encoded semantics towards the design that advocates both transparency and flexibility. In this architecture, word generation is decomposed into a series of attention-based information selection steps, performed by the novel recurrent Deliberation, Abandon and Memory (DAM) module. Each DAM module performs an adaptive combination of the response-level semantics captured from the encoder and the word-level semantics specifically selected for generating each word. Therefore, the responses contain more detailed and non-repetitive descriptions while maintaining the semantic accuracy. Furthermore, DAM is flexible to cooperate with existing visual dialogue encoders and adaptive to the encoder structures by constraining the information selection mode in DAM. We apply DAM to three typical encoders and verify the performance on the VisDial v1.0 dataset. Experimental results show that the proposed models achieve new state-of-the-art performance with high-quality responses. The code is available at https://github.com/JXZe/DAM.
DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue
Nov 17, 2019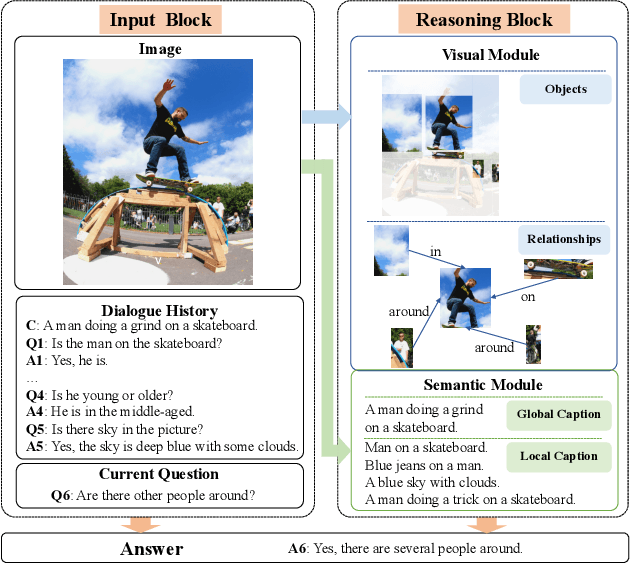

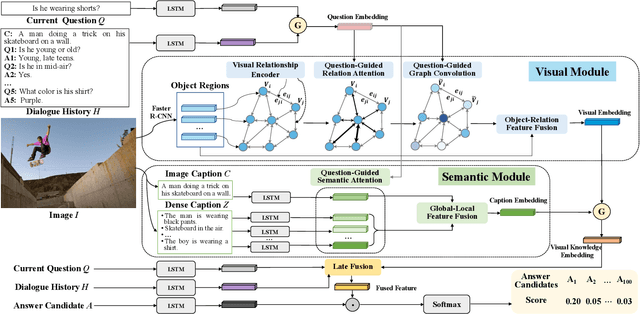

Different from Visual Question Answering task that requires to answer only one question about an image, Visual Dialogue involves multiple questions which cover a broad range of visual content that could be related to any objects, relationships or semantics. The key challenge in Visual Dialogue task is thus to learn a more comprehensive and semantic-rich image representation which may have adaptive attentions on the image for variant questions. In this research, we propose a novel model to depict an image from both visual and semantic perspectives. Specifically, the visual view helps capture the appearance-level information, including objects and their relationships, while the semantic view enables the agent to understand high-level visual semantics from the whole image to the local regions. Futhermore, on top of such multi-view image features, we propose a feature selection framework which is able to adaptively capture question-relevant information hierarchically in fine-grained level. The proposed method achieved state-of-the-art results on benchmark Visual Dialogue datasets. More importantly, we can tell which modality (visual or semantic) has more contribution in answering the current question by visualizing the gate values. It gives us insights in understanding of human cognition in Visual Dialogue.