 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Foundation Model-Driven User Interest Modeling and Behavior Analysis on Short Video Platforms
Sep 05, 2025With the rapid expansion of user bases on short video platforms, personalized recommendation systems are playing an increasingly critical role in enhancing user experience and optimizing content distribution. Traditional interest modeling methods often rely on unimodal data, such as click logs or text labels, which limits their ability to fully capture user preferences in a complex multimodal content environment. To address this challenge, this paper proposes a multimodal foundation model-based framework for user interest modeling and behavior analysis. By integrating video frames, textual descriptions, and background music into a unified semantic space using cross-modal alignment strategies, the framework constructs fine-grained user interest vectors. Additionally, we introduce a behavior-driven feature embedding mechanism that incorporates viewing, liking, and commenting sequences to model dynamic interest evolution, thereby improving both the timeliness and accuracy of recommendations. In the experimental phase, we conduct extensive evaluations using both public and proprietary short video datasets, comparing our approach against multiple mainstream recommendation algorithms and modeling techniques. Results demonstrate significant improvements in behavior prediction accuracy, interest modeling for cold-start users, and recommendation click-through rates. Moreover, we incorporate interpretability mechanisms using attention weights and feature visualization to reveal the model's decision basis under multimodal inputs and trace interest shifts, thereby enhancing the transparency and controllability of the recommendation system.
When Thinking Fails: The Pitfalls of Reasoning for Instruction-Following in LLMs
May 16, 2025Reasoning-enhanced large language models (RLLMs), whether explicitly trained for reasoning or prompted via chain-of-thought (CoT), have achieved state-of-the-art performance on many complex reasoning tasks. However, we uncover a surprising and previously overlooked phenomenon: explicit CoT reasoning can significantly degrade instruction-following accuracy. Evaluating 15 models on two benchmarks: IFEval (with simple, rule-verifiable constraints) and ComplexBench (with complex, compositional constraints), we consistently observe performance drops when CoT prompting is applied. Through large-scale case studies and an attention-based analysis, we identify common patterns where reasoning either helps (e.g., with formatting or lexical precision) or hurts (e.g., by neglecting simple constraints or introducing unnecessary content). We propose a metric, constraint attention, to quantify model focus during generation and show that CoT reasoning often diverts attention away from instruction-relevant tokens. To mitigate these effects, we introduce and evaluate four strategies: in-context learning, self-reflection, self-selective reasoning, and classifier-selective reasoning. Our results demonstrate that selective reasoning strategies, particularly classifier-selective reasoning, can substantially recover lost performance. To our knowledge, this is the first work to systematically expose reasoning-induced failures in instruction-following and offer practical mitigation strategies.
Semantic Volume: Quantifying and Detecting both External and Internal Uncertainty in LLMs
Feb 28, 2025Large language models (LLMs) have demonstrated remarkable performance across diverse tasks by encoding vast amounts of factual knowledge. However, they are still prone to hallucinations, generating incorrect or misleading information, often accompanied by high uncertainty. Existing methods for hallucination detection primarily focus on quantifying internal uncertainty, which arises from missing or conflicting knowledge within the model. However, hallucinations can also stem from external uncertainty, where ambiguous user queries lead to multiple possible interpretations. In this work, we introduce Semantic Volume, a novel mathematical measure for quantifying both external and internal uncertainty in LLMs. Our approach perturbs queries and responses, embeds them in a semantic space, and computes the determinant of the Gram matrix of the embedding vectors, capturing their dispersion as a measure of uncertainty. Our framework provides a generalizable and unsupervised uncertainty detection method without requiring white-box access to LLMs. We conduct extensive experiments on both external and internal uncertainty detection, demonstrating that our Semantic Volume method consistently outperforms existing baselines in both tasks. Additionally, we provide theoretical insights linking our measure to differential entropy, unifying and extending previous sampling-based uncertainty measures such as the semantic entropy. Semantic Volume is shown to be a robust and interpretable approach to improving the reliability of LLMs by systematically detecting uncertainty in both user queries and model responses.
DualVD: An Adaptive Dual Encoding Model for Deep Visual Understanding in Visual Dialogue
Nov 17, 2019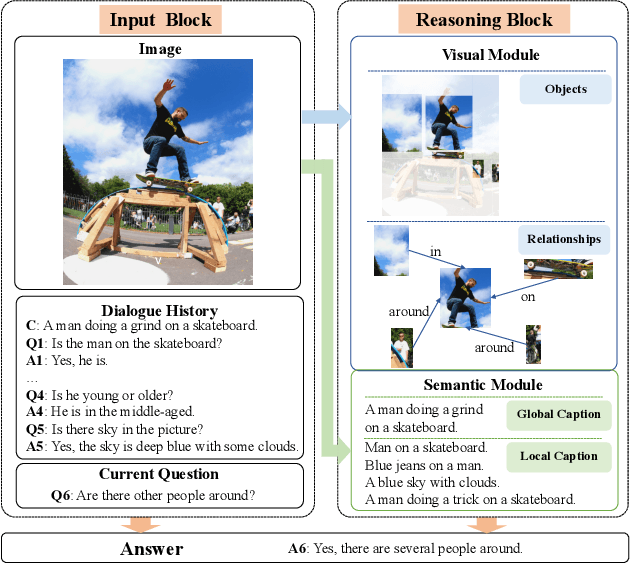

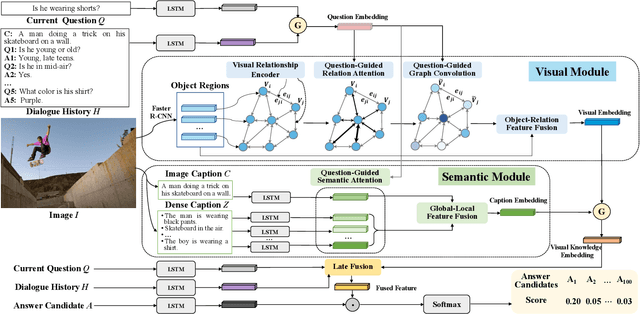

Different from Visual Question Answering task that requires to answer only one question about an image, Visual Dialogue involves multiple questions which cover a broad range of visual content that could be related to any objects, relationships or semantics. The key challenge in Visual Dialogue task is thus to learn a more comprehensive and semantic-rich image representation which may have adaptive attentions on the image for variant questions. In this research, we propose a novel model to depict an image from both visual and semantic perspectives. Specifically, the visual view helps capture the appearance-level information, including objects and their relationships, while the semantic view enables the agent to understand high-level visual semantics from the whole image to the local regions. Futhermore, on top of such multi-view image features, we propose a feature selection framework which is able to adaptively capture question-relevant information hierarchically in fine-grained level. The proposed method achieved state-of-the-art results on benchmark Visual Dialogue datasets. More importantly, we can tell which modality (visual or semantic) has more contribution in answering the current question by visualizing the gate values. It gives us insights in understanding of human cognition in Visual Dialogue.